标签:
1、list
L = [‘a‘,‘a‘,‘a‘,‘a‘,‘a‘,‘a3‘]
L[0] = a
L[-1] = a3
添加新元素
L.append(‘paul‘)
L.insert(-1,‘Paul‘)
删除元素
L.pop(2)
list 里面元素不要求必须是同一种数据类型
L.remove(‘Paul‘)
2、tuple (元组),tuple 一旦创建即不能修改;
t = (‘a‘,2,‘awefawe‘,4)
t[0] = a
print t
t = (1)
因为()既可以表示tuple,又可以作为括号表示运算时的优先级,结果 (1) 被Python解释器计算出结果 1,导致我们得到的不是tuple,而是整数 1。
改为 t = (1,)
t = (‘Aldm‘,)
3、可变的 tuple (加入list)
t = (‘a‘,‘b‘,[‘A‘,‘B‘])
4、if 语句 代码缩进
注意: Python代码的缩进规则。具有相同缩进的代码被视为代码块,上面的3,4行 print 语句就构成一个代码块(但不包括第5行的print)。如果 if 语句判断为 True,就会执行这个代码块。
缩进请严格按照Python的习惯写法:4个空格,不要使用Tab,更不要混合Tab和空格,否则很容易造成因为缩进引起的语法错误。
注意: if 语句后接表达式,然后用:表示代码块开始。【!!!!!!!!!!!】
如果你在Python交互环境下敲代码,还要特别留意缩进,并且退出缩进需要多敲一行回车
5、if-else
if-elif-else
#-*- coding:utf-8 -*-
score = 78
if score >= 90
print(‘excellent‘)
elif score >= 80
print(‘good‘)
elif score >= 60
print(‘pass‘)
else
print(‘failed‘)
6、for 循环
L = [‘Adam‘,‘Lisa‘,‘Bart‘] #L = (‘Adam‘,‘Lisa‘,‘Bart‘)
for name in L :
print name
7、while 循环
N = 10
x = 0
while x < N:
print x
x += 1
8、break 退出循环
sum = 0
x = 1
while true:
sum += x
x += 1
if x > 100:
break
print sum
9、continue 继续循环
for x in L: # 统计合格分数的平均分
if x < 60:
continue
sum += x
n +=1
10、嵌套循环
#-*- coding:utf-8 -*-
for x in [1,2,3,4,5,6,7,8,9]: # 十位数字
for y in [0,1,2,3,4,5,6,7,8,9]: # 个位数字
if x < y:
print(x*10+y) #十位数字乘以10加上个位
11、dict 字典
key:value 对
#-*- coding:utf-8 -*-
d = {
# 定义一个 dict
‘Adam‘:95,
‘Lisa‘:85,
‘Bart‘:59,
‘Paul‘:75
}
print(len(d))
# 输出dict 集合的大小
访问 dict: d[key] = d[‘Adam‘] >>> 95;
print(d.get(‘Adam‘))
dict / list 的特点:
(1) 查找速度快,无论dict有10个元素还是10万个元素,查找速度都一样。而list的查找速度随着元素增加而逐渐下降
dict的缺点是占用内存大,还会浪费很多内容,list正好相反,占用内存小,但是查找速度慢。
(2)dict的第二个特点就是存储的key-value序对是没有顺序的!
print d 的结果不一定是创建的顺序,每台机器运行的结果也可能不一样;
(3)dict的第三个特点是作为 key 的元素必须不可变,Python的基本类型如字符串、整数、浮点数都是不可变的,都可以作为 key。但是list是可变的,就不能作为 key。
更新 dict 添加元素到 dict 中
d = {
95: ‘Adam‘,
85: ‘Lisa‘,
59: ‘Bart‘
}
d[72] = ‘Paul‘
遍历 dict
#-*- coding:utf-8 -*-
d = {
‘Adam‘: 95,
‘Lisa‘: 85,
‘Bart‘: 59
}
for key in d:
#print(key+‘:‘)+str(d.get(key))
print key,‘:‘,d[key]
12、set 持有一系列元素,与list很想,但是 set 元素没有重复,而且是无序的,这点与 dict 的 key 很像;
创建 set 的方式是调用 set() 并传入一个 List , list 的元素将作为 set 的元素
s = set([‘A‘,‘B‘,‘C‘])
判断元素是否存在于 set 中
#-*- coding:utf-8 -*-
s = set([‘adam‘,‘bart‘,‘Paul‘])
print ‘adam‘ in s
print ‘bart‘ in s
删除元素 s.remove(element)
添加元素 s.add(element)
#-*- coding:utf-8 -*-
s = set([‘Adam‘, ‘Lisa‘, ‘Paul‘])
L = [‘Adam‘, ‘Lisa‘, ‘Bart‘, ‘Paul‘]
for element in L:
if element in s:
s.remove(element)
else:
s.add(element)
print s
13、递归函数
汉诺塔问题
def move(n, a, b, c):
if n == 1:
print a,‘ --> ‘,c
return
#print a,‘ --> ‘,b
move(n-1,a,c,b)
move(1,a,b,c)
move(n-1,b,a,c)
move(4,‘A‘, ‘B‘, ‘C‘)
#move(19,‘A‘, ‘B‘, ‘C‘)
1、只有一个 A --> C
2、最底层上面的移到 B,最底的移到 C
B -- C
14、定义默认参数/可变参数
def func_name(par = ‘default_par‘):
func_body
# 定义可变参数
def func_name(*args):
func_body
func_name()
func_name(2,1,2)
15、对 list / tuple进行切片 slice
L = [ ... ]
L[0:3]
L[:3]
L[:] 从头到尾
设置第三个参数
L[::2] # 表示每 2 个取一个
L[-3:-1]
利用倒序切片对 1 - 100 的数列取出:
* 最后10个数;
* 最后10个5的倍数。
L = range(1, 101)
print L[-10:]
print L[-46::5]
【Note:字符串 u‘xxx‘ Unicode字符串】
字符串切片类似
def firstCharUpper(s):
return s[:1].upper()+s[1:]
print firstCharUpper(‘hello‘)
print firstCharUpper(‘sunday‘)
print firstCharUpper(‘september‘)
16、在Python 中,如果给定一个 list 或 tuple,我们可以通过 for 循环来遍历这个 List 或 tuple,这种遍历称为 迭代(Iteration)
for name in L:
print name
17、索引迭代
enumerate() 函数
迭代的一个元素实际上是一个 tuple
L = [‘Adam‘, ‘Lisa‘, ‘Bart‘, ‘Paul‘]
for index, name in enumerate(L):
print index, ‘-‘, name
# 两段代码相等
for t in enumerate(L):
index = t[0]
name = t[1]
print index, ‘-‘, name
L = [‘Adam‘, ‘Lisa‘, ‘Bart‘, ‘Paul‘]
for t in enumerate(zip(range(1,5),L)):
print t[1][0],‘-‘,t[1][1]
18、dict 对象的 values() 方法,把 dict 转换成一个包含所有 value 的list
itervalues() 方法替代 values() 方法,迭代效果完全一样;
20、items() 迭代 dict 的 key 和 value
items() 方法把 dict 对象转换成了包含 tuple 的list ,我们队这个 list 进行迭代,可以同时获得 key 和 value
相似函数: iteritems(),iteritems() 不把 dict 转换成 list ,而是在迭代过程中不断给出 tuple , 所以,iteritems() 不占额外的内存
21、生成列表
等效
print [index*(index + 1) for index in range(1,100,2)]
# 生成列表 [1x2, 3x4, 5x6, 7x8, ..., 99x100]
22、条件过滤
例子:list 中字符串转换为大写形式
isinstance(x,str)
23、嵌套循环
进阶
1、 函数式编程的特点
· 把计算机视为函数而非指令
· 纯函数式编程:不需要变量,没有副作用,测试简单
· 支持高阶函数,代码简洁
2、高阶函数
能够接收函数做参数的函数
# 定义函数接收 xy,f 三个函数
# 变量命名不能用数字命名
def add(a,c,f):
return f(a)+f(c)
print(add(-1,-24,abs))
3、map() 函数是Python 中内置的高阶函数,它接收一个函数 f 和一个 list 并通过把函数 f 一次作用在 list 的每个元素上,得到一个新的 list 并返回
4、reduce() 函数接收的参数为 一个函数 f ,一个 List,但行为和 map() 不同,reduce()传入的函数 f 必须接收两个参数,reduce() 对 list 的每个元素反复调用函数 f ,并返回最终结果值
两个参数时相当于 sum() 函数
三个参数时,作为计算的初始值, 100 + sum() # 100 为第三个参数,也就是初始值
5、filter() 函数接收的参数为 一个函数 f ,一个 List,这个函数 f 的作用是对每个元素进行判断,返回 True 或 False, filter() 根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新 list
6、自定义排序函数
sorted() 函数可对 list 进行排序,可接收一个比较函数来实现自定义排序,比较函数的定义:
x 应该在 y 前面,返回 -1
x 应该在 y 后面,返回 1
x 和 y 相等,返回 0
默认以 ASII码排序
Note:函数参数,第二个参数为函数名
return cmp(s1.lower(),s2.lower())
cmp = lambda x,y : cmp(x.upper(), y.upper())
7、返回函数
def f():
print ‘call f() ...‘
# 定义函数 g:
def g():
print ‘call g() ...‘
# 返回函数 g
return g # 注意:只是返回函数名,无调用
8、引用了外层函数的变量(参数也算变量),然后返回内层函数的情况,称为闭包(Closure)
闭包的特点是返回的函数还引用了外层函数的局部变量,所以,要正确使用闭包,就要确保引用的局部变量在函数返回后不能变;
9、匿名函数
Python 中对匿名函数提供了有限支持;关键字 lambda 表示匿名函数,冒号签名的 x 表示函数参数
map(lambda x: x**2, [1,2,3,4,5,6,7,8,9])
map(lambda x: x**2, range(1,10))
匿名函数 labmbda x : x * x 实际上就是
def f(x):
return x * x
Note: 匿名函数有个限制,就是只能有一个表达式,不写 return ,返回值就是该表达式的结果;
strip(rm) 函数注释
10、Python 装饰器 @decrator
带参数的装饰器
11、偏函数
int(‘123456‘,base = 8) # base 参数默认为 10
def int2(x, base = 2)
return int(x, base)
Note: functools.partial 可以把一个参数多的函数编程一个参数少的函数,少的参数需要在创建时指定默认值
import functools
int2 = functools.partial(int, base = 2)
int2(‘1000000‘)
12、导入模块
from math import pow, sin, log
# 单独导入三个函数
使用别名避免函数名冲突
from math import pow, sin, log
from logging import log as logger # logger 就是 log 的别名
13、动态导入模块
try :
from cStringIO import StringIO
except ImportError:
from StringIO import StringIO
# 先尝试从 cStringIO 导入,如果失败了(比如 cStringIO 没有被安装),再尝试从 StringIO 导入。
try 的作用是捕获错误,并在捕获到制定错误时执行 except 语句
14、future
第四章 面向对象编程
1、 面向对象编程的基本思想
类和实例
2、类的属性限制
如果一个属性由双下划线开头,该属性就无法被外部访问。
class Person(object):
def __init__(self, name)
self.name = name
self.title = ‘Mr‘
self.__job = ‘Student‘
print p.__job # 提示 has no attribute
3、类属性
4、定义实例方法 self @classmethod
5、继承 super
6、判断类型
isinstance() 判断一个变量的类型,包括Python 内置的数据类型 str、list 、dict 等,也可以用在自定义的类。
7、多态
类具有继承关系,并且子类类型可以向上转型看做父类类型,如果我们从 Person 派生出 Student和Teacher ,并都写了一个 whoAmI() 方法:
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
def whoAmI(self):
return ‘I am a Person, my name is %s‘ % self.name
class Student(Person):
def __init__(self, name, gender, score):
super(Student, self).__init__(name, gender)
self.score = score
def whoAmI(self):
return ‘I am a Student, my name is %s‘ % self.name
class Teacher(Person):
def __init__(self, name, gender, course):
super(Teacher, self).__init__(name, gender)
self.course = course
def whoAmI(self):
return ‘I am a Teacher, my name is %s‘ % self.name
在一个函数中,如果我们接收一个变量 x,则无论该 x 是 Person、Student还是 Teacher,都可以正确打印出结果:
def who_am_i(x):
print x.whoAmI()
p = Person(‘Tim‘, ‘Male‘)
s = Student(‘Bob‘, ‘Male‘, 88)
t = Teacher(‘Alice‘, ‘Female‘, ‘English‘)
who_am_i(p)
who_am_i(s)
who_am_i(t)
运行结果:
I am a Person, my name is Tim
I am a Student, my name is Bob
I am a Teacher, my name is Alice
这种行为称为多态。也就是说,方法调用将作用在 x 的实际类型上。 s 是 Student 类型,它实际上拥有自己的 whoAmI() 方法以及从 Person 继承的 whoAmI() 方法,但调用 s.whoAmI() 总是先查找它自身的定义,如果没有定义,则顺着继承链向上查找,直到在某个父类中找到为止;
由于Python是动态语言,所以,传递给函数 who_am_i(x)的参数 x 不一定是 Person 或 Person 的子类型。任何数据类型的实例都可以,只要它有一个whoAmI()的方法即可:
class Book(object):
def whoAmI(self):
return ‘I am a book‘
这是动态语言和静态语言(例如Java)最大的差别之一。动态语言调用实例方法,不检查类型,只要方法存在,参数正确,就可以调用。
8、多重继承
除了从一个父类继承外,Python允许从多个父类继承,称为多重继承。
多重继承的继承链就不是一棵树了,它像这样:
class A(object):
def __init__(self, a):
print ‘init A...‘
self.a = a
class B(A):
def __init__(self, a):
super(B, self).__init__(a)
print ‘init B...‘
class C(A):
def __init__(self, a):
super(C, self).__init__(a)
print ‘init C...‘
class D(B, C):
def __init__(self, a):
super(D, self).__init__(a)
print ‘init D...‘
看下图:
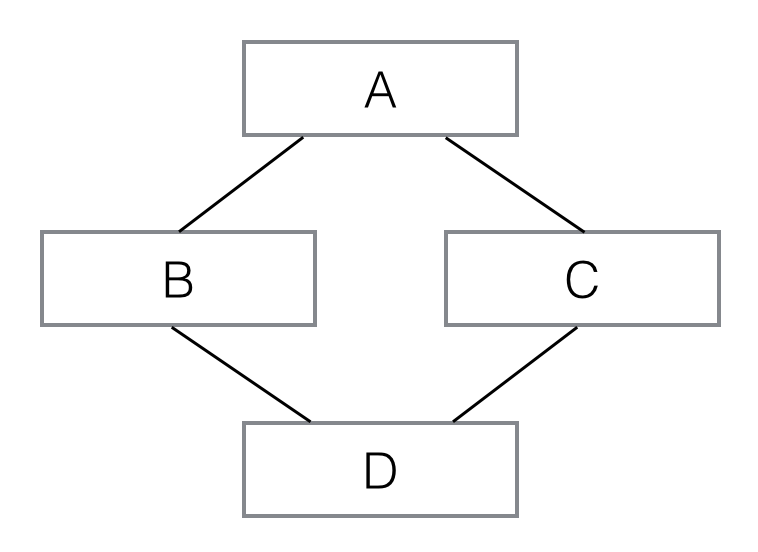
像这样,D 同时继承自 B 和 C,也就是 D 拥有了 A、B、C 的全部功能。多重继承通过 super()调用__init__()方法时,A虽然被继承了两次,但__init__()只调用一次:
9、获取对象信息
isinstance() : 判断对象数据类型
type() : 获取变量的类型,返回一个 type 对象
dir() : 获取变量的所有属性
dir()返回的属性是字符串列表,如果已知一个属性名称,要获取或者设置对象的属性,就需要用 getattr() 和 setattr( )函数了:
函数了:
>>> getattr(s, ‘name‘) # 获取name属性
‘Bob‘
>>> setattr(s, ‘name‘, ‘Adam‘) # 设置新的name属性
>>> s.name
‘Adam‘
>>> getattr(s, ‘age‘) # 获取age属性,但是属性不存在,报错:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: ‘Student‘ object has no attribute ‘age‘
>>> getattr(s, ‘age‘, 20) # 获取age属性,如果属性不存在,就返回默认值20:
20
10、__str__ 和 __repr__ 类的特殊方法
如果要把一个类的实例变成 str,就需要实现特殊方法__str__():
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
def __str__(self):
return ‘(Person: %s, %s)‘ % (self.name, self.gender)
现在,在交互式命令行下用 print 试试:
>>> p = Person(‘Bob‘, ‘male‘)
>>> print p
(Person: Bob, male)
但是,如果直接敲变量 p:
>>> p
<main.Person object at 0x10c941890>
似乎__str__() 不会被调用。
因为 Python 定义了__str__()和__repr__()两种方法,__str__()用于显示给用户,而__repr__()用于显示给开发人员。
有一个偷懒的定义__repr__的方法:
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
def __str__(self):
return ‘(Person: %s, %s)‘ % (self.name, self.gender)
__repr__ = __str__
11、__cmp__
class Person(object):
def __init__(self, name, gender, score):
self.name = name
self.gender = gender
self.score = score
def __str__(self, s):
return ‘(Person:%s,%s,%i)‘%(self.name, self.gender, self.score)
__repr__ = __str
def __cmp__(self, s):
return -cmp(self.score, s.score) or cmp(self.name.upper(), s.score.upper())
L = L = [Student(‘Tim‘, 99), Student(‘Bob‘, 88), Student(‘Alice‘, 99)]
print(sorted(L))
12、 __len__()
13、数学运算
求最大公约数
def gcd(a,b):
if b == 0:
return a
return gcd(b, a%b)
14、类型转换
如果要把 Rational 转为 int,应该使用:
r = Rational(12, 5)
n = int(r)
要让int()函数正常工作,只需要实现特殊方法__int__():
class Rational(object):
def __init__(self, p, q):
self.p = p
self.q = q
def __int__(self):
return self.p // self.q
结果如下:
>>> print int(Rational(7, 2))
3
>>> print int(Rational(1, 3))
0
同理,要让float()函数正常工作,只需要实现特殊方法__float__()。
15、@property
因为Python支持高阶函数,在函数式编程中我们介绍了装饰器函数,可以用装饰器函数把 get/set 方法“装饰”成属性调用:
class Student(object):
def __init__(self, name, score):
self.name = name
self.__score = score
@property
def score(self):
return self.__score
@score.setter
def score(self, score):
if score < 0 or score > 100:
raise ValueError(‘invalid score‘)
self.__score = score
注意: 第一个score(self)是get方法,用@property装饰,第二个score(self, score)是set方法,用@score.setter装饰,@score.setter是前一个@property装饰后的副产品。
现在,就可以像使用属性一样设置score了:
>>> s = Student(‘Bob‘, 59)
>>> s.score = 60
>>> print s.score
60
>>> s.score = 1000
Traceback (most recent call last):
...
ValueError: invalid score
说明对 score 赋值实际调用的是 set方法。
16、__slots__()
__slots__
由于Python是动态语言,任何实例在运行期都可以动态地添加属性。
如果要限制添加的属性,例如,Student类只允许添加 name、gender和score 这3个属性,就可以利用Python的一个特殊的__slots__来实现。
顾名思义,__slots__是指一个类允许的属性列表:
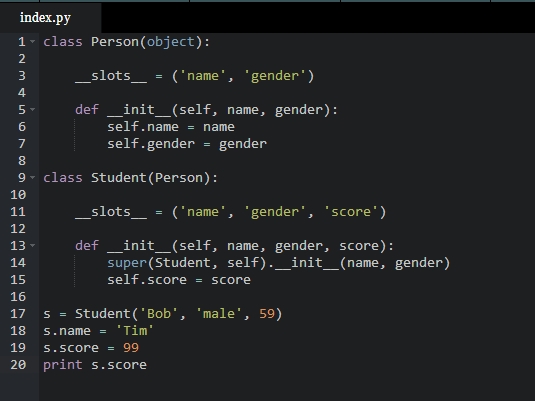
class Student(object):
__slots__ = (‘name‘, ‘gender‘, ‘score‘)
def __init__(self, name, gender, score):
self.name = name
self.gender = gender
self.score = score
现在,对实例进行操作:
>>> s = Student(‘Bob‘, ‘male‘, 59)
>>> s.name = ‘Tim‘ # OK
>>> s.score = 99 # OK
>>> s.grade = ‘A‘
Traceback (most recent call last):
...
AttributeError: ‘Student‘ object has no attribute ‘grade‘
__slots__的目的是限制当前类所能拥有的属性,如果不需要添加任意动态的属性,使用__slots__也能节省内存。
17、__call__
一个类实例也可以变成一个可调用对象,只需要实现一个特殊方法__call__()。
我们把 Person 类变成一个可调用对象:
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
def __call__(self, friend):
print ‘My name is %s...‘ % self.name
print ‘My friend is %s...‘ % friend
现在可以对 Person 实例直接调用:
>>> p = Person(‘Bob‘, ‘male‘)
>>> p(‘Tim‘)
My name is Bob...
My friend is Tim...
单看 p(‘Tim‘) 你无法确定 p 是一个函数还是一个类实例,所以,在Python中,函数也是对象,对象和函数的区别并不显著。
Python基础学习笔记FromImooc.com
标签:
原文地址:http://www.cnblogs.com/peiqianggao/p/4558410.html