标签:
检索模型与搜索排序
搜索结果排序是搜索引擎最核心的构成部分,很大程度上决定了搜索引擎的质量好坏以及用户接受与否。尽管搜索引擎在实际结果排序时融合了上百种排序因子,但最重要的两个因素还是用户查询和网页的内容相关性及网页链接情况。那么,我们得到用户搜索词之后,如何从内容相关性的角度上对网页进行排序输出呢?
判断网页内容是否与用户查询相关,这依赖于搜索引擎所采用的检索模型。搜索引擎的核心是判断哪些文档是和用户需求相关的,并按照相关程度排序输出,所以相关程度计算是将用户查询和文档进行匹配的过程,而检索模型就是用来计算内容相关性程度的理论基础和核心部件。比较常见的几种检索模型有:布尔模型、向量空间模型、概率模型、语言模型以及机器学习排序算法。下面,我讲解一下比较基础的前三种模型。
首先我们得知道什么样的检索模型是一个好模型呢?我们得到用户查询词之后把待搜索文档分为四类:内容相关以及包含查询词、内容相关但不包含查询词、内容不相关以及包含查询词、内容不相关并且不包含查询词。我们稍微思考之后应该能够知道,前两项应该是我们比较想要的搜索结果,即把这两项文档内容搜索输出的检索模型是比较好的模型。
最简单的一种检索模型,归其数学基础就是集合论。使用“与或非”这些逻辑连接词将用户的查询词串联起来。比如我们希望查找和苹果公司相关的信息,可以用下面的逻辑表达式来在作为查询:
苹果 AND (乔布斯 OR iPad2)
这个表达式的含义就是如果一篇文档里包含了“苹果”并且也包含了“乔布斯”或者“iPad2”,那么这个文档就是我们需要的,就可以把它作为搜索结果输出。
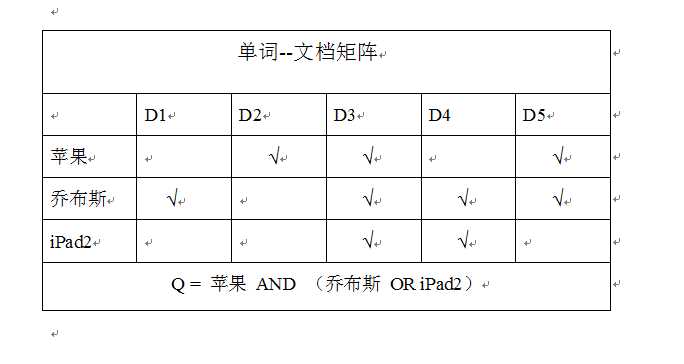
以上图为例:假设此时我们有5个文档,文档1(D1)包含了查询词“乔布斯”,文档4包含了查询词“乔布斯”和“iPad2”,其他文档含义一样。这时,我们可以很直观的看到文档1、3、4、5包含了“乔布斯”或者“iPad2”,而文档2、3、5包含了“苹果”一词,所以“苹果 AND (乔布斯 OR iPad2)”这一查询词就可以搜索到文档3、5,这两个文档就是满足整个逻辑表达式的。
问一问:看到这里,你知道布尔模型有哪些缺点吗,亲?
这个模型可以算是我比较喜欢的模型了,虽然它的效率不及后面提到的几个模型,也许是我在看书的时候比较认真看这个模型吧,感觉挺高大上的。
向量空间模型把每个文档都看做是由t维特征组成的一个向量,其中每个特征会根据一定依据计算其权重,然后就计算文档之间或者查询和文档之间的相似性了。对于搜索排序任务来说,就计算用户的查询词和文档网页内容之间的相关性,然后根据相关性大小排序输出前K个结果即可。
特征权重计算
我们需要考虑两个因素:词频因子(Tf)和逆文档频率因子(IDF)
Tf:一个单词在文档中出现的次数,有两个计算公式:
WTf = 1 + log(Tf)
WTf = a + (1-a) * Tf / Max(Tf)
a是调节因子,经验值为0.4,Max(Tf)代表了文档中所有单词中出现次数最多的那个单词对应的词频数目。第二个公式有效的抑制了长文档的优势,因为虽说两个公式都可以,但是想想如果采用第一个公式,我们对于长文档和短文档来说,长文档中Tf普遍比短文档的值高,但是这并不意味着长文档就是我们需要的呀,所以,第二个计算公式更加的公正有效。
IDF:逆文档频率因子,其计算公式如下:
IDFk = log(N/nk)
N代表文档集合中总共有多少个文档,而nk代表特征单词k在其中多少个文档中出现过,即文档频率。显然,文档频率越高,则IDF就越小,IDF反映了一个特征词在整个文档集合中的分布情况,特征词出现在其中的文档数目越多,这个词区分不同文档的能力就越差。
特征权重:Weightword = Tf * IDF
对于某个文档D来说:
如果D中某个单词的词频很高,而且这个单词在文档集合的其他文档中很少出现,那么这个单词的权值会很高。
如果D中某个单词的词频很高,但是这个单词在文档集合的其他文档中也经常出现,或者单词词频不高,但是在文档集合的其他文档中很少出现,那么这个单词的权值一般。
如果D中某个单词的词频很低,同时这个单词在文档集合的其他文档中经常出现,那么这个单词权值很低。
相似性计算
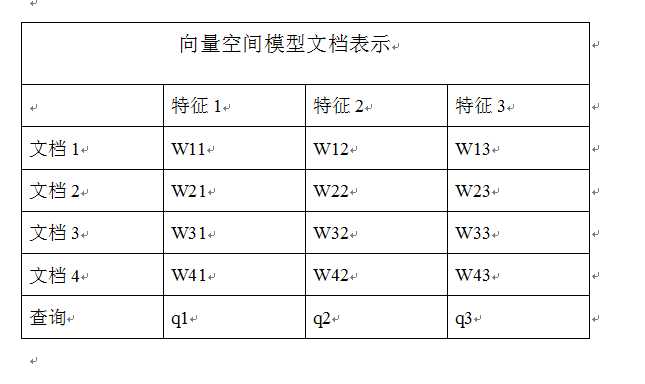
根据上图可以列出下面的式子:
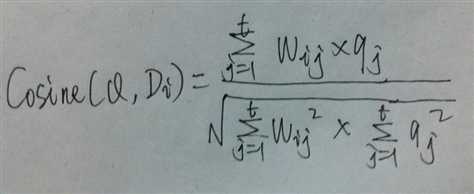
Cosine相似性就是计算特征空间中两个向量之间的夹角,夹角越小,说明两个特征向量越相似。但是有一种特殊情况:两个完全相同的文档,其在向量空间中的两个向量是重叠的,所以Cosine相似性计算结果是1。
丫据说比向量空间模型效果更好,不过看到概率两个字我就有点蔫儿了,原谅我大一时候概率没学好啊,现在有时候还在补习。这里我先给出一些计算公式。
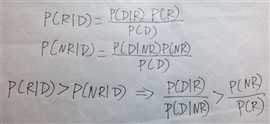
其它模型:HMM隐马尔科夫语言模型、翻译模型、BM25模型等等。
继续学习吧,骚年!
标签:
原文地址:http://www.cnblogs.com/BaiYiShaoNian/p/4564974.html