map(), mapPartitions(), mapPartitionsWithIndex(), filter(), flatMap(), reduceByKey(), groupByKey()first(), take(), takeSample(), takeOrdered(), collect(), count(), countByValue(), reduce(), top()cache(), unpersist(), id(), setName()# This is a Python cell. You can run normal Python code here...
print ‘The sum of 1 and 1 is {0}‘.format(1+1)
The sum of 1 and 1 is 2
# Here is another Python cell, this time with a variable (x) declaration and an if statement:
x = 42
if x > 40:
print ‘The sum of 1 and 2 is {0}‘.format(1+2)
The sum of 1 and 2 is 3
# This cell relies on x being defined already.
# If we didn‘t run the cells from part (1a) this code would fail.
print x * 2
84
import statement will import the specified module. In this tutorial and future labs, we will provide any imports that are necessary.# Import the regular expression library
import re
m = re.search(‘(?<=abc)def‘, ‘abcdef‘)
m.group(0)
‘def‘
# Import the datetime library
import datetime
print ‘This was last run on: {0}‘.format(datetime.datetime.now())
This was last run on: 2015-06-07 12:27:13.767735
SparkContext. When running Spark, you start a new Spark application by creating a SparkContext. When the SparkContext is created, it asks the master for some cores to use to do work. The master sets these cores aside just for you; they won’t be used for other applications. When using Databricks Cloud or the virtual machine provisioned for this class, the SparkContext is created for you automatically as sc.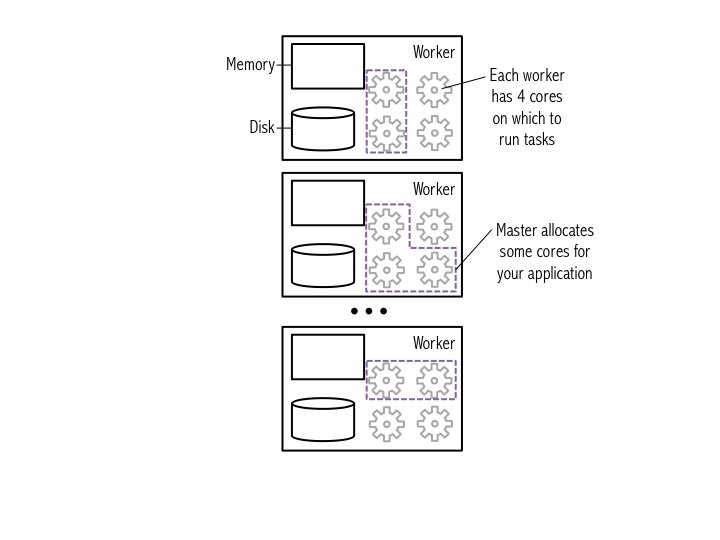
sc) is the main entry point for Spark functionality. A Spark context can be used to create Resilient Distributed Datasets (RDDs) on a cluster.sc to see its type.# Display the type of the Spark Context sc
type(sc)
pyspark.context.SparkContext
SparkContext attributessc object.# List sc‘s attributes
dir(sc)
[‘PACKAGE_EXTENSIONS‘,
‘__class__‘,
‘__delattr__‘,
‘__dict__‘,
‘__doc__‘,
‘__enter__‘,
‘__exit__‘,
‘__format__‘,
‘__getattribute__‘,
‘__getnewargs__‘,
‘__hash__‘,
‘__init__‘,
‘__module__‘,
‘__new__‘,
‘__reduce__‘,
‘__reduce_ex__‘,
‘__repr__‘,
‘__setattr__‘,
‘__sizeof__‘,
‘__str__‘,
‘__subclasshook__‘,
‘__weakref__‘,
‘_accumulatorServer‘,
‘_active_spark_context‘,
‘_batchSize‘,
‘_callsite‘,
‘_checkpointFile‘,
‘_conf‘,
‘_dictToJavaMap‘,
‘_do_init‘,
‘_ensure_initialized‘,
‘_gateway‘,
‘_getJavaStorageLevel‘,
‘_initialize_context‘,
‘_javaAccumulator‘,
‘_jsc‘,
‘_jvm‘,
‘_lock‘,
‘_next_accum_id‘,
‘_pickled_broadcast_vars‘,
‘_python_includes‘,
‘_temp_dir‘,
‘_unbatched_serializer‘,
‘accumulator‘,
‘addFile‘,
‘addPyFile‘,
‘appName‘,
‘binaryFiles‘,
‘binaryRecords‘,
‘broadcast‘,
‘cancelAllJobs‘,
‘cancelJobGroup‘,
‘clearFiles‘,
‘defaultMinPartitions‘,
‘defaultParallelism‘,
‘dump_profiles‘,
‘environment‘,
‘getLocalProperty‘,
‘hadoopFile‘,
‘hadoopRDD‘,
‘master‘,
‘newAPIHadoopFile‘,
‘newAPIHadoopRDD‘,
‘parallelize‘,
‘pickleFile‘,
‘profiler_collector‘,
‘pythonExec‘,
‘runJob‘,
‘sequenceFile‘,
‘serializer‘,
‘setCheckpointDir‘,
‘setJobGroup‘,
‘setLocalProperty‘,
‘setSystemProperty‘,
‘show_profiles‘,
‘sparkHome‘,
‘sparkUser‘,
‘statusTracker‘,
‘stop‘,
‘textFile‘,
‘union‘,
‘version‘,
‘wholeTextFiles‘]
sc object has.# Use help to obtain more detailed information
help(sc)
Help on SparkContext in module pyspark.context object:
class SparkContext(__builtin__.object)
| Main entry point for Spark functionality. A SparkContext represents the
| connection to a Spark cluster, and can be used to create L{RDD} and
| broadcast variables on that cluster.
|
| Methods defined here:
|
| __enter__(self)
| Enable ‘with SparkContext(...) as sc: app(sc)‘ syntax.
|
| __exit__(self, type, value, trace)
| Enable ‘with SparkContext(...) as sc: app‘ syntax.
|
| Specifically stop the context on exit of the with block.
|
| __getnewargs__(self)
|
| __init__(self, master=None, appName=None, sparkHome=None, pyFiles=None, environment=None, batchSize=0, serializer=PickleSerializer(), conf=None, gateway=None, jsc=None, profiler_cls=<class ‘pyspark.profiler.BasicProfiler‘>)
| Create a new SparkContext. At least the master and app name should be set,
| either through the named parameters here or through C{conf}.
|
| :param master: Cluster URL to connect to
| (e.g. mesos://host:port, spark://host:port, local[4]).
| :param appName: A name for your job, to display on the cluster web UI.
| :param sparkHome: Location where Spark is installed on cluster nodes.
| :param pyFiles: Collection of .zip or .py files to send to the cluster
| and add to PYTHONPATH. These can be paths on the local file
| system or HDFS, HTTP, HTTPS, or FTP URLs.
| :param environment: A dictionary of environment variables to set on
| worker nodes.
| :param batchSize: The number of Python objects represented as a single
| Java object. Set 1 to disable batching, 0 to automatically choose
| the batch size based on object sizes, or -1 to use an unlimited
| batch size
| :param serializer: The serializer for RDDs.
| :param conf: A L{SparkConf} object setting Spark properties.
| :param gateway: Use an existing gateway and JVM, otherwise a new JVM
| will be instantiated.
| :param jsc: The JavaSparkContext instance (optional).
| :param profiler_cls: A class of custom Profiler used to do profiling
| (default is pyspark.profiler.BasicProfiler).
|
|
| >>> from pyspark.context import SparkContext
| >>> sc = SparkContext(‘local‘, ‘test‘)
|
| >>> sc2 = SparkContext(‘local‘, ‘test2‘) # doctest: +IGNORE_EXCEPTION_DETAIL
| Traceback (most recent call last):
| ...
| ValueError:...
|
| accumulator(self, value, accum_param=None)
| Create an L{Accumulator} with the given initial value, using a given
| L{AccumulatorParam} helper object to define how to add values of the
| data type if provided. Default AccumulatorParams are used for integers
| and floating-point numbers if you do not provide one. For other types,
| a custom AccumulatorParam can be used.
|
| addFile(self, path)
| Add a file to be downloaded with this Spark job on every node.
| The C{path} passed can be either a local file, a file in HDFS
| (or other Hadoop-supported filesystems), or an HTTP, HTTPS or
| FTP URI.
|
| To access the file in Spark jobs, use
| L{SparkFiles.get(fileName)<pyspark.files.SparkFiles.get>} with the
| filename to find its download location.
|
| >>> from pyspark import SparkFiles
| >>> path = os.path.join(tempdir, "test.txt")
| >>> with open(path, "w") as testFile:
| ... testFile.write("100")
| >>> sc.addFile(path)
| >>> def func(iterator):
| ... with open(SparkFiles.get("test.txt")) as testFile:
| ... fileVal = int(testFile.readline())
| ... return [x * fileVal for x in iterator]
| >>> sc.parallelize([1, 2, 3, 4]).mapPartitions(func).collect()
| [100, 200, 300, 400]
|
| addPyFile(self, path)
| Add a .py or .zip dependency for all tasks to be executed on this
| SparkContext in the future. The C{path} passed can be either a local
| file, a file in HDFS (or other Hadoop-supported filesystems), or an
| HTTP, HTTPS or FTP URI.
|
| binaryFiles(self, path, minPartitions=None)
| .. note:: Experimental
|
| Read a directory of binary files from HDFS, a local file system
| (available on all nodes), or any Hadoop-supported file system URI
| as a byte array. Each file is read as a single record and returned
| in a key-value pair, where the key is the path of each file, the
| value is the content of each file.
|
| Note: Small files are preferred, large file is also allowable, but
| may cause bad performance.
|
| binaryRecords(self, path, recordLength)
| .. note:: Experimental
|
| Load data from a flat binary file, assuming each record is a set of numbers
| with the specified numerical format (see ByteBuffer), and the number of
| bytes per record is constant.
|
| :param path: Directory to the input data files
| :param recordLength: The length at which to split the records
|
| broadcast(self, value)
| Broadcast a read-only variable to the cluster, returning a
| L{Broadcast<pyspark.broadcast.Broadcast>}
| object for reading it in distributed functions. The variable will
| be sent to each cluster only once.
|
| cancelAllJobs(self)
| Cancel all jobs that have been scheduled or are running.
|
| cancelJobGroup(self, groupId)
| Cancel active jobs for the specified group. See L{SparkContext.setJobGroup}
| for more information.
|
| clearFiles(self)
| Clear the job‘s list of files added by L{addFile} or L{addPyFile} so
| that they do not get downloaded to any new nodes.
|
| dump_profiles(self, path)
| Dump the profile stats into directory `path`
|
| getLocalProperty(self, key)
| Get a local property set in this thread, or null if it is missing. See
| L{setLocalProperty}
|
| hadoopFile(self, path, inputFormatClass, keyClass, valueClass, keyConverter=None, valueConverter=None, conf=None, batchSize=0)
| Read an ‘old‘ Hadoop InputFormat with arbitrary key and value class from HDFS,
| a local file system (available on all nodes), or any Hadoop-supported file system URI.
| The mechanism is the same as for sc.sequenceFile.
|
| A Hadoop configuration can be passed in as a Python dict. This will be converted into a
| Configuration in Java.
|
| :param path: path to Hadoop file
| :param inputFormatClass: fully qualified classname of Hadoop InputFormat
| (e.g. "org.apache.hadoop.mapred.TextInputFormat")
| :param keyClass: fully qualified classname of key Writable class
| (e.g. "org.apache.hadoop.io.Text")
| :param valueClass: fully qualified classname of value Writable class
| (e.g. "org.apache.hadoop.io.LongWritable")
| :param keyConverter: (None by default)
| :param valueConverter: (None by default)
| :param conf: Hadoop configuration, passed in as a dict
| (None by default)
| :param batchSize: The number of Python objects represented as a single
| Java object. (default 0, choose batchSize automatically)
|
| hadoopRDD(self, inputFormatClass, keyClass, valueClass, keyConverter=None, valueConverter=None, conf=None, batchSize=0)
| Read an ‘old‘ Hadoop InputFormat with arbitrary key and value class, from an arbitrary
| Hadoop configuration, which is passed in as a Python dict.
| This will be converted into a Configuration in Java.
| The mechanism is the same as for sc.sequenceFile.
|
| :param inputFormatClass: fully qualified classname of Hadoop InputFormat
| (e.g. "org.apache.hadoop.mapred.TextInputFormat")
| :param keyClass: fully qualified classname of key Writable class
| (e.g. "org.apache.hadoop.io.Text")
| :param valueClass: fully qualified classname of value Writable class
| (e.g. "org.apache.hadoop.io.LongWritable")
| :param keyConverter: (None by default)
| :param valueConverter: (None by default)
| :param conf: Hadoop configuration, passed in as a dict
| (None by default)
| :param batchSize: The number of Python objects represented as a single
| Java object. (default 0, choose batchSize automatically)
|
| newAPIHadoopFile(self, path, inputFormatClass, keyClass, valueClass, keyConverter=None, valueConverter=None, conf=None, batchSize=0)
| Read a ‘new API‘ Hadoop InputFormat with arbitrary key and value class from HDFS,
| a local file system (available on all nodes), or any Hadoop-supported file system URI.
| The mechanism is the same as for sc.sequenceFile.
|
| A Hadoop configuration can be passed in as a Python dict. This will be converted into a
| Configuration in Java
|
| :param path: path to Hadoop file
| :param inputFormatClass: fully qualified classname of Hadoop InputFormat
| (e.g. "org.apache.hadoop.mapreduce.lib.input.TextInputFormat")
| :param keyClass: fully qualified classname of key Writable class
| (e.g. "org.apache.hadoop.io.Text")
| :param valueClass: fully qualified classname of value Writable class
| (e.g. "org.apache.hadoop.io.LongWritable")
| :param keyConverter: (None by default)
| :param valueConverter: (None by default)
| :param conf: Hadoop configuration, passed in as a dict
| (None by default)
| :param batchSize: The number of Python objects represented as a single
| Java object. (default 0, choose batchSize automatically)
|
| newAPIHadoopRDD(self, inputFormatClass, keyClass, valueClass, keyConverter=None, valueConverter=None, conf=None, batchSize=0)
| Read a ‘new API‘ Hadoop InputFormat with arbitrary key and value class, from an arbitrary
| Hadoop configuration, which is passed in as a Python dict.
| This will be converted into a Configuration in Java.
| The mechanism is the same as for sc.sequenceFile.
|
| :param inputFormatClass: fully qualified classname of Hadoop InputFormat
| (e.g. "org.apache.hadoop.mapreduce.lib.input.TextInputFormat")
| :param keyClass: fully qualified classname of key Writable class
| (e.g. "org.apache.hadoop.io.Text")
| :param valueClass: fully qualified classname of value Writable class
| (e.g. "org.apache.hadoop.io.LongWritable")
| :param keyConverter: (None by default)
| :param valueConverter: (None by default)
| :param conf: Hadoop configuration, passed in as a dict
| (None by default)
| :param batchSize: The number of Python objects represented as a single
| Java object. (default 0, choose batchSize automatically)
|
| parallelize(self, c, numSlices=None)
| Distribute a local Python collection to form an RDD. Using xrange
| is recommended if the input represents a range for performance.
|
| >>> sc.parallelize([0, 2, 3, 4, 6], 5).glom().collect()
| [[0], [2], [3], [4], [6]]
| >>> sc.parallelize(xrange(0, 6, 2), 5).glom().collect()
| [[], [0], [], [2], [4]]
|
| pickleFile(self, name, minPartitions=None)
| Load an RDD previously saved using L{RDD.saveAsPickleFile} method.
|
| >>> tmpFile = NamedTemporaryFile(delete=True)
| >>> tmpFile.close()
| >>> sc.parallelize(range(10)).saveAsPickleFile(tmpFile.name, 5)
| >>> sorted(sc.pickleFile(tmpFile.name, 3).collect())
| [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
|
| runJob(self, rdd, partitionFunc, partitions=None, allowLocal=False)
| Executes the given partitionFunc on the specified set of partitions,
| returning the result as an array of elements.
|
| If ‘partitions‘ is not specified, this will run over all partitions.
|
| >>> myRDD = sc.parallelize(range(6), 3)
| >>> sc.runJob(myRDD, lambda part: [x * x for x in part])
| [0, 1, 4, 9, 16, 25]
|
| >>> myRDD = sc.parallelize(range(6), 3)
| >>> sc.runJob(myRDD, lambda part: [x * x for x in part], [0, 2], True)
| [0, 1, 16, 25]
|
| sequenceFile(self, path, keyClass=None, valueClass=None, keyConverter=None, valueConverter=None, minSplits=None, batchSize=0)
| Read a Hadoop SequenceFile with arbitrary key and value Writable class from HDFS,
| a local file system (available on all nodes), or any Hadoop-supported file system URI.
| The mechanism is as follows:
|
| 1. A Java RDD is created from the SequenceFile or other InputFormat, and the key
| and value Writable classes
| 2. Serialization is attempted via Pyrolite pickling
| 3. If this fails, the fallback is to call ‘toString‘ on each key and value
| 4. C{PickleSerializer} is used to deserialize pickled objects on the Python side
|
| :param path: path to sequncefile
| :param keyClass: fully qualified classname of key Writable class
| (e.g. "org.apache.hadoop.io.Text")
| :param valueClass: fully qualified classname of value Writable class
| (e.g. "org.apache.hadoop.io.LongWritable")
| :param keyConverter:
| :param valueConverter:
| :param minSplits: minimum splits in dataset
| (default min(2, sc.defaultParallelism))
| :param batchSize: The number of Python objects represented as a single
| Java object. (default 0, choose batchSize automatically)
|
| setCheckpointDir(self, dirName)
| Set the directory under which RDDs are going to be checkpointed. The
| directory must be a HDFS path if running on a cluster.
|
| setJobGroup(self, groupId, description, interruptOnCancel=False)
| Assigns a group ID to all the jobs started by this thread until the group ID is set to a
| different value or cleared.
|
| Often, a unit of execution in an application consists of multiple Spark actions or jobs.
| Application programmers can use this method to group all those jobs together and give a
| group description. Once set, the Spark web UI will associate such jobs with this group.
|
| The application can use L{SparkContext.cancelJobGroup} to cancel all
| running jobs in this group.
|
| >>> import thread, threading
| >>> from time import sleep
| >>> result = "Not Set"
| >>> lock = threading.Lock()
| >>> def map_func(x):
| ... sleep(100)
| ... raise Exception("Task should have been cancelled")
| >>> def start_job(x):
| ... global result
| ... try:
| ... sc.setJobGroup("job_to_cancel", "some description")
| ... result = sc.parallelize(range(x)).map(map_func).collect()
| ... except Exception as e:
| ... result = "Cancelled"
| ... lock.release()
| >>> def stop_job():
| ... sleep(5)
| ... sc.cancelJobGroup("job_to_cancel")
| >>> supress = lock.acquire()
| >>> supress = thread.start_new_thread(start_job, (10,))
| >>> supress = thread.start_new_thread(stop_job, tuple())
| >>> supress = lock.acquire()
| >>> print result
| Cancelled
|
| If interruptOnCancel is set to true for the job group, then job cancellation will result
| in Thread.interrupt() being called on the job‘s executor threads. This is useful to help
| ensure that the tasks are actually stopped in a timely manner, but is off by default due
| to HDFS-1208, where HDFS may respond to Thread.interrupt() by marking nodes as dead.
|
| setLocalProperty(self, key, value)
| Set a local property that affects jobs submitted from this thread, such as the
| Spark fair scheduler pool.
|
| show_profiles(self)
| Print the profile stats to stdout
|
| sparkUser(self)
| Get SPARK_USER for user who is running SparkContext.
|
| statusTracker(self)
| Return :class:`StatusTracker` object
|
| stop(self)
| Shut down the SparkContext.
|
| textFile(self, name, minPartitions=None, use_unicode=True)
| Read a text file from HDFS, a local file system (available on all
| nodes), or any Hadoop-supported file system URI, and return it as an
| RDD of Strings.
|
| If use_unicode is False, the strings will be kept as `str` (encoding
| as `utf-8`), which is faster and smaller than unicode. (Added in
| Spark 1.2)
|
| >>> path = os.path.join(tempdir, "sample-text.txt")
| >>> with open(path, "w") as testFile:
| ... testFile.write("Hello world!")
| >>> textFile = sc.textFile(path)
| >>> textFile.collect()
| [u‘Hello world!‘]
|
| union(self, rdds)
| Build the union of a list of RDDs.
|
| This supports unions() of RDDs with different serialized formats,
| although this forces them to be reserialized using the default
| serializer:
|
| >>> path = os.path.join(tempdir, "union-text.txt")
| >>> with open(path, "w") as testFile:
| ... testFile.write("Hello")
| >>> textFile = sc.textFile(path)
| >>> textFile.collect()
| [u‘Hello‘]
| >>> parallelized = sc.parallelize(["World!"])
| >>> sorted(sc.union([textFile, parallelized]).collect())
| [u‘Hello‘, ‘World!‘]
|
| wholeTextFiles(self, path, minPartitions=None, use_unicode=True)
| Read a directory of text files from HDFS, a local file system
| (available on all nodes), or any Hadoop-supported file system
| URI. Each file is read as a single record and returned in a
| key-value pair, where the key is the path of each file, the
| value is the content of each file.
|
| If use_unicode is False, the strings will be kept as `str` (encoding
| as `utf-8`), which is faster and smaller than unicode. (Added in
| Spark 1.2)
|
| For example, if you have the following files::
|
| hdfs://a-hdfs-path/part-00000
| hdfs://a-hdfs-path/part-00001
| ...
| hdfs://a-hdfs-path/part-nnnnn
|
| Do C{rdd = sparkContext.wholeTextFiles("hdfs://a-hdfs-path")},
| then C{rdd} contains::
|
| (a-hdfs-path/part-00000, its content)
| (a-hdfs-path/part-00001, its content)
| ...
| (a-hdfs-path/part-nnnnn, its content)
|
| NOTE: Small files are preferred, as each file will be loaded
| fully in memory.
|
| >>> dirPath = os.path.join(tempdir, "files")
| >>> os.mkdir(dirPath)
| >>> with open(os.path.join(dirPath, "1.txt"), "w") as file1:
| ... file1.write("1")
| >>> with open(os.path.join(dirPath, "2.txt"), "w") as file2:
| ... file2.write("2")
| >>> textFiles = sc.wholeTextFiles(dirPath)
| >>> sorted(textFiles.collect())
| [(u‘.../1.txt‘, u‘1‘), (u‘.../2.txt‘, u‘2‘)]
|
| ----------------------------------------------------------------------
| Class methods defined here:
|
| setSystemProperty(cls, key, value) from __builtin__.type
| Set a Java system property, such as spark.executor.memory. This must
| must be invoked before instantiating SparkContext.
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| defaultMinPartitions
| Default min number of partitions for Hadoop RDDs when not given by user
|
| defaultParallelism
| Default level of parallelism to use when not given by user (e.g. for
| reduce tasks)
|
| version
| The version of Spark on which this application is running.
|
| ----------------------------------------------------------------------
| Data and other attributes defined here:
|
| PACKAGE_EXTENSIONS = (‘.zip‘, ‘.egg‘, ‘.jar‘)
# After reading the help we‘ve decided we want to use sc.version to see what version of Spark we are running
sc.version
u‘1.3.1‘
# Help can be used on any Python object
help(map)
Help on built-in function map in module __builtin__:
map(...)
map(function, sequence[, sequence, ...]) -> list
Return a list of the results of applying the function to the items of
the argument sequence(s). If more than one sequence is given, the
function is called with an argument list consisting of the corresponding
item of each sequence, substituting None for missing values when not all
sequences have the same length. If the function is None, return a list of
the items of the sequence (or a list of tuples if more than one sequence).
mapcollect to view resultscount to view countsfilter and view results with collectxrange() only generates values as they are needed. This is different from the behavior of range() which generates the complete list upon execution. Because of this xrange() is more memory efficient than range(), especially for large ranges.data = xrange(1, 10001)
# Data is just a normal Python list
# Obtain data‘s first element
data[0]
1
# We can check the size of the list using the len() function
len(data)
10000
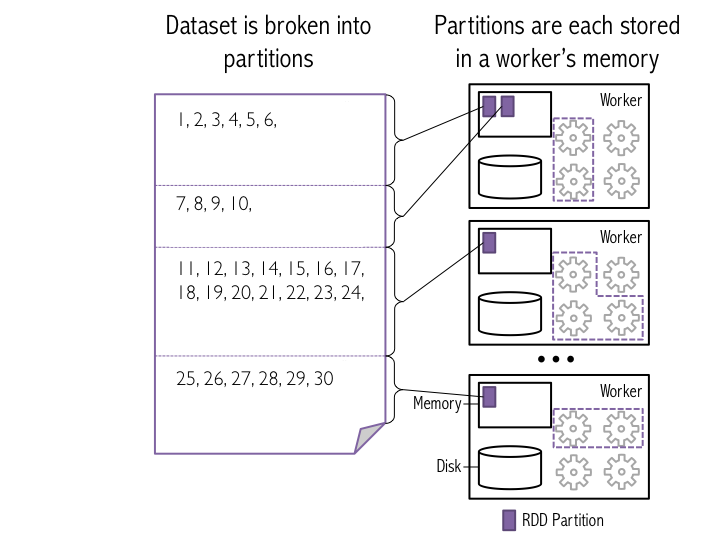
sc.parallelize(), which tells Spark to create a new set of input data based on data that is passed in. In this example, we will provide an xrange. The second argument to the sc.parallelize() method tells Spark how many partitions to break the data into when it stores the data in memory (we’ll talk more about this later in this tutorial). Note that for better performance when using parallelize, xrange() is recommended if the input represents a range. This is the reason why we used xrange() in 3a.pyspark.RDD. Since the other RDD types inherit from pyspark.RDD they have the same APIs and are functionally identical. We’ll see that sc.parallelize() generates a pyspark.rdd.PipelinedRDD when its input is an xrange, and a pyspark.RDD when its input is a range.# Parallelize data using 8 partitions
# This operation is a transformation of data into an RDD
# Spark uses lazy evaluation, so no Spark jobs are run at this point
xrangeRDD = sc.parallelize(data, 8)
# Let‘s view help on parallelize
help(sc.parallelize)
Help on method parallelize in module pyspark.context:
parallelize(self, c, numSlices=None) method of pyspark.context.SparkContext instance
Distribute a local Python collection to form an RDD. Using xrange
is recommended if the input represents a range for performance.
>>> sc.parallelize([0, 2, 3, 4, 6], 5).glom().collect()
[[0], [2], [3], [4], [6]]
>>> sc.parallelize(xrange(0, 6, 2), 5).glom().collect()
[[], [0], [], [2], [4]]
# Let‘s see what type sc.parallelize() returned
print ‘type of xrangeRDD: {0}‘.format(type(xrangeRDD))
# How about if we use a range
dataRange = range(1, 10001)
rangeRDD = sc.parallelize(dataRange, 8)
print ‘type of dataRangeRDD: {0}‘.format(type(rangeRDD))
type of xrangeRDD: <class ‘pyspark.rdd.PipelinedRDD‘>
type of dataRangeRDD: <class ‘pyspark.rdd.RDD‘>
# Each RDD gets a unique ID
print ‘xrangeRDD id: {0}‘.format(xrangeRDD.id())
print ‘rangeRDD id: {0}‘.format(rangeRDD.id())
xrangeRDD id: 2
rangeRDD id: 1
# We can name each newly created RDD using the setName() method
xrangeRDD.setName(‘My first RDD‘)
My first RDD PythonRDD[2] at RDD at PythonRDD.scala:43
# Let‘s view the lineage (the set of transformations) of the RDD using toDebugString()
print xrangeRDD.toDebugString()
(8) My first RDD PythonRDD[2] at RDD at PythonRDD.scala:43 []
| ParallelCollectionRDD[0] at parallelize at PythonRDD.scala:392 []
# Let‘s use help to see what methods we can call on this RDD
help(xrangeRDD)
Help on PipelinedRDD in module pyspark.rdd object:
class PipelinedRDD(RDD)
| Pipelined maps:
|
| >>> rdd = sc.parallelize([1, 2, 3, 4])
| >>> rdd.map(lambda x: 2 * x).cache().map(lambda x: 2 * x).collect()
| [4, 8, 12, 16]
| >>> rdd.map(lambda x: 2 * x).map(lambda x: 2 * x).collect()
| [4, 8, 12, 16]
|
| Pipelined reduces:
| >>> from operator import add
| >>> rdd.map(lambda x: 2 * x).reduce(add)
| 20
| >>> rdd.flatMap(lambda x: [x, x]).reduce(add)
| 20
|
| Method resolution order:
| PipelinedRDD
| RDD
| __builtin__.object
|
| Methods defined here:
|
| __del__(self)
|
| __init__(self, prev, func, preservesPartitioning=False)
|
| id(self)
|
| ----------------------------------------------------------------------
| Methods inherited from RDD:
|
| __add__(self, other)
| Return the union of this RDD and another one.
|
| >>> rdd = sc.parallelize([1, 1, 2, 3])
| >>> (rdd + rdd).collect()
| [1, 1, 2, 3, 1, 1, 2, 3]
|
| __getnewargs__(self)
|
| __repr__(self)
|
| aggregate(self, zeroValue, seqOp, combOp)
| Aggregate the elements of each partition, and then the results for all
| the partitions, using a given combine functions and a neutral "zero
| value."
|
| The functions C{op(t1, t2)} is allowed to modify C{t1} and return it
| as its result value to avoid object allocation; however, it should not
| modify C{t2}.
|
| The first function (seqOp) can return a different result type, U, than
| the type of this RDD. Thus, we need one operation for merging a T into
| an U and one operation for merging two U
|
| >>> seqOp = (lambda x, y: (x[0] + y, x[1] + 1))
| >>> combOp = (lambda x, y: (x[0] + y[0], x[1] + y[1]))
| >>> sc.parallelize([1, 2, 3, 4]).aggregate((0, 0), seqOp, combOp)
| (10, 4)
| >>> sc.parallelize([]).aggregate((0, 0), seqOp, combOp)
| (0, 0)
|
| aggregateByKey(self, zeroValue, seqFunc, combFunc, numPartitions=None)
| Aggregate the values of each key, using given combine functions and a neutral
| "zero value". This function can return a different result type, U, than the type
| of the values in this RDD, V. Thus, we need one operation for merging a V into
| a U and one operation for merging two U‘s, The former operation is used for merging
| values within a partition, and the latter is used for merging values between
| partitions. To avoid memory allocation, both of these functions are
| allowed to modify and return their first argument instead of creating a new U.
|
| cache(self)
| Persist this RDD with the default storage level (C{MEMORY_ONLY_SER}).
|
| cartesian(self, other)
| Return the Cartesian product of this RDD and another one, that is, the
| RDD of all pairs of elements C{(a, b)} where C{a} is in C{self} and
| C{b} is in C{other}.
|
| >>> rdd = sc.parallelize([1, 2])
| >>> sorted(rdd.cartesian(rdd).collect())
| [(1, 1), (1, 2), (2, 1), (2, 2)]
|
| checkpoint(self)
| Mark this RDD for checkpointing. It will be saved to a file inside the
| checkpoint directory set with L{SparkContext.setCheckpointDir()} and
| all references to its parent RDDs will be removed. This function must
| be called before any job has been executed on this RDD. It is strongly
| recommended that this RDD is persisted in memory, otherwise saving it
| on a file will require recomputation.
|
| coalesce(self, numPartitions, shuffle=False)
| Return a new RDD that is reduced into `numPartitions` partitions.
|
| >>> sc.parallelize([1, 2, 3, 4, 5], 3).glom().collect()
| [[1], [2, 3], [4, 5]]
| >>> sc.parallelize([1, 2, 3, 4, 5], 3).coalesce(1).glom().collect()
| [[1, 2, 3, 4, 5]]
|
| cogroup(self, other, numPartitions=None)
| For each key k in C{self} or C{other}, return a resulting RDD that
| contains a tuple with the list of values for that key in C{self} as
| well as C{other}.
|
| >>> x = sc.parallelize([("a", 1), ("b", 4)])
| >>> y = sc.parallelize([("a", 2)])
| >>> map((lambda (x,y): (x, (list(y[0]), list(y[1])))), sorted(list(x.cogroup(y).collect())))
| [(‘a‘, ([1], [2])), (‘b‘, ([4], []))]
|
| collect(self)
| Return a list that contains all of the elements in this RDD.
|
| collectAsMap(self)
| Return the key-value pairs in this RDD to the master as a dictionary.
|
| >>> m = sc.parallelize([(1, 2), (3, 4)]).collectAsMap()
| >>> m[1]
| 2
| >>> m[3]
| 4
|
| combineByKey(self, createCombiner, mergeValue, mergeCombiners, numPartitions=None)
| Generic function to combine the elements for each key using a custom
| set of aggregation functions.
|
| Turns an RDD[(K, V)] into a result of type RDD[(K, C)], for a "combined
| type" C. Note that V and C can be different -- for example, one might
| group an RDD of type (Int, Int) into an RDD of type (Int, List[Int]).
|
| Users provide three functions:
|
| - C{createCombiner}, which turns a V into a C (e.g., creates
| a one-element list)
| - C{mergeValue}, to merge a V into a C (e.g., adds it to the end of
| a list)
| - C{mergeCombiners}, to combine two C‘s into a single one.
|
| In addition, users can control the partitioning of the output RDD.
|
| >>> x = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
| >>> def f(x): return x
| >>> def add(a, b): return a + str(b)
| >>> sorted(x.combineByKey(str, add, add).collect())
| [(‘a‘, ‘11‘), (‘b‘, ‘1‘)]
|
| count(self)
| Return the number of elements in this RDD.
|
| >>> sc.parallelize([2, 3, 4]).count()
| 3
|
| countApprox(self, timeout, confidence=0.95)
| .. note:: Experimental
|
| Approximate version of count() that returns a potentially incomplete
| result within a timeout, even if not all tasks have finished.
|
| >>> rdd = sc.parallelize(range(1000), 10)
| >>> rdd.countApprox(1000, 1.0)
| 1000
|
| countApproxDistinct(self, relativeSD=0.05)
| .. note:: Experimental
|
| Return approximate number of distinct elements in the RDD.
|
| The algorithm used is based on streamlib‘s implementation of
| "HyperLogLog in Practice: Algorithmic Engineering of a State
| of The Art Cardinality Estimation Algorithm", available
| <a href="http://dx.doi.org/10.1145/2452376.2452456">here</a>.
|
| :param relativeSD: Relative accuracy. Smaller values create
| counters that require more space.
| It must be greater than 0.000017.
|
| >>> n = sc.parallelize(range(1000)).map(str).countApproxDistinct()
| >>> 950 < n < 1050
| True
| >>> n = sc.parallelize([i % 20 for i in range(1000)]).countApproxDistinct()
| >>> 18 < n < 22
| True
|
| countByKey(self)
| Count the number of elements for each key, and return the result to the
| master as a dictionary.
|
| >>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
| >>> sorted(rdd.countByKey().items())
| [(‘a‘, 2), (‘b‘, 1)]
|
| countByValue(self)
| Return the count of each unique value in this RDD as a dictionary of
| (value, count) pairs.
|
| >>> sorted(sc.parallelize([1, 2, 1, 2, 2], 2).countByValue().items())
| [(1, 2), (2, 3)]
|
| distinct(self, numPartitions=None)
| Return a new RDD containing the distinct elements in this RDD.
|
| >>> sorted(sc.parallelize([1, 1, 2, 3]).distinct().collect())
| [1, 2, 3]
|
| filter(self, f)
| Return a new RDD containing only the elements that satisfy a predicate.
|
| >>> rdd = sc.parallelize([1, 2, 3, 4, 5])
| >>> rdd.filter(lambda x: x % 2 == 0).collect()
| [2, 4]
|
| first(self)
| Return the first element in this RDD.
|
| >>> sc.parallelize([2, 3, 4]).first()
| 2
| >>> sc.parallelize([]).first()
| Traceback (most recent call last):
| ...
| ValueError: RDD is empty
|
| flatMap(self, f, preservesPartitioning=False)
| Return a new RDD by first applying a function to all elements of this
| RDD, and then flattening the results.
|
| >>> rdd = sc.parallelize([2, 3, 4])
| >>> sorted(rdd.flatMap(lambda x: range(1, x)).collect())
| [1, 1, 1, 2, 2, 3]
| >>> sorted(rdd.flatMap(lambda x: [(x, x), (x, x)]).collect())
| [(2, 2), (2, 2), (3, 3), (3, 3), (4, 4), (4, 4)]
|
| flatMapValues(self, f)
| Pass each value in the key-value pair RDD through a flatMap function
| without changing the keys; this also retains the original RDD‘s
| partitioning.
|
| >>> x = sc.parallelize([("a", ["x", "y", "z"]), ("b", ["p", "r"])])
| >>> def f(x): return x
| >>> x.flatMapValues(f).collect()
| [(‘a‘, ‘x‘), (‘a‘, ‘y‘), (‘a‘, ‘z‘), (‘b‘, ‘p‘), (‘b‘, ‘r‘)]
|
| fold(self, zeroValue, op)
| Aggregate the elements of each partition, and then the results for all
| the partitions, using a given associative function and a neutral "zero
| value."
|
| The function C{op(t1, t2)} is allowed to modify C{t1} and return it
| as its result value to avoid object allocation; however, it should not
| modify C{t2}.
|
| >>> from operator import add
| >>> sc.parallelize([1, 2, 3, 4, 5]).fold(0, add)
| 15
|
| foldByKey(self, zeroValue, func, numPartitions=None)
| Merge the values for each key using an associative function "func"
| and a neutral "zeroValue" which may be added to the result an
| arbitrary number of times, and must not change the result
| (e.g., 0 for addition, or 1 for multiplication.).
|
| >>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
| >>> from operator import add
| >>> rdd.foldByKey(0, add).collect()
| [(‘a‘, 2), (‘b‘, 1)]
|
| foreach(self, f)
| Applies a function to all elements of this RDD.
|
| >>> def f(x): print x
| >>> sc.parallelize([1, 2, 3, 4, 5]).foreach(f)
|
| foreachPartition(self, f)
| Applies a function to each partition of this RDD.
|
| >>> def f(iterator):
| ... for x in iterator:
| ... print x
| >>> sc.parallelize([1, 2, 3, 4, 5]).foreachPartition(f)
|
| fullOuterJoin(self, other, numPartitions=None)
| Perform a right outer join of C{self} and C{other}.
|
| For each element (k, v) in C{self}, the resulting RDD will either
| contain all pairs (k, (v, w)) for w in C{other}, or the pair
| (k, (v, None)) if no elements in C{other} have key k.
|
| Similarly, for each element (k, w) in C{other}, the resulting RDD will
| either contain all pairs (k, (v, w)) for v in C{self}, or the pair
| (k, (None, w)) if no elements in C{self} have key k.
|
| Hash-partitions the resulting RDD into the given number of partitions.
|
| >>> x = sc.parallelize([("a", 1), ("b", 4)])
| >>> y = sc.parallelize([("a", 2), ("c", 8)])
| >>> sorted(x.fullOuterJoin(y).collect())
| [(‘a‘, (1, 2)), (‘b‘, (4, None)), (‘c‘, (None, 8))]
|
| getCheckpointFile(self)
| Gets the name of the file to which this RDD was checkpointed
|
| getNumPartitions(self)
| Returns the number of partitions in RDD
|
| >>> rdd = sc.parallelize([1, 2, 3, 4], 2)
| >>> rdd.getNumPartitions()
| 2
|
| getStorageLevel(self)
| Get the RDD‘s current storage level.
|
| >>> rdd1 = sc.parallelize([1,2])
| >>> rdd1.getStorageLevel()
| StorageLevel(False, False, False, False, 1)
| >>> print(rdd1.getStorageLevel())
| Serialized 1x Replicated
|
| glom(self)
| Return an RDD created by coalescing all elements within each partition
| into a list.
|
| >>> rdd = sc.parallelize([1, 2, 3, 4], 2)
| >>> sorted(rdd.glom().collect())
| [[1, 2], [3, 4]]
|
| groupBy(self, f, numPartitions=None)
| Return an RDD of grouped items.
|
| >>> rdd = sc.parallelize([1, 1, 2, 3, 5, 8])
| >>> result = rdd.groupBy(lambda x: x % 2).collect()
| >>> sorted([(x, sorted(y)) for (x, y) in result])
| [(0, [2, 8]), (1, [1, 1, 3, 5])]
|
| groupByKey(self, numPartitions=None)
| Group the values for each key in the RDD into a single sequence.
| Hash-partitions the resulting RDD with into numPartitions partitions.
|
| Note: If you are grouping in order to perform an aggregation (such as a
| sum or average) over each key, using reduceByKey or aggregateByKey will
| provide much better performance.
|
| >>> x = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
| >>> map((lambda (x,y): (x, list(y))), sorted(x.groupByKey().collect()))
| [(‘a‘, [1, 1]), (‘b‘, [1])]
|
| groupWith(self, other, *others)
| Alias for cogroup but with support for multiple RDDs.
|
| >>> w = sc.parallelize([("a", 5), ("b", 6)])
| >>> x = sc.parallelize([("a", 1), ("b", 4)])
| >>> y = sc.parallelize([("a", 2)])
| >>> z = sc.parallelize([("b", 42)])
| >>> map((lambda (x,y): (x, (list(y[0]), list(y[1]), list(y[2]), list(y[3])))), sorted(list(w.groupWith(x, y, z).collect())))
| [(‘a‘, ([5], [1], [2], [])), (‘b‘, ([6], [4], [], [42]))]
|
| histogram(self, buckets)
| Compute a histogram using the provided buckets. The buckets
| are all open to the right except for the last which is closed.
| e.g. [1,10,20,50] means the buckets are [1,10) [10,20) [20,50],
| which means 1<=x<10, 10<=x<20, 20<=x<=50. And on the input of 1
| and 50 we would have a histogram of 1,0,1.
|
| If your histogram is evenly spaced (e.g. [0, 10, 20, 30]),
| this can be switched from an O(log n) inseration to O(1) per
| element(where n = # buckets).
|
| Buckets must be sorted and not contain any duplicates, must be
| at least two elements.
|
| If `buckets` is a number, it will generates buckets which are
| evenly spaced between the minimum and maximum of the RDD. For
| example, if the min value is 0 and the max is 100, given buckets
| as 2, the resulting buckets will be [0,50) [50,100]. buckets must
| be at least 1 If the RDD contains infinity, NaN throws an exception
| If the elements in RDD do not vary (max == min) always returns
| a single bucket.
|
| It will return an tuple of buckets and histogram.
|
| >>> rdd = sc.parallelize(range(51))
| >>> rdd.histogram(2)
| ([0, 25, 50], [25, 26])
| >>> rdd.histogram([0, 5, 25, 50])
| ([0, 5, 25, 50], [5, 20, 26])
| >>> rdd.histogram([0, 15, 30, 45, 60]) # evenly spaced buckets
| ([0, 15, 30, 45, 60], [15, 15, 15, 6])
| >>> rdd = sc.parallelize(["ab", "ac", "b", "bd", "ef"])
| >>> rdd.histogram(("a", "b", "c"))
| ((‘a‘, ‘b‘, ‘c‘), [2, 2])
|
| intersection(self, other)
| Return the intersection of this RDD and another one. The output will
| not contain any duplicate elements, even if the input RDDs did.
|
| Note that this method performs a shuffle internally.
|
| >>> rdd1 = sc.parallelize([1, 10, 2, 3, 4, 5])
| >>> rdd2 = sc.parallelize([1, 6, 2, 3, 7, 8])
| >>> rdd1.intersection(rdd2).collect()
| [1, 2, 3]
|
| isCheckpointed(self)
| Return whether this RDD has been checkpointed or not
|
| isEmpty(self)
| Returns true if and only if the RDD contains no elements at all. Note that an RDD
| may be empty even when it has at least 1 partition.
|
| >>> sc.parallelize([]).isEmpty()
| True
| >>> sc.parallelize([1]).isEmpty()
| False
|
| join(self, other, numPartitions=None)
| Return an RDD containing all pairs of elements with matching keys in
| C{self} and C{other}.
|
| Each pair of elements will be returned as a (k, (v1, v2)) tuple, where
| (k, v1) is in C{self} and (k, v2) is in C{other}.
|
| Performs a hash join across the cluster.
|
| >>> x = sc.parallelize([("a", 1), ("b", 4)])
| >>> y = sc.parallelize([("a", 2), ("a", 3)])
| >>> sorted(x.join(y).collect())
| [(‘a‘, (1, 2)), (‘a‘, (1, 3))]
|
| keyBy(self, f)
| Creates tuples of the elements in this RDD by applying C{f}.
|
| >>> x = sc.parallelize(range(0,3)).keyBy(lambda x: x*x)
| >>> y = sc.parallelize(zip(range(0,5), range(0,5)))
| >>> map((lambda (x,y): (x, (list(y[0]), (list(y[1]))))), sorted(x.cogroup(y).collect()))
| [(0, ([0], [0])), (1, ([1], [1])), (2, ([], [2])), (3, ([], [3])), (4, ([2], [4]))]
|
| keys(self)
| Return an RDD with the keys of each tuple.
|
| >>> m = sc.parallelize([(1, 2), (3, 4)]).keys()
| >>> m.collect()
| [1, 3]
|
| leftOuterJoin(self, other, numPartitions=None)
| Perform a left outer join of C{self} and C{other}.
|
| For each element (k, v) in C{self}, the resulting RDD will either
| contain all pairs (k, (v, w)) for w in C{other}, or the pair
| (k, (v, None)) if no elements in C{other} have key k.
|
| Hash-partitions the resulting RDD into the given number of partitions.
|
| >>> x = sc.parallelize([("a", 1), ("b", 4)])
| >>> y = sc.parallelize([("a", 2)])
| >>> sorted(x.leftOuterJoin(y).collect())
| [(‘a‘, (1, 2)), (‘b‘, (4, None))]
|
| lookup(self, key)
| Return the list of values in the RDD for key `key`. This operation
| is done efficiently if the RDD has a known partitioner by only
| searching the partition that the key maps to.
|
| >>> l = range(1000)
| >>> rdd = sc.parallelize(zip(l, l), 10)
| >>> rdd.lookup(42) # slow
| [42]
| >>> sorted = rdd.sortByKey()
| >>> sorted.lookup(42) # fast
| [42]
| >>> sorted.lookup(1024)
| []
|
| map(self, f, preservesPartitioning=False)
| Return a new RDD by applying a function to each element of this RDD.
|
| >>> rdd = sc.parallelize(["b", "a", "c"])
| >>> sorted(rdd.map(lambda x: (x, 1)).collect())
| [(‘a‘, 1), (‘b‘, 1), (‘c‘, 1)]
|
| mapPartitions(self, f, preservesPartitioning=False)
| Return a new RDD by applying a function to each partition of this RDD.
|
| >>> rdd = sc.parallelize([1, 2, 3, 4], 2)
| >>> def f(iterator): yield sum(iterator)
| >>> rdd.mapPartitions(f).collect()
| [3, 7]
|
| mapPartitionsWithIndex(self, f, preservesPartitioning=False)
| Return a new RDD by applying a function to each partition of this RDD,
| while tracking the index of the original partition.
|
| >>> rdd = sc.parallelize([1, 2, 3, 4], 4)
| >>> def f(splitIndex, iterator): yield splitIndex
| >>> rdd.mapPartitionsWithIndex(f).sum()
| 6
|
| mapPartitionsWithSplit(self, f, preservesPartitioning=False)
| Deprecated: use mapPartitionsWithIndex instead.
|
| Return a new RDD by applying a function to each partition of this RDD,
| while tracking the index of the original partition.
|
| >>> rdd = sc.parallelize([1, 2, 3, 4], 4)
| >>> def f(splitIndex, iterator): yield splitIndex
| >>> rdd.mapPartitionsWithSplit(f).sum()
| 6
|
| mapValues(self, f)
| Pass each value in the key-value pair RDD through a map function
| without changing the keys; this also retains the original RDD‘s
| partitioning.
|
| >>> x = sc.parallelize([("a", ["apple", "banana", "lemon"]), ("b", ["grapes"])])
| >>> def f(x): return len(x)
| >>> x.mapValues(f).collect()
| [(‘a‘, 3), (‘b‘, 1)]
|
| max(self, key=None)
| Find the maximum item in this RDD.
|
| :param key: A function used to generate key for comparing
|
| >>> rdd = sc.parallelize([1.0, 5.0, 43.0, 10.0])
| >>> rdd.max()
| 43.0
| >>> rdd.max(key=str)
| 5.0
|
| mean(self)
| Compute the mean of this RDD‘s elements.
|
| >>> sc.parallelize([1, 2, 3]).mean()
| 2.0
|
| meanApprox(self, timeout, confidence=0.95)
| .. note:: Experimental
|
| Approximate operation to return the mean within a timeout
| or meet the confidence.
|
| >>> rdd = sc.parallelize(range(1000), 10)
| >>> r = sum(xrange(1000)) / 1000.0
| >>> (rdd.meanApprox(1000) - r) / r < 0.05
| True
|
| min(self, key=None)
| Find the minimum item in this RDD.
|
| :param key: A function used to generate key for comparing
|
| >>> rdd = sc.parallelize([2.0, 5.0, 43.0, 10.0])
| >>> rdd.min()
| 2.0
| >>> rdd.min(key=str)
| 10.0
|
| name(self)
| Return the name of this RDD.
|
| partitionBy(self, numPartitions, partitionFunc=<function portable_hash>)
| Return a copy of the RDD partitioned using the specified partitioner.
|
| >>> pairs = sc.parallelize([1, 2, 3, 4, 2, 4, 1]).map(lambda x: (x, x))
| >>> sets = pairs.partitionBy(2).glom().collect()
| >>> set(sets[0]).intersection(set(sets[1]))
| set([])
|
| persist(self, storageLevel=StorageLevel(False, True, False, False, 1))
| Set this RDD‘s storage level to persist its values across operations
| after the first time it is computed. This can only be used to assign
| a new storage level if the RDD does not have a storage level set yet.
| If no storage level is specified defaults to (C{MEMORY_ONLY_SER}).
|
| >>> rdd = sc.parallelize(["b", "a", "c"])
| >>> rdd.persist().is_cached
| True
|
| pipe(self, command, env={})
| Return an RDD created by piping elements to a forked external process.
|
| >>> sc.parallelize([‘1‘, ‘2‘, ‘‘, ‘3‘]).pipe(‘cat‘).collect()
| [‘1‘, ‘2‘, ‘‘, ‘3‘]
|
| randomSplit(self, weights, seed=None)
| Randomly splits this RDD with the provided weights.
|
| :param weights: weights for splits, will be normalized if they don‘t sum to 1
| :param seed: random seed
| :return: split RDDs in a list
|
| >>> rdd = sc.parallelize(range(5), 1)
| >>> rdd1, rdd2 = rdd.randomSplit([2, 3], 17)
| >>> rdd1.collect()
| [1, 3]
| >>> rdd2.collect()
| [0, 2, 4]
|
| reduce(self, f)
| Reduces the elements of this RDD using the specified commutative and
| associative binary operator. Currently reduces partitions locally.
|
| >>> from operator import add
| >>> sc.parallelize([1, 2, 3, 4, 5]).reduce(add)
| 15
| >>> sc.parallelize((2 for _ in range(10))).map(lambda x: 1).cache().reduce(add)
| 10
| >>> sc.parallelize([]).reduce(add)
| Traceback (most recent call last):
| ...
| ValueError: Can not reduce() empty RDD
|
| reduceByKey(self, func, numPartitions=None)
| Merge the values for each key using an associative reduce function.
|
| This will also perform the merging locally on each mapper before
| sending results to a reducer, similarly to a "combiner" in MapReduce.
|
| Output will be hash-partitioned with C{numPartitions} partitions, or
| the default parallelism level if C{numPartitions} is not specified.
|
| >>> from operator import add
| >>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
| >>> sorted(rdd.reduceByKey(add).collect())
| [(‘a‘, 2), (‘b‘, 1)]
|
| reduceByKeyLocally(self, func)
| Merge the values for each key using an associative reduce function, but
| return the results immediately to the master as a dictionary.
|
| This will also perform the merging locally on each mapper before
| sending results to a reducer, similarly to a "combiner" in MapReduce.
|
| >>> from operator import add
| >>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
| >>> sorted(rdd.reduceByKeyLocally(add).items())
| [(‘a‘, 2), (‘b‘, 1)]
|
| repartition(self, numPartitions)
| Return a new RDD that has exactly numPartitions partitions.
|
| Can increase or decrease the level of parallelism in this RDD.
| Internally, this uses a shuffle to redistribute data.
| If you are decreasing the number of partitions in this RDD, consider
| using `coalesce`, which can avoid performing a shuffle.
|
| >>> rdd = sc.parallelize([1,2,3,4,5,6,7], 4)
| >>> sorted(rdd.glom().collect())
| [[1], [2, 3], [4, 5], [6, 7]]
| >>> len(rdd.repartition(2).glom().collect())
| 2
| >>> len(rdd.repartition(10).glom().collect())
| 10
|
| repartitionAndSortWithinPartitions(self, numPartitions=None, partitionFunc=<function portable_hash>, ascending=True, keyfunc=<function <lambda>>)
| Repartition the RDD according to the given partitioner and, within each resulting partition,
| sort records by their keys.
|
| >>> rdd = sc.parallelize([(0, 5), (3, 8), (2, 6), (0, 8), (3, 8), (1, 3)])
| >>> rdd2 = rdd.repartitionAndSortWithinPartitions(2, lambda x: x % 2, 2)
| >>> rdd2.glom().collect()
| [[(0, 5), (0, 8), (2, 6)], [(1, 3), (3, 8), (3, 8)]]
|
| rightOuterJoin(self, other, numPartitions=None)
| Perform a right outer join of C{self} and C{other}.
|
| For each element (k, w) in C{other}, the resulting RDD will either
| contain all pairs (k, (v, w)) for v in this, or the pair (k, (None, w))
| if no elements in C{self} have key k.
|
| Hash-partitions the resulting RDD into the given number of partitions.
|
| >>> x = sc.parallelize([("a", 1), ("b", 4)])
| >>> y = sc.parallelize([("a", 2)])
| >>> sorted(y.rightOuterJoin(x).collect())
| [(‘a‘, (2, 1)), (‘b‘, (None, 4))]
|
| sample(self, withReplacement, fraction, seed=None)
| Return a sampled subset of this RDD.
|
| >>> rdd = sc.parallelize(range(100), 4)
| >>> rdd.sample(False, 0.1, 81).count()
| 10
|
| sampleByKey(self, withReplacement, fractions, seed=None)
| Return a subset of this RDD sampled by key (via stratified sampling).
| Create a sample of this RDD using variable sampling rates for
| different keys as specified by fractions, a key to sampling rate map.
|
| >>> fractions = {"a": 0.2, "b": 0.1}
| >>> rdd = sc.parallelize(fractions.keys()).cartesian(sc.parallelize(range(0, 1000)))
| >>> sample = dict(rdd.sampleByKey(False, fractions, 2).groupByKey().collect())
| >>> 100 < len(sample["a"]) < 300 and 50 < len(sample["b"]) < 150
| True
| >>> max(sample["a"]) <= 999 and min(sample["a"]) >= 0
| True
| >>> max(sample["b"]) <= 999 and min(sample["b"]) >= 0
| True
|
| sampleStdev(self)
| Compute the sample standard deviation of this RDD‘s elements (which
| corrects for bias in estimating the standard deviation by dividing by
| N-1 instead of N).
|
| >>> sc.parallelize([1, 2, 3]).sampleStdev()
| 1.0
|
| sampleVariance(self)
| Compute the sample variance of this RDD‘s elements (which corrects
| for bias in estimating the variance by dividing by N-1 instead of N).
|
| >>> sc.parallelize([1, 2, 3]).sampleVariance()
| 1.0
|
| saveAsHadoopDataset(self, conf, keyConverter=None, valueConverter=None)
| Output a Python RDD of key-value pairs (of form C{RDD[(K, V)]}) to any Hadoop file
| system, using the old Hadoop OutputFormat API (mapred package). Keys/values are
| converted for output using either user specified converters or, by default,
| L{org.apache.spark.api.python.JavaToWritableConverter}.
|
| :param conf: Hadoop job configuration, passed in as a dict
| :param keyConverter: (None by default)
| :param valueConverter: (None by default)
|
| saveAsHadoopFile(self, path, outputFormatClass, keyClass=None, valueClass=None, keyConverter=None, valueConverter=None, conf=None, compressionCodecClass=None)
| Output a Python RDD of key-value pairs (of form C{RDD[(K, V)]}) to any Hadoop file
| system, using the old Hadoop OutputFormat API (mapred package). Key and value types
| will be inferred if not specified. Keys and values are converted for output using either
| user specified converters or L{org.apache.spark.api.python.JavaToWritableConverter}. The
| C{conf} is applied on top of the base Hadoop conf associated with the SparkContext
| of this RDD to create a merged Hadoop MapReduce job configuration for saving the data.
|
| :param path: path to Hadoop file
| :param outputFormatClass: fully qualified classname of Hadoop OutputFormat
| (e.g. "org.apache.hadoop.mapred.SequenceFileOutputFormat")
| :param keyClass: fully qualified classname of key Writable class
| (e.g. "org.apache.hadoop.io.IntWritable", None by default)
| :param valueClass: fully qualified classname of value Writable class
| (e.g. "org.apache.hadoop.io.Text", None by default)
| :param keyConverter: (None by default)
| :param valueConverter: (None by default)
| :param conf: (None by default)
| :param compressionCodecClass: (None by default)
|
| saveAsNewAPIHadoopDataset(self, conf, keyConverter=None, valueConverter=None)
| Output a Python RDD of key-value pairs (of form C{RDD[(K, V)]}) to any Hadoop file
| system, using the new Hadoop OutputFormat API (mapreduce package). Keys/values are
| converted for output using either user specified converters or, by default,
| L{org.apache.spark.api.python.JavaToWritableConverter}.
|
| :param conf: Hadoop job configuration, passed in as a dict
| :param keyConverter: (None by default)
| :param valueConverter: (None by default)
|
| saveAsNewAPIHadoopFile(self, path, outputFormatClass, keyClass=None, valueClass=None, keyConverter=None, valueConverter=None, conf=None)
| Output a Python RDD of key-value pairs (of form C{RDD[(K, V)]}) to any Hadoop file
| system, using the new Hadoop OutputFormat API (mapreduce package). Key and value types
| will be inferred if not specified. Keys and values are converted for output using either
| user specified converters or L{org.apache.spark.api.python.JavaToWritableConverter}. The
| C{conf} is applied on top of the base Hadoop conf associated with the SparkContext
| of this RDD to create a merged Hadoop MapReduce job configuration for saving the data.
|
| :param path: path to Hadoop file
| :param outputFormatClass: fully qualified classname of Hadoop OutputFormat
| (e.g. "org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat")
| :param keyClass: fully qualified classname of key Writable class
| (e.g. "org.apache.hadoop.io.IntWritable", None by default)
| :param valueClass: fully qualified classname of value Writable class
| (e.g. "org.apache.hadoop.io.Text", None by default)
| :param keyConverter: (None by default)
| :param valueConverter: (None by default)
| :param conf: Hadoop job configuration, passed in as a dict (None by default)
|
| saveAsPickleFile(self, path, batchSize=10)
| Save this RDD as a SequenceFile of serialized objects. The serializer
| used is L{pyspark.serializers.PickleSerializer}, default batch size
| is 10.
|
| >>> tmpFile = NamedTemporaryFile(delete=True)
| >>> tmpFile.close()
| >>> sc.parallelize([1, 2, ‘spark‘, ‘rdd‘]).saveAsPickleFile(tmpFile.name, 3)
| >>> sorted(sc.pickleFile(tmpFile.name, 5).collect())
| [1, 2, ‘rdd‘, ‘spark‘]
|
| saveAsSequenceFile(self, path, compressionCodecClass=None)
| Output a Python RDD of key-value pairs (of form C{RDD[(K, V)]}) to any Hadoop file
| system, using the L{org.apache.hadoop.io.Writable} types that we convert from the
| RDD‘s key and value types. The mechanism is as follows:
|
| 1. Pyrolite is used to convert pickled Python RDD into RDD of Java objects.
| 2. Keys and values of this Java RDD are converted to Writables and written out.
|
| :param path: path to sequence file
| :param compressionCodecClass: (None by default)
|
| saveAsTextFile(self, path, compressionCodecClass=None)
| Save this RDD as a text file, using string representations of elements.
|
| @param path: path to text file
| @param compressionCodecClass: (None by default) string i.e.
| "org.apache.hadoop.io.compress.GzipCodec"
|
| >>> tempFile = NamedTemporaryFile(delete=True)
| >>> tempFile.close()
| >>> sc.parallelize(range(10)).saveAsTextFile(tempFile.name)
| >>> from fileinput import input
| >>> from glob import glob
| >>> ‘‘.join(sorted(input(glob(tempFile.name + "/part-0000*"))))
| ‘0\n1\n2\n3\n4\n5\n6\n7\n8\n9\n‘
|
| Empty lines are tolerated when saving to text files.
|
| >>> tempFile2 = NamedTemporaryFile(delete=True)
| >>> tempFile2.close()
| >>> sc.parallelize([‘‘, ‘foo‘, ‘‘, ‘bar‘, ‘‘]).saveAsTextFile(tempFile2.name)
| >>> ‘‘.join(sorted(input(glob(tempFile2.name + "/part-0000*"))))
| ‘\n\n\nbar\nfoo\n‘
|
| Using compressionCodecClass
|
| >>> tempFile3 = NamedTemporaryFile(delete=True)
| >>> tempFile3.close()
| >>> codec = "org.apache.hadoop.io.compress.GzipCodec"
| >>> sc.parallelize([‘foo‘, ‘bar‘]).saveAsTextFile(tempFile3.name, codec)
| >>> from fileinput import input, hook_compressed
| >>> ‘‘.join(sorted(input(glob(tempFile3.name + "/part*.gz"), openhook=hook_compressed)))
| ‘bar\nfoo\n‘
|
| setName(self, name)
| Assign a name to this RDD.
|
| >>> rdd1 = sc.parallelize([1,2])
| >>> rdd1.setName(‘RDD1‘).name()
| ‘RDD1‘
|
| sortBy(self, keyfunc, ascending=True, numPartitions=None)
| Sorts this RDD by the given keyfunc
|
| >>> tmp = [(‘a‘, 1), (‘b‘, 2), (‘1‘, 3), (‘d‘, 4), (‘2‘, 5)]
| >>> sc.parallelize(tmp).sortBy(lambda x: x[0]).collect()
| [(‘1‘, 3), (‘2‘, 5), (‘a‘, 1), (‘b‘, 2), (‘d‘, 4)]
| >>> sc.parallelize(tmp).sortBy(lambda x: x[1]).collect()
| [(‘a‘, 1), (‘b‘, 2), (‘1‘, 3), (‘d‘, 4), (‘2‘, 5)]
|
| sortByKey(self, ascending=True, numPartitions=None, keyfunc=<function <lambda>>)
| Sorts this RDD, which is assumed to consist of (key, value) pairs.
| # noqa
|
| >>> tmp = [(‘a‘, 1), (‘b‘, 2), (‘1‘, 3), (‘d‘, 4), (‘2‘, 5)]
| >>> sc.parallelize(tmp).sortByKey().first()
| (‘1‘, 3)
| >>> sc.parallelize(tmp).sortByKey(True, 1).collect()
| [(‘1‘, 3), (‘2‘, 5), (‘a‘, 1), (‘b‘, 2), (‘d‘, 4)]
| >>> sc.parallelize(tmp).sortByKey(True, 2).collect()
| [(‘1‘, 3), (‘2‘, 5), (‘a‘, 1), (‘b‘, 2), (‘d‘, 4)]
| >>> tmp2 = [(‘Mary‘, 1), (‘had‘, 2), (‘a‘, 3), (‘little‘, 4), (‘lamb‘, 5)]
| >>> tmp2.extend([(‘whose‘, 6), (‘fleece‘, 7), (‘was‘, 8), (‘white‘, 9)])
| >>> sc.parallelize(tmp2).sortByKey(True, 3, keyfunc=lambda k: k.lower()).collect()
| [(‘a‘, 3), (‘fleece‘, 7), (‘had‘, 2), (‘lamb‘, 5),...(‘white‘, 9), (‘whose‘, 6)]
|
| stats(self)
| Return a L{StatCounter} object that captures the mean, variance
| and count of the RDD‘s elements in one operation.
|
| stdev(self)
| Compute the standard deviation of this RDD‘s elements.
|
| >>> sc.parallelize([1, 2, 3]).stdev()
| 0.816...
|
| subtract(self, other, numPartitions=None)
| Return each value in C{self} that is not contained in C{other}.
|
| >>> x = sc.parallelize([("a", 1), ("b", 4), ("b", 5), ("a", 3)])
| >>> y = sc.parallelize([("a", 3), ("c", None)])
| >>> sorted(x.subtract(y).collect())
| [(‘a‘, 1), (‘b‘, 4), (‘b‘, 5)]
|
| subtractByKey(self, other, numPartitions=None)
| Return each (key, value) pair in C{self} that has no pair with matching
| key in C{other}.
|
| >>> x = sc.parallelize([("a", 1), ("b", 4), ("b", 5), ("a", 2)])
| >>> y = sc.parallelize([("a", 3), ("c", None)])
| >>> sorted(x.subtractByKey(y).collect())
| [(‘b‘, 4), (‘b‘, 5)]
|
| sum(self)
| Add up the elements in this RDD.
|
| >>> sc.parallelize([1.0, 2.0, 3.0]).sum()
| 6.0
|
| sumApprox(self, timeout, confidence=0.95)
| .. note:: Experimental
|
| Approximate operation to return the sum within a timeout
| or meet the confidence.
|
| >>> rdd = sc.parallelize(range(1000), 10)
| >>> r = sum(xrange(1000))
| >>> (rdd.sumApprox(1000) - r) / r < 0.05
| True
|
| take(self, num)
| Take the first num elements of the RDD.
|
| It works by first scanning one partition, and use the results from
| that partition to estimate the number of additional partitions needed
| to satisfy the limit.
|
| Translated from the Scala implementation in RDD#take().
|
| >>> sc.parallelize([2, 3, 4, 5, 6]).cache().take(2)
| [2, 3]
| >>> sc.parallelize([2, 3, 4, 5, 6]).take(10)
| [2, 3, 4, 5, 6]
| >>> sc.parallelize(range(100), 100).filter(lambda x: x > 90).take(3)
| [91, 92, 93]
|
| takeOrdered(self, num, key=None)
| Get the N elements from a RDD ordered in ascending order or as
| specified by the optional key function.
|
| >>> sc.parallelize([10, 1, 2, 9, 3, 4, 5, 6, 7]).takeOrdered(6)
| [1, 2, 3, 4, 5, 6]
| >>> sc.parallelize([10, 1, 2, 9, 3, 4, 5, 6, 7], 2).takeOrdered(6, key=lambda x: -x)
| [10, 9, 7, 6, 5, 4]
|
| takeSample(self, withReplacement, num, seed=None)
| Return a fixed-size sampled subset of this RDD.
|
| >>> rdd = sc.parallelize(range(0, 10))
| >>> len(rdd.takeSample(True, 20, 1))
| 20
| >>> len(rdd.takeSample(False, 5, 2))
| 5
| >>> len(rdd.takeSample(False, 15, 3))
| 10
|
| toDF(self, schema=None, sampleRatio=None)
| Converts current :class:`RDD` into a :class:`DataFrame`
|
| This is a shorthand for ``sqlContext.createDataFrame(rdd, schema, sampleRatio)``
|
| :param schema: a StructType or list of names of columns
| :param samplingRatio: the sample ratio of rows used for inferring
| :return: a DataFrame
|
| >>> rdd.toDF().collect()
| [Row(name=u‘Alice‘, age=1)]
|
| toDebugString(self)
| A description of this RDD and its recursive dependencies for debugging.
|
| toLocalIterator(self)
| Return an iterator that contains all of the elements in this RDD.
| The iterator will consume as much memory as the largest partition in this RDD.
| >>> rdd = sc.parallelize(range(10))
| >>> [x for x in rdd.toLocalIterator()]
| [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
|
| top(self, num, key=None)
| Get the top N elements from a RDD.
|
| Note: It returns the list sorted in descending order.
|
| >>> sc.parallelize([10, 4, 2, 12, 3]).top(1)
| [12]
| >>> sc.parallelize([2, 3, 4, 5, 6], 2).top(2)
| [6, 5]
| >>> sc.parallelize([10, 4, 2, 12, 3]).top(3, key=str)
| [4, 3, 2]
|
| treeAggregate(self, zeroValue, seqOp, combOp, depth=2)
| Aggregates the elements of this RDD in a multi-level tree
| pattern.
|
| :param depth: suggested depth of the tree (default: 2)
|
| >>> add = lambda x, y: x + y
| >>> rdd = sc.parallelize([-5, -4, -3, -2, -1, 1, 2, 3, 4], 10)
| >>> rdd.treeAggregate(0, add, add)
| -5
| >>> rdd.treeAggregate(0, add, add, 1)
| -5
| >>> rdd.treeAggregate(0, add, add, 2)
| -5
| >>> rdd.treeAggregate(0, add, add, 5)
| -5
| >>> rdd.treeAggregate(0, add, add, 10)
| -5
|
| treeReduce(self, f, depth=2)
| Reduces the elements of this RDD in a multi-level tree pattern.
|
| :param depth: suggested depth of the tree (default: 2)
|
| >>> add = lambda x, y: x + y
| >>> rdd = sc.parallelize([-5, -4, -3, -2, -1, 1, 2, 3, 4], 10)
| >>> rdd.treeReduce(add)
| -5
| >>> rdd.treeReduce(add, 1)
| -5
| >>> rdd.treeReduce(add, 2)
| -5
| >>> rdd.treeReduce(add, 5)
| -5
| >>> rdd.treeReduce(add, 10)
| -5
|
| union(self, other)
| Return the union of this RDD and another one.
|
| >>> rdd = sc.parallelize([1, 1, 2, 3])
| >>> rdd.union(rdd).collect()
| [1, 1, 2, 3, 1, 1, 2, 3]
|
| unpersist(self)
| Mark the RDD as non-persistent, and remove all blocks for it from
| memory and disk.
|
| values(self)
| Return an RDD with the values of each tuple.
|
| >>> m = sc.parallelize([(1, 2), (3, 4)]).values()
| >>> m.collect()
| [2, 4]
|
| variance(self)
| Compute the variance of this RDD‘s elements.
|
| >>> sc.parallelize([1, 2, 3]).variance()
| 0.666...
|
| zip(self, other)
| Zips this RDD with another one, returning key-value pairs with the
| first element in each RDD second element in each RDD, etc. Assumes
| that the two RDDs have the same number of partitions and the same
| number of elements in each partition (e.g. one was made through
| a map on the other).
|
| >>> x = sc.parallelize(range(0,5))
| >>> y = sc.parallelize(range(1000, 1005))
| >>> x.zip(y).collect()
| [(0, 1000), (1, 1001), (2, 1002), (3, 1003), (4, 1004)]
|
| zipWithIndex(self)
| Zips this RDD with its element indices.
|
| The ordering is first based on the partition index and then the
| ordering of items within each partition. So the first item in
| the first partition gets index 0, and the last item in the last
| partition receives the largest index.
|
| This method needs to trigger a spark job when this RDD contains
| more than one partitions.
|
| >>> sc.parallelize(["a", "b", "c", "d"], 3).zipWithIndex().collect()
| [(‘a‘, 0), (‘b‘, 1), (‘c‘, 2), (‘d‘, 3)]
|
| zipWithUniqueId(self)
| Zips this RDD with generated unique Long ids.
|
| Items in the kth partition will get ids k, n+k, 2*n+k, ..., where
| n is the number of partitions. So there may exist gaps, but this
| method won‘t trigger a spark job, which is different from
| L{zipWithIndex}
|
| >>> sc.parallelize(["a", "b", "c", "d", "e"], 3).zipWithUniqueId().collect()
| [(‘a‘, 0), (‘b‘, 1), (‘c‘, 4), (‘d‘, 2), (‘e‘, 5)]
|
| ----------------------------------------------------------------------
| Data descriptors inherited from RDD:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
|
| context
| The L{SparkContext} that this RDD was created on.
# Let‘s see how many partitions the RDD will be split into by using the getNumPartitions()
xrangeRDD.getNumPartitions()
8
mapmap(f), the most common Spark transformation, is one such example: it applies a function f to each item in the dataset, and outputs the resulting dataset. When you run map() on a dataset, a single stage of tasks is launched. A stage is a group of tasks that all perform the same computation, but on different input data. One task is launched for each partitition, as shown in the example below. A task is a unit of execution that runs on a single machine. When we run map(f) within a partition, a new task applies f to all of the entries in a particular partition, and outputs a new partition. In this example figure, the dataset is broken into four partitions, so four map() tasks are launched.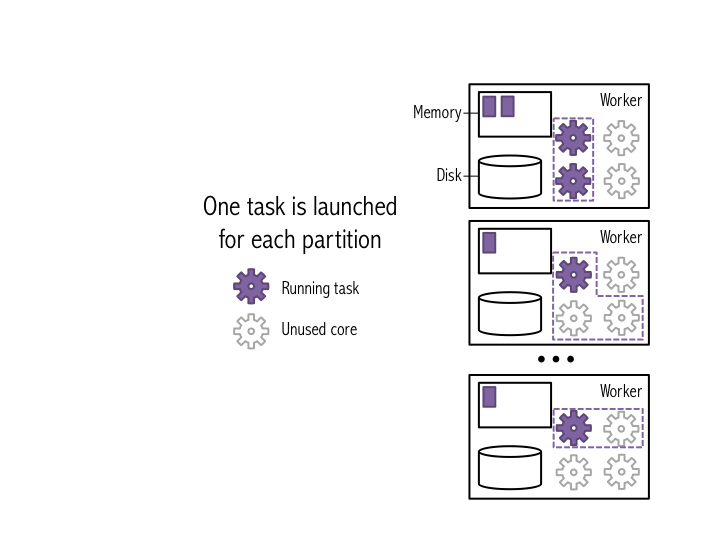
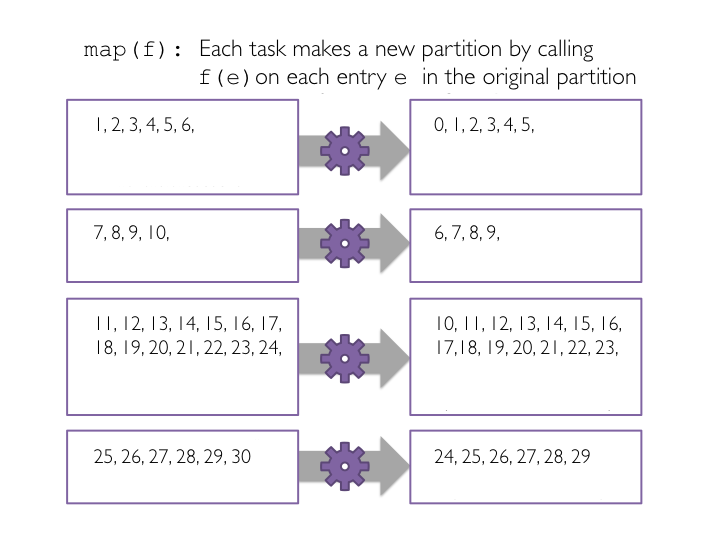
map() transformation, each item in the parent RDD will map to one element in the new RDD. So, if the parent RDD has twenty elements, the new RDD will also have twenty items.map() to subtract one from each value in the base RDD we just created. First, we define a Python function called sub() that will subtract one from the input integer. Second, we will pass each item in the base RDD into a map() transformation that applies the sub() function to each element. And finally, we print out the RDD transformation hierarchy using toDebugString().# Create sub function to subtract 1
def sub(value):
""""Subtracts one from `value`.
Args:
value (int): A number.
Returns:
int: `value` minus one.
"""
return (value - 1)
# Transform xrangeRDD through map transformation using sub function
# Because map is a transformation and Spark uses lazy evaluation, no jobs, stages,
# or tasks will be launched when we run this code.
subRDD = xrangeRDD.map(sub)
# Let‘s see the RDD transformation hierarchy
print subRDD.toDebugString()
(8) PythonRDD[3] at RDD at PythonRDD.scala:43 []
| ParallelCollectionRDD[0] at parallelize at PythonRDD.scala:392 []
collect to view results *collect() method on our RDD. collect() is often used after a filter or other operation to ensure that we are only returning a small amount of data to the driver. This is done because the data returned to the driver must fit into the driver’s available memory. If not, the driver will crash.collect() method is the first action operation that we have encountered. Action operations cause Spark to perform the (lazy) transformation operations that are required to compute the RDD returned by the action. In our example, this means that tasks will now be launched to perform the parallelize, map, and collect operations.collect() tasks are launched. Each task collects the entries in its partition and sends the result to the SparkContext, which creates a list of the values, as shown in the figure below.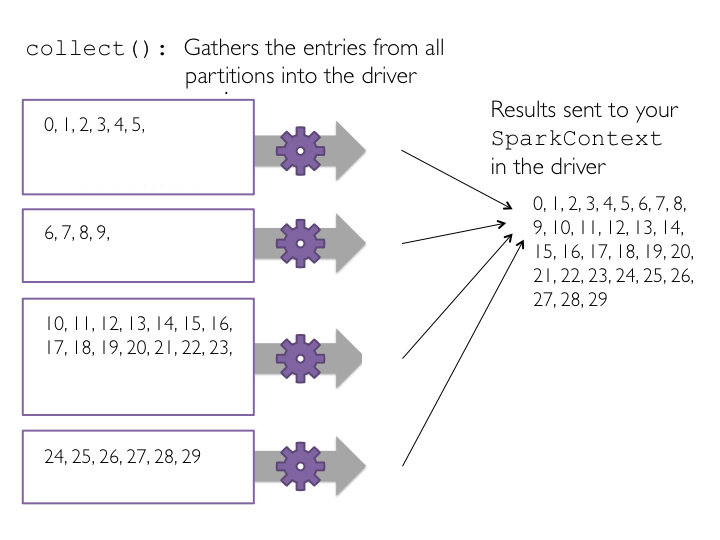
collect() on a small example dataset with just four partitions.collect() on subRDD.# Let‘s collect the data
print subRDD.collect()
#### * (3d) Perform action count to view counts *
count() job which will count the number of elements in an RDD using the count() action. Since map() creates a new RDD with the same number of elements as the starting RDD, we expect that applying count() to each RDD will return the same result.count() is an action operation, if we had not already performed an action with collect(), then Spark would now perform the transformation operations when we executed count().count() on a small example dataset with just four partitions.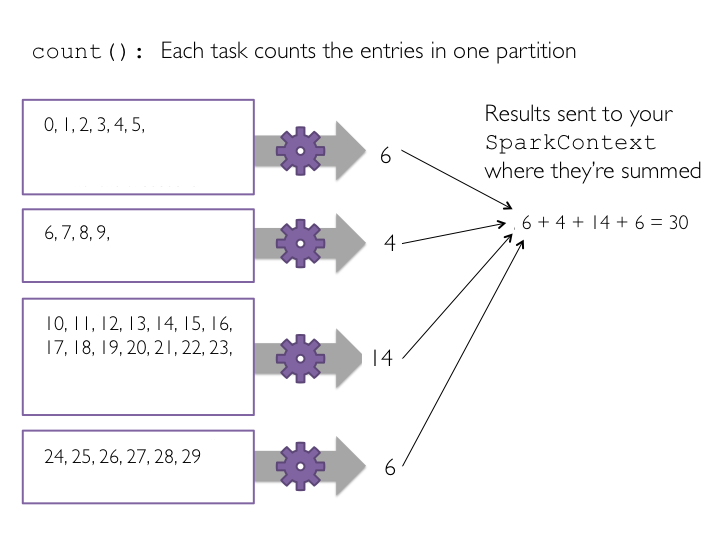
print xrangeRDD.count()
print subRDD.count()
10000
10000
filter and view results with collect *filter(f) data-parallel operation. The filter(f) method is a transformation operation that creates a new RDD from the input RDD by applying filter function f to each item in the parent RDD and only passing those elements where the filter function returns True. Elements that do not return True will be dropped. Like map(), filter can be applied individually to each entry in the dataset, so is easily parallelized using Spark.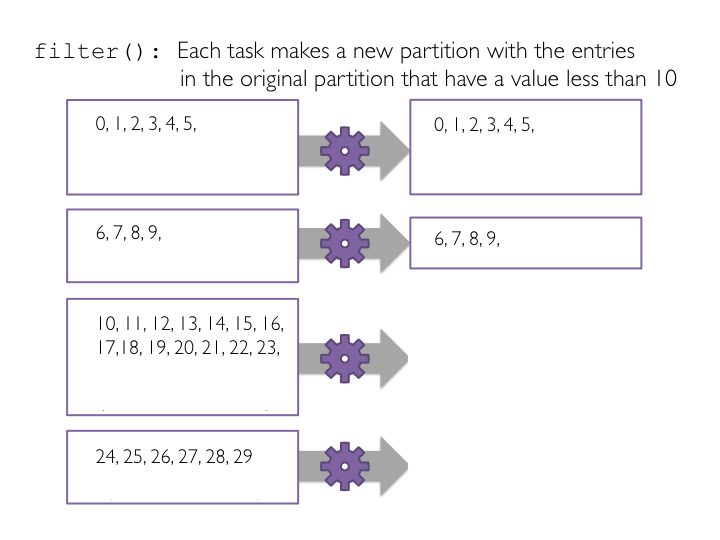
ten(), which returns True if the input is less than 10 and False otherwise. This function will be passed to the filter() transformation as the filter function f.collect() method to return a list that contains all of the elements in this filtered RDD to the driver program.# Define a function to filter a single value
def ten(value):
"""Return whether value is below ten.
Args:
value (int): A number.
Returns:
bool: Whether `value` is less than ten.
"""
if (value < 10):
return True
else:
return False
# The ten function could also be written concisely as: def ten(value): return value < 10
# Pass the function ten to the filter transformation
# Filter is a transformation so no tasks are run
filteredRDD = subRDD.filter(ten)
# View the results using collect()
# Collect is an action and triggers the filter transformation to run
print filteredRDD.collect()
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
lambda() functions *lambda functions can be used wherever function objects are required. They are syntactically restricted to a single expression. Remember that lambda functions are a matter of style and using them is never required - semantically, they are just syntactic sugar for a normal function definition. You can always define a separate normal function instead, but using a lambda() function is an equivalent and more compact form of coding. Ideally you should consider using lambda functions where you want to encapsulate non-reusable code without littering your code with one-line functions.filter() transformation, we will use an inline lambda() function.lambdaRDD = subRDD.filter(lambda x: x < 10)
lambdaRDD.collect()
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# Let‘s collect the even values less than 10
evenRDD = lambdaRDD.filter(lambda x: x % 2 == 0)
evenRDD.collect()
[0, 2, 4, 6, 8]
first(), take(), top(), and takeOrdered() actions. Note that for the first() and take() actions, the elements that are returned depend on how the RDD is partitioned.collect() action, we can use the take(n) action to return the first n elements of the RDD. The first() action returns the first element of an RDD, and is equivalent to take(1).takeOrdered() action returns the first n elements of the RDD, using either their natural order or a custom comparator. The key advantage of using takeOrdered() instead of first() or take() is that takeOrdered() returns a deterministic result, while the other two actions may return differing results, depending on the number of partions or execution environment. takeOrdered() returns the list sorted in ascending order. The top() action is similar to takeOrdered() except that it returns the list in descending order.reduce() action reduces the elements of a RDD to a single value by applying a function that takes two parameters and returns a single value. The function should be commutative and associative, as reduce() is applied at the partition level and then again to aggregate results from partitions. If these rules don’t hold, the results from reduce() will be inconsistent. Reducing locally at partitions makes reduce() very efficient.# Let‘s get the first element
print filteredRDD.first()
# The first 4
print filteredRDD.take(4)
# Note that it is ok to take more elements than the RDD has
print filteredRDD.take(12)
0
[0, 1, 2, 3]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# Retrieve the three smallest elements
print filteredRDD.takeOrdered(3)
# Retrieve the five largest elements
print filteredRDD.top(5)
[0, 1, 2]
[9, 8, 7, 6, 5]
# Pass a lambda function to takeOrdered to reverse the order
filteredRDD.takeOrdered(4, lambda s: -s)
[9, 8, 7, 6]
# Obtain Python‘s add function
from operator import add
# Efficiently sum the RDD using reduce
print filteredRDD.reduce(add)
# Sum using reduce with a lambda function
print filteredRDD.reduce(lambda a, b: a + b)
# Note that subtraction is not both associative and commutative
print filteredRDD.reduce(lambda a, b: a - b)
print filteredRDD.repartition(4).reduce(lambda a, b: a - b)
# While addition is
print filteredRDD.repartition(4).reduce(lambda a, b: a + b)
45
45
-45
21
45
print filteredRDD.repartition(4).glom().collect()
[[1, 2], [3, 4, 5, 6], [7, 8, 9], [0]]
takeSample() action returns an array with a random sample of elements from the dataset. It takes in a withReplacement argument, which specifies whether it is okay to randomly pick the same item multiple times from the parent RDD (so when withReplacement=True, you can get the same item back multiple times). It also takes an optional seed parameter that allows you to specify a seed value for the random number generator, so that reproducible results can be obtained.countByValue() action returns the count of each unique value in the RDD as a dictionary that maps values to counts.# takeSample reusing elements
print filteredRDD.takeSample(withReplacement=True, num=6)
# takeSample without reuse
print filteredRDD.takeSample(withReplacement=False, num=6)
[5, 2, 8, 3, 3, 1]
[0, 1, 3, 6, 5, 9]
# Set seed for predictability
print filteredRDD.takeSample(withReplacement=False, num=6, seed=500)
# Try reruning this cell and the cell above -- the results from this cell will remain constant
# Use ctrl-enter to run without moving to the next cell
[0, 2, 5, 3, 6, 9]
# Create new base RDD to show countByValue
repetitiveRDD = sc.parallelize([1, 2, 3, 1, 2, 3, 1, 2, 1, 2, 3, 3, 3, 4, 5, 4, 6])
print repetitiveRDD.countByValue()
defaultdict(<type ‘int‘>, {1: 4, 2: 4, 3: 5, 4: 2, 5: 1, 6: 1})
flatMap *map() transformation using a function, sometimes the function will return more (or less) than one element. We would like the newly created RDD to consist of the elements outputted by the function. Simply applying a map() transformation would yield a new RDD made up of iterators. Each iterator could have zero or more elements. Instead, we often want an RDD consisting of the values contained in those iterators. The solution is to use a flatMap() transformation, flatMap() is similar to map(), except that with flatMap() each input item can be mapped to zero or more output elements.flatMap(), we will first emit a word along with its plural, and then a range that grows in length with each subsequent operation.# Let‘s create a new base RDD to work from
wordsList = [‘cat‘, ‘elephant‘, ‘rat‘, ‘rat‘, ‘cat‘]
wordsRDD = sc.parallelize(wordsList, 4)
# Use map
singularAndPluralWordsRDDMap = wordsRDD.map(lambda x: (x, x + ‘s‘))
# Use flatMap
singularAndPluralWordsRDD = wordsRDD.flatMap(lambda x: (x, x + ‘s‘))
# View the results
print singularAndPluralWordsRDDMap.collect()
print singularAndPluralWordsRDD.collect()
# View the number of elements in the RDD
print singularAndPluralWordsRDDMap.count()
print singularAndPluralWordsRDD.count()
[(‘cat‘, ‘cats‘), (‘elephant‘, ‘elephants‘), (‘rat‘, ‘rats‘), (‘rat‘, ‘rats‘), (‘cat‘, ‘cats‘)]
[‘cat‘, ‘cats‘, ‘elephant‘, ‘elephants‘, ‘rat‘, ‘rats‘, ‘rat‘, ‘rats‘, ‘cat‘, ‘cats‘]
5
10
simpleRDD = sc.parallelize([2, 3, 4])
print simpleRDD.map(lambda x: range(1, x)).collect()
print simpleRDD.flatMap(lambda x: range(1, x)).collect()
[[1], [1, 2], [1, 2, 3]]
[1, 1, 2, 1, 2, 3]
groupByKey and reduceByKey *sc.parallelize([(‘a‘, 1), (‘a‘, 2), (‘b‘, 1)]) would create a pair RDD where the keys are ‘a’, ‘a’, ‘b’ and the values are 1, 2, 1.reduceByKey() transformation gathers together pairs that have the same key and applies a function to two associated values at a time. reduceByKey() operates by applying the function first within each partition on a per-key basis and then across the partitions.groupByKey() and reduceByKey() transformations can often be used to solve the same problem and will produce the same answer, the reduceByKey() transformation works much better for large distributed datasets. This is because Spark knows it can combine output with a common key on each partition before shuffling (redistributing) the data across nodes. Only use groupByKey() if the operation would not benefit from reducing the data before the shuffle occurs.reduceByKey works. Notice how pairs on the same machine with the same key are combined (by using the lamdba function passed into reduceByKey) before the data is shuffled. Then the lamdba function is called again to reduce all the values from each partition to produce one final result.
groupByKey() transformation - all the key-value pairs are shuffled around, causing a lot of unnecessary data to being transferred over the network.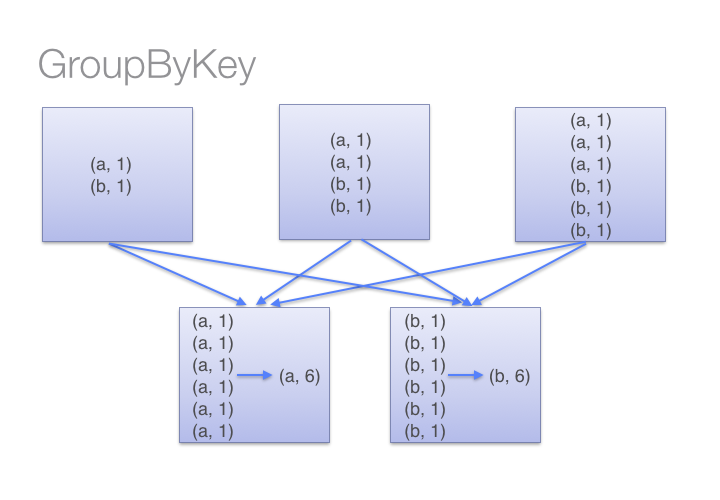
reduceByKey() and groupByKey() transformations, becomes increasingly exaggerated.groupByKey():groupByKey() and reduceByKey() example.pairRDD = sc.parallelize([(‘a‘, 1), (‘a‘, 2), (‘b‘, 1)])
# mapValues only used to improve format for printing
print pairRDD.groupByKey().mapValues(lambda x: list(x)).collect()
# Different ways to sum by key
print pairRDD.groupByKey().map(lambda (k, v): (k, sum(v))).collect()
# Using mapValues, which is recommended when they key doesn‘t change
print pairRDD.groupByKey().mapValues(lambda x: sum(x)).collect()
# reduceByKey is more efficient / scalable
print pairRDD.reduceByKey(add).collect()
[(‘a‘, [1, 2]), (‘b‘, [1])]
[(‘a‘, 3), (‘b‘, 1)]
[(‘a‘, 3), (‘b‘, 1)]
[(‘a‘, 3), (‘b‘, 1)]
mapPartitions() transformation uses a function that takes in an iterator (to the items in that specific partition) and returns an iterator. The function is applied on a partition by partition basis.mapPartitionsWithIndex() transformation uses a function that takes in a partition index (think of this like the partition number) and an iterator (to the items in that specific partition). For every partition (index, iterator) pair, the function returns a tuple of the same partition index number and an iterator of the transformed items in that partition.# mapPartitions takes a function that takes an iterator and returns an iterator
print wordsRDD.collect()
print wordsRDD.glom().collect()
itemsRDD = wordsRDD.mapPartitions(lambda iterator: [‘,‘.join(iterator)])
print itemsRDD.collect()
[‘cat‘, ‘elephant‘, ‘rat‘, ‘rat‘, ‘cat‘]
[[‘cat‘], [‘elephant‘], [‘rat‘], [‘rat‘, ‘cat‘]]
[‘cat‘, ‘elephant‘, ‘rat‘, ‘rat,cat‘]
itemsByPartRDD = wordsRDD.mapPartitionsWithIndex(lambda index, iterator: [(index, list(iterator))])
# We can see that three of the (partitions) workers have one element and the fourth worker has two
# elements, although things may not bode well for the rat...
print itemsByPartRDD.collect()
# Rerun without returning a list (acts more like flatMap)
itemsByPartRDD = wordsRDD.mapPartitionsWithIndex(lambda index, iterator: (index, list(iterator)))
print itemsByPartRDD.collect()
[(0, [‘cat‘]), (1, [‘elephant‘]), (2, [‘rat‘]), (3, [‘rat‘, ‘cat‘])]
[0, [‘cat‘], 1, [‘elephant‘], 2, [‘rat‘], 3, [‘rat‘, ‘cat‘]]
cache() operation to keep the RDD in memory. However, if you cache too many RDDs and Spark runs out of memory, it will delete the least recently used (LRU) RDD first. Again, the RDD will be automatically recreated when accessed.is_cached attribute, and you can see your cached RDD in the “Storage” section of the Spark web UI. If you click on the RDD’s name, you can see more information about where the RDD is stored.# Name the RDD
filteredRDD.setName(‘My Filtered RDD‘)
# Cache the RDD
filteredRDD.cache()
# Is it cached
print filteredRDD.is_cached
True
unpersist() method to inform Spark that you no longer need the RDD in memory.toDebugString() method, which will provide storage information, and you can directly query the current storage information for an RDD using the getStorageLevel() operation.persist() operation, optionally, takes a pySpark StorageLevel object.# Note that toDebugString also provides storage information
print filteredRDD.toDebugString()
(8) My Filtered RDD PythonRDD[6] at collect at <ipython-input-26-2e6525e1a0c2>:23 [Memory Serialized 1x Replicated]
| ParallelCollectionRDD[0] at parallelize at PythonRDD.scala:392 [Memory Serialized 1x Replicated]
# If we are done with the RDD we can unpersist it so that its memory can be reclaimed
filteredRDD.unpersist()
# Storage level for a non cached RDD
print filteredRDD.getStorageLevel()
filteredRDD.cache()
# Storage level for a cached RDD
print filteredRDD.getStorageLevel()
Serialized 1x Replicated
Memory Serialized 1x Replicated
filter() operation using the broken filtering function. No error will occur at this point due to Spark’s use of lazy evaluation.filter() method will not be executed until an action operation is invoked on the RDD. We will perform an action by using the collect() method to return a list that contains all of the elements in this RDD.def brokenTen(value):
"""Incorrect implementation of the ten function.
Note:
The `if` statement checks an undefined variable `val` instead of `value`.
Args:
value (int): A number.
Returns:
bool: Whether `value` is less than ten.
Raises:
NameError: The function references `val`, which is not available in the local or global
namespace, so a `NameError` is raised.
"""
if (val < 10):
return True
else:
return False
brokenRDD = subRDD.filter(brokenTen)
# Now we‘ll see the error
brokenRDD.collect()
---------------------------------------------------------------------------
Py4JJavaError Traceback (most recent call last)
<ipython-input-56-c7025769b408> in <module>()
1 # Now we‘ll see the error
----> 2 brokenRDD.collect()
/usr/local/bin/spark-1.3.1-bin-hadoop2.6/python/pyspark/rdd.py in collect(self)
711 """
712 with SCCallSiteSync(self.context) as css:
--> 713 port = self.ctx._jvm.PythonRDD.collectAndServe(self._jrdd.rdd())
714 return list(_load_from_socket(port, self._jrdd_deserializer))
715
/usr/local/bin/spark-1.3.1-bin-hadoop2.6/python/lib/py4j-0.8.2.1-src.zip/py4j/java_gateway.py in __call__(self, *args)
536 answer = self.gateway_client.send_command(command)
537 return_value = get_return_value(answer, self.gateway_client,
--> 538 self.target_id, self.name)
539
540 for temp_arg in temp_args:
/usr/local/bin/spark-1.3.1-bin-hadoop2.6/python/lib/py4j-0.8.2.1-src.zip/py4j/protocol.py in get_return_value(answer, gateway_client, target_id, name)
298 raise Py4JJavaError(
299 ‘An error occurred while calling {0}{1}{2}.\n‘.
--> 300 format(target_id, ‘.‘, name), value)
301 else:
302 raise Py4JError(
Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 68.0 failed 1 times, most recent failure: Lost task 0.0 in stage 68.0 (TID 341, localhost): org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "/usr/local/bin/spark-1.3.1-bin-hadoop2.6/python/pyspark/worker.py", line 101, in main
process()
File "/usr/local/bin/spark-1.3.1-bin-hadoop2.6/python/pyspark/worker.py", line 96, in process
serializer.dump_stream(func(split_index, iterator), outfile)
File "/usr/local/bin/spark-1.3.1-bin-hadoop2.6/python/pyspark/serializers.py", line 236, in dump_stream
vs = list(itertools.islice(iterator, batch))
File "<ipython-input-55-775c9f3488e3>", line 17, in brokenTen
NameError: global name ‘val‘ is not defined
at org.apache.spark.api.python.PythonRDD$$anon$1.read(PythonRDD.scala:135)
at org.apache.spark.api.python.PythonRDD$$anon$1.<init>(PythonRDD.scala:176)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:94)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:277)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:244)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:61)
at org.apache.spark.scheduler.Task.run(Task.scala:64)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:203)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.org$apache$spark$scheduler$DAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1204)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1193)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$abortStage$1.apply(DAGScheduler.scala:1192)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1192)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:693)
at org.apache.spark.scheduler.DAGScheduler$$anonfun$handleTaskSetFailed$1.apply(DAGScheduler.scala:693)
at scala.Option.foreach(Option.scala:236)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:693)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1393)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1354)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48)
filter() method is executed, Spark evaluates the RDD by executing the parallelize() and filter() methods. Since our filter() method has an error in the filtering function brokenTen(), an error occurs.collect() method line. There is nothing wrong with this line. However, it is an action and that caused other methods to be executed. Continue scrolling through the Traceback and you will see the following error line:NameError: global name ‘val‘ is not defined
brokenTen().RDD.transformation1()
RDD.action1()
RDD.transformation2()
RDD.action2()
RDD.transformation1().transformation2().action()
lambda() functions instead of separately defined functions when their use improves readability and conciseness.# Cleaner code through lambda use
subRDD.filter(lambda x: x < 10).collect()
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# Even better by moving our chain of operators into a single line.
sc.parallelize(data).map(lambda y: y - 1).filter(lambda x: x < 10).collect()
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# Final version
(sc
.parallelize(data)
.map(lambda y: y - 1)
.filter(lambda x: x < 10)
.collect())
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
[pySpark][笔记]spark tutorial from spark official site在ipython notebook 下学习pySpark
原文地址:http://blog.csdn.net/myjiayan/article/details/46405817