标签:
问题由来是这样的,今天帮一个网友解决问题,说从VC驿站下载了一个源码,程序的功能主要是在对话框上面放置了一个WebBrowser控件,程序启动的时候默认调用这句代码:
m_web.Navigate(_T("https://www.baidu.com/s?wd=400电话"), NULL, NULL, NULL, NULL);
打开这个网址:
https://www.baidu.com/s?wd=400电话,如下图: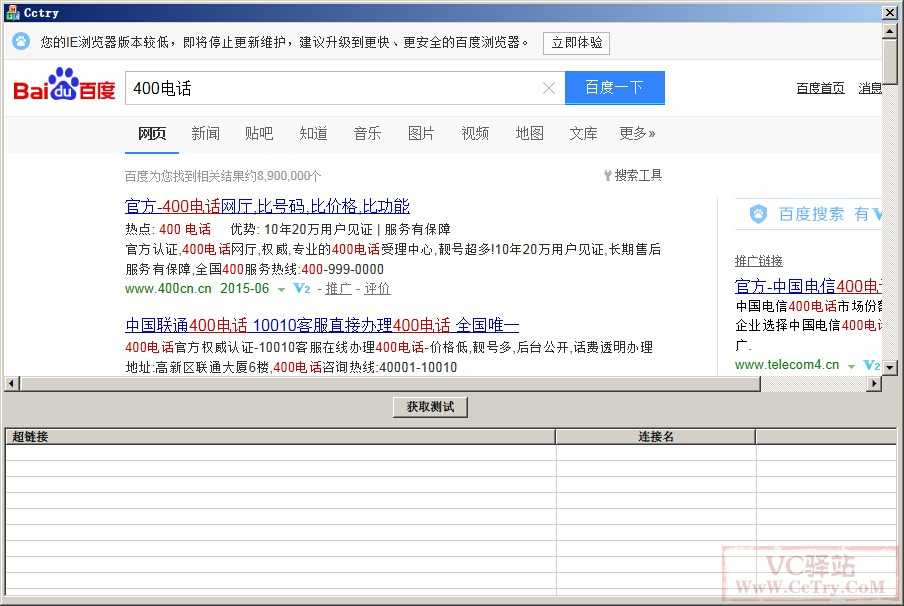
点击【获取测试】按钮之后,执行如下函数:
1 void CCctryDlg::OnBnClickedButton1() 2 { 3 CComQIPtr <IHTMLDocument2, &IID_IHTMLDocument2> spDoc1 = m_web.get_Document(); 4 IHTMLDocument3 *pDoc3 = NULL; 5 HRESULT hr = spDoc1->QueryInterface(IID_IHTMLDocument3, (void **)&pDoc3); 6 if (!pDoc3 && FAILED(hr)) return; 7 CComPtr <IHTMLElement> pUserElement; 8 CComBSTR idName(CT2OLE(_T("kw"))); //获取编辑框元素ID 9 hr = pDoc3->getElementById(idName, &pUserElement); 10 if (FAILED(hr) ||!pUserElement) return; 11 pUserElement->put_innerText(CComBSTR("新网页")); //写入字符串 12 CComPtr <IHTMLElement> pBtnElement; 13 CComBSTR idBtnName(CT2OLE(_T("su")));//获取表单按钮的元素ID 14 hr = pDoc3->getElementById(idBtnName, &pBtnElement); 15 if (FAILED(hr) || !pBtnElement) return; 16 pBtnElement->click(); //模拟点击百度按钮进行搜索 17 //---------------------------------------------------------------------------------- 18 //获取点击百度按钮之后的所有链接 19 Sleep(5000); //加载完毕新打开的网页 20 //再次重新获取,但是得到的链接还是原来400电话里面的,而不是新网页里的。 21 CComQIPtr <IHTMLDocument2, &IID_IHTMLDocument2> spDoc2 = m_web.get_Document(); 22 GetAllLinks(spDoc2); 23 }
简单解释一下:就是获取百度搜索框的接口,之后向里面输入关键字:“新网页”,之后再获取【百度一下】按钮的接口,调用这句话 pBtnElement->click(); 进行点击事件的触发,说白了,就是在当前页面中搜索 “新网页” 这个关键字。
之后,调用 Sleep(5000); 等待一会新页面加载完成,再次调用 m_web.get_Document(); 获取当前网页的 document 文档接口,然后调用 GetAllLinks(spDoc2); 函数分析出当前页面的所有搜索结果的URL链接,显示在软件下面的列表中,如下图: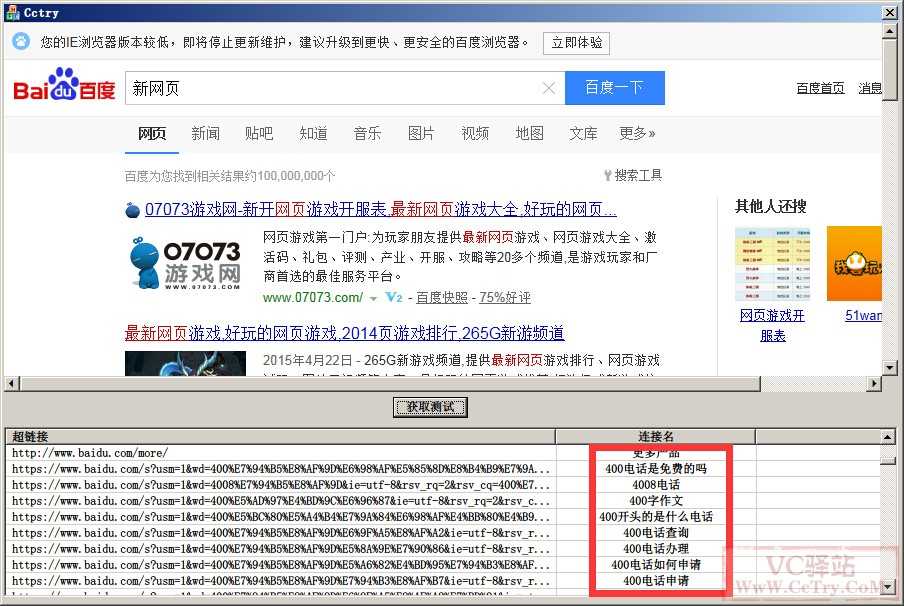
但是,问题来了,大家仔细看上面的图,列表中显示的URL链接都是上一个网址搜索 “400电话” 关键字的结果,不是之后搜索的关键字 “新网页” 的网址链接,这是怎么回事儿呢?跟我们要的结果不一致啊。。。
我还特意调用了 Sleep(5000),等待了 5 秒钟 呢,怎么结果还是不对?
于是乎。。。东奔西走,谷歌搜索了一大堆,还是没找到结果,到微软官方MSDN也没发现什么猫腻,到底是怎么回事儿呢,正准备要放弃的时候,忽然灵感来了,想一想,WebBrowser 走的是当前的主界面的 UI 线程,所以,他访问网页的过程也是在这个主界面的线程中来执行的,那么我们 Sleep(5000); 就没有意义了,不仅会卡住主界面线程,也同时会卡住 WebBrowser。当程序调用完 GetAllLinks(spDoc2); 这条语句之后可能新页面还没加载完,所以获取子链接的结果肯定是上一个页面的。
于是按照这一思想,我把【获取测试】按钮响应函数中的以下几句话注释掉:
Sleep(5000); //加载完毕新打开的网页 CComQIPtr <IHTMLDocument2, &IID_IHTMLDocument2> spDoc2 = m_web.get_Document(); GetAllLinks(spDoc2);
即,不让他 Sleep 了,也不让他在当前的这个按钮的响应函数中去获取新页面中所有的子链接,直接触发【百度一下】按钮点击事件之后就完事儿了。
接着,我再界面上再添加一个按钮,命名为【再测试下】,在这个按钮的响应函数中添加如下代码:
CComQIPtr <IHTMLDocument2, &IID_IHTMLDocument2> spDoc2 = m_web.get_Document();
GetAllLinks(spDoc2);
即,在这个【再测试下】按钮的响应函数中进行获取新页面中的所有子链接,看看能否成功!结果呢?哈哈,当然是成功啦,如下图: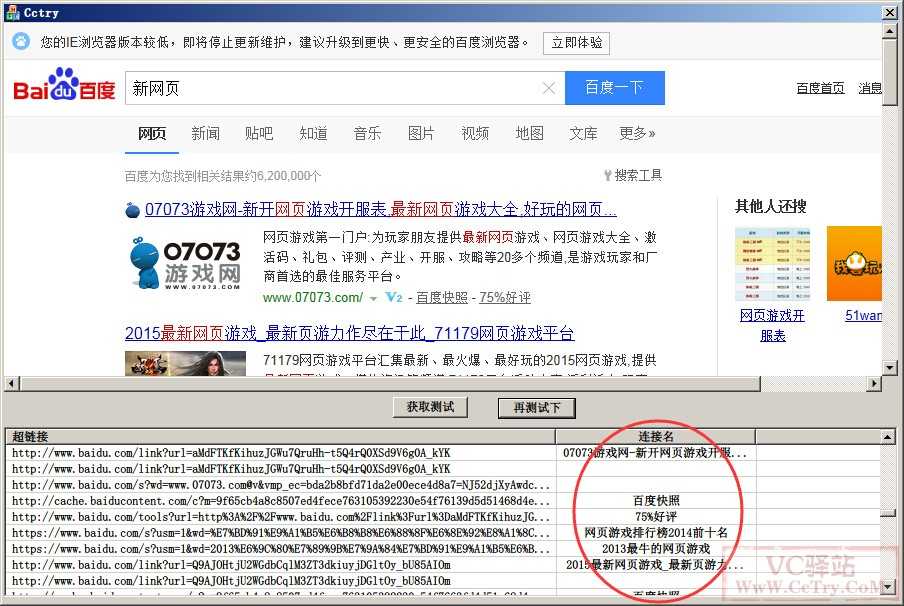
看到了吧,这回列表中显示的已经是新页面的网页子链接了。。。
好了,文章就写到这吧,希望其他遇到相同问题的网友看到这篇文章,少走弯路!
相关工程源码下载见:http://www.cctry.com/thread-254314-1-1.html
WebBrowser之获取跳转页面的Document接口源码
标签:
原文地址:http://www.cnblogs.com/cctrys/p/4564448.html