标签:style blog http color 使用 width
http://wiki.woodpecker.org.cn/moin/PyBooks
看书不爽,那你上这来看看,几道简简单单的题做过之后,顿觉一览众山小
http://www.pythontutor.com/
咱们不是一边学爬虫,一边学python吗?会点基础就够了。什么,怕程序写的太屎,哈哈,我回头回顾我的过去生活,觉得这20几年咋这么sb呢!先动起手来,总会好的!
http://blog.csdn.net/wxg694175346/article/category/1418998/2
不想看,那也ok,只要知道以下几个东西,足够照着改写自己的爬虫了。所谓的爬虫,就是通过一个网页,抓取该网页的内容,同时爬取该网页指向的其他网页。本文的程序使用的爬虫程序原理是通过python自带的urllib2来获取一个网页的源码,然后通过正则表达式获取我们想要的内容,存储到本地。OK。
工欲善其事,必先利其器。我们需要知道两个东西即可。
myPage=urllib2("www.baidu.com") :python自带的模块,形参是一个网址,返回该网址的源代码(字符串)。否则返回None。
知道这点就够了,如果你是个好学生,可以详细了解下。你说你不止爬一个网页,哈哈,我早想到好的方法了,就是我们不断的传入新的网址,就ok了,哈哈 哈。我们获取到源码后,通过正则表达式获得我们想要的内容就行了。所以接下来。。。
正则表达式:可以看这里(推荐)
http://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
也可以看这里哟
http://zh.wikipedia.org/wiki/%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F
简单的把推荐那个看一遍,足够我们改写这个小程序了。虽然可能写出来的看起来惨不忍睹,但是写出来能给我们自己点正能量不是很好吗?
5.简单的分析下我这个程序想获得的内容。
先看这里,以下4张分别是所要爬取网页的网址截图,分别是第1,2,3,4页:




发现没,除了第一页之外其他几页变化的只有后面的数字。这样,我们只要知道最后一页的页码,通过for循环可以改变网址中变化的那个数字,依次传入 urllib2中,我们就可以获取到这组网页中所有的源码了。那怎么获取这组网页的最后一页的页码呢?可以查看改组中任意网页的源码,应该可以找到。(我用的
chrome,右键自带查看源码。)来看看我的这个网页源码:
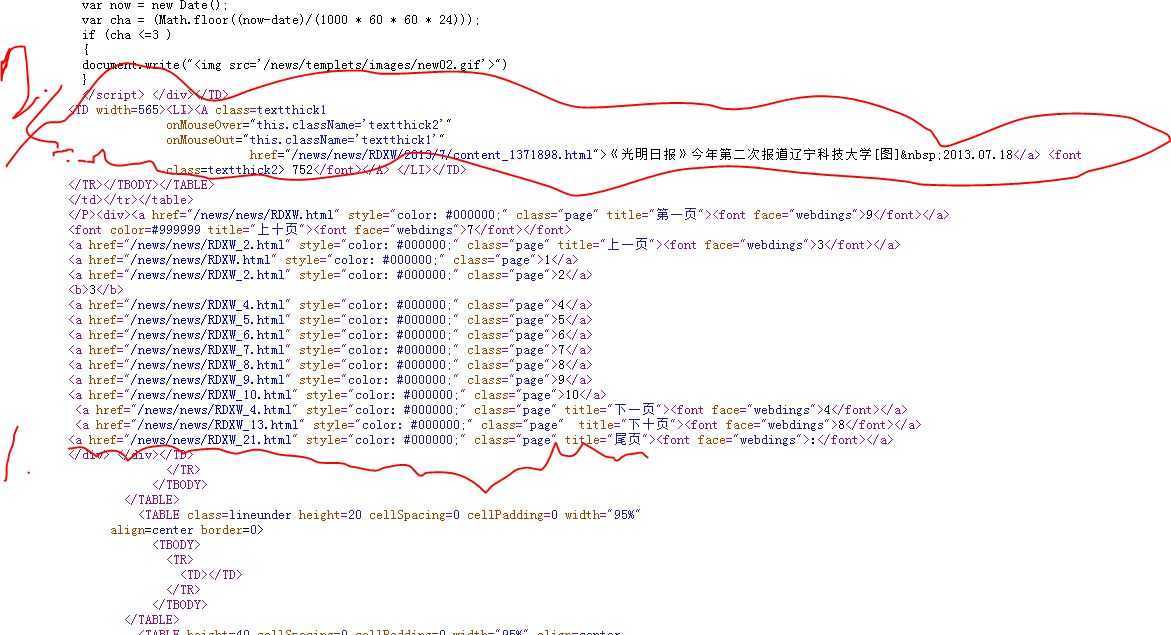
看我标记1的地方(触摸板画得,手抖。。)我们可以看到写着 "尾页"的这一行,这一行的开头标识了最后一页的页码,21.
我标识2的地方是我需要提取的内容,一个是标题,一个是网址。
提取的任务交给 正则表达式吧,我就不说我写的这个了,我自己看着都觉得差,希望你们能写的漂亮。
6.上代码
# -*- coding: utf-8 -*- # 程序:爬取有关科大一等奖新闻 # 版本:0.1 # 时间:2014.06.30 # 语言:python 2.7 #--------------------------------- import string,urllib2,re,sys #解决这个错误:UnicodeEncodeError: ‘ascii‘ codec can‘t encode characters in position 32-34: ordinal not in range(128) reload(sys) sys.setdefaultencoding(‘utf-8‘) class USTL_Spider: def __init__(self,url): self.myUrl=url #存放获取的标题和网址 self.datas=[] print ‘The Spider is Starting!‘ def ustl_start(self): myPage=urllib2.urlopen(self.myUrl+‘.html‘).read().decode(‘gb2312‘) if myPage==None: print ‘No such is needed!‘ return #首先获得总的页数 endPage=self.find_endPage(myPage) if endPage==0: return #处理第一页的数据 self.deal_data(myPage) #处理除第一页之外的所有数据 self.save_data(self.myUrl,endPage) #获取总的页数 def find_endPage(self,myPage): #找到网页源码中带有尾页的一行。eg: >8</font> xxxxx title="尾页" #匹配中文,需要utf-8格式,并且变成ur‘‘。 #.*?:非贪婪匹配任意项 #re.S:正则表达式的 . 可以匹配换行符 myMatch=re.search(ur‘>8</font>(.*?)title="尾页"‘,myPage,re.S) endPage=0 if myMatch: #找到带尾页行中的数字。eg:xxxx_ NUM .html endPage=int(re.match(r‘(.*?)_(\d+).html‘,myMatch.group(1),re.S).group(2)) else: print ‘Cant get endPage!‘ return endPage #将列表中的字符串依次写入到我的d盘tests文件夹ustl.txt文件上 def save_data(self,url,endPage): self.get_data(url,endPage) f=open("d:\\tests\\ustl.txt",‘w‘) for item in self.datas: f.write(item) f.close() print ‘Over!‘ #提取每个网页 def get_data(self,url,endPage): for i in range(2,endPage+1): print ‘Now the spider is crawling the %d page...‘ % i #字符串做decode时候,加‘ignore‘忽略非法字符 myPage=urllib2.urlopen(self.myUrl+‘_‘+str(i)+‘.html‘).read().decode(‘gb2312‘,‘ignore‘) if myPage==None: print ‘No such is needed!‘ return self.deal_data(myPage) #获得我们想要的字符串,追加到datas中 def deal_data(self,myPage): myItems=re.findall(r‘<TD width=565>.*?href="(.*?)">(.*?)</a>‘,myPage,re.S) for site,title in myItems: #这里我们获取的是有关一等奖的文章标题 if re.match(ur‘.*?一等奖.*?‘,title): #删除标题中的  title=title.replace(‘ ‘,‘‘) self.datas.append(‘%s :%5swww.ustl.edu.cn%s\n‘ %(title,‘ ‘,site)) #newsSite=raw_input(‘Please input site of USTL like this: http://www.ustl.edu.cn/news/news/RDXW‘) #ustl=USTL_Spider(‘http://www.ustl.edu.cn/news/news/RDXW‘) ustl=USTL_Spider(‘http://www.ustl.edu.cn/news/news/ZHXX‘) ustl.ustl_start()
7.参考资料
有空看下,生活立马高大上:
1.编码错误什么最讨人厌了:
http://blog.csdn.net/cnmilan/article/details/9264643
2.中文编码更讨厌,我一定要学好英文:
http://www.jb51.net/article/17560.htm
3.urllib2:
http://www.voidspace.org.uk/python/articles/urllib2.shtml#openers-and-handlers
(原)爬取辽宁科技大学相关新闻---python爬虫入门,布布扣,bubuko.com
标签:style blog http color 使用 width
原文地址:http://www.cnblogs.com/jhooon/p/3817496.html