标签:shell脚本(六)
#awk编程模式分三个阶段:读取输入文件前执行代码段(由BEGIN关键词标识)
#读取输入文件时执行代码段、读取输入文件完毕之后执行代码段(由END关键词标识)
#awk语句由模式(pattern)和动作组成(action)。
#匹配空白行
awk ‘/^$/{print "a blank line"}‘ bkname.txt

#awk将每个输入文件定义为记录,行中的每个字符串定义为域,域之间使用空格、tab
#键或其他符号进行分隔,分隔域的符号叫做分隔符。$为域操作符,对指定域执行动作
#$1表示第1个域、$2表示第2个域、$3表示第3个域,以此类推,而$0表示所有域
#如文件num.txt内容,以":"为分隔符,则会分成4个域:num、123、name1和test1
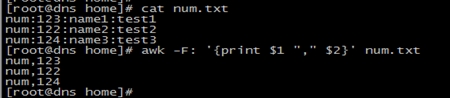
#分隔符也可以使用BEGIN标识中的FS变量来改变
awk ‘BEGIN { FS=":"} {print $1 "," $2}‘ num.txt

#关系运行符<、<=、>、>=、==、!=、~、!~:分别为小于、小于等于、大于、大于等于
#等于、不等于、匹配正则表达式、不匹配正则表达式
awk ‘BEGIN { FS=":" } { if($3<1) print $1 }‘ /etc/passwd

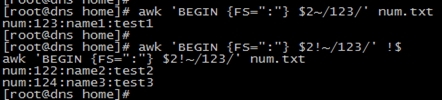
#匹配正则表达式和不匹配正则表达式
awk ‘BEGIN {FS=":"} $2~/123/‘ num.txt
awk ‘BEGIN {FS=":"} $2!~/123/‘ num.txt
#布尔运算符 ||、&&和!:分别为或、与、非
awk ‘BEGIN {FS=":"} {if($2==123 || $4=="test2") print $0}‘ num.txt
awk ‘BEGIN {FS=":"} {if($1=="num" && $2==122) print $0}‘ num.txt

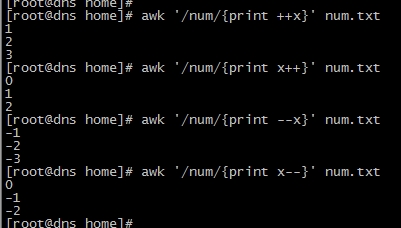
#算术运算+、-、*、/、%、^或**、++x、x++、--x和x--:分别为加、减、乘、除、求模、
#返回x值前自增1和返回x值之后自增1,返回x值前自减1和返回x值之后自减1
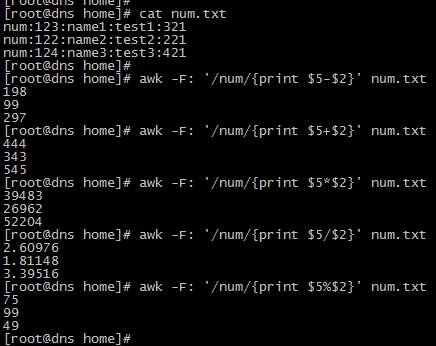
awk -F: ‘/num/{print $5+$2}‘ num.txt
awk -F: ‘/num/{print $5-$2}‘ num.txt
awk -F: ‘/num/{print $5*$2}‘ num.txt
awk -F: ‘/num/{print $5/$2}‘ num.txt
awk -F: ‘/num/{print $5%$2}‘ num.txt
awk -F: ‘/num/{print $2^2 }‘ num.txt
#$n:当前记录的第n个域,域间由FS分割
#$0:记录的所的域
#ARGC:命令行参数的数量
#ARGING:命令行中当前文件的位置(以0开始标识)
#ARGV:命令行参数的数组
#CONVFMT:数字转换格式
#ENVIRON环境变量关联数组
#ERRNO:最后一个系统错误的描述
#FIELDWIDTHS:字段宽度列表,以空格分隔
#FILENAME:当前文件名
#FNR:浏览文件的记录数,即文件中有多少条记录(行)
#FS:指定域分隔符,默认为空格
#IGNORECASE:布尔变量,如果为直,则进行忽略大小写的匹配
#NF:当前记录中的域数量,即当前记录,以分隔符分隔后域的数量
#NR:当前记录数,即当前读取到第几条记录
#OFMT:数字的输出格式
#OFS:输出域分隔符,默认为空格
#ORS:输出记录分隔符,默认是换行符
#RLENGTH:由match函数所匹配的字符串长度
#RS:记录分隔符,默认为空格
#RSTART:由match函数所匹配的字符串的第1个位置
#SUBSEP:数组下标分隔符,默认值是\034
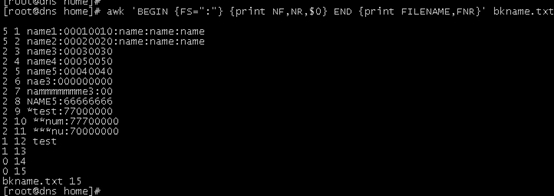
#以":"为分隔符,打印当前记录中的域数量、记录数、所有域以及文件名和文件记录数
awkl ‘BEGIN {FS=":"} {print NF,NR,$0} END {print FILENAME,FNR}‘ bkname.txt
#printf (格式化控制符,参数) ,控制符都是以%开始,参数一般为域
#修饰符"-"、"width"和".prec",分别表示:左对齐、域的步长和小数点右边的倍数
#格式符"%c"、"%d"、"%e"、"%f"、"%o"、"%s"和"%x",分别表示:ascii字符、整形数
#浮点数,科学记数法、浮点数、八进制、字符串和十六进制
#以":"为分隔符,格式化输出num.txt的第1域和第4域
awk -F: ‘{printf(%s\t%f\n,$1,$4)}‘ num.txt

#浮点数长度控制在5位、小数点后保留2位
awk ‘BEGIN {printf("%5.2f\n",20150506.2101)}‘
#小浮点数小数点保留3位,并且左对齐
awkl ‘BEGIN {printf("%-.3f\n",20150506.2101)}‘

#gsub(r,s):在输入文件中用s替换r
#gsub(r,s,t):在t中用s替换r
#index(s,t):返回s中字符串第1个t位置
#length(s):返回s长度
#match(s,t):测试s是否包含匹配t的字符串
#split(r,s,t):在t上将r分成序列s
#sub(r,s,t):将t中第1次出现的r替换成s
#substr(r,s):返回字符串r中从s开始的后缀部分,即截取从s开始到末尾字符串
#substr(r,s,t):返回字符串r中从s开始长度为t的后缀部分,
#即截取从s开始长度为t的字符串
#gsub("name","*"):在输入文件中用*替换name
awk ‘BEGIN {FS=":"} gsub(/name/,"*") {print $0}‘ num.txt

#index("get_string_index","string"):返回第1个"string"位置,从1开始
awk ‘BEGIN {print index("get_string_index","string")}‘
#length("get_string_length"):获取字符串长度
awk ‘BEGIN {print length("get_string_length")}‘

#match("test_string_exist","string"):测试字符串string是否包含在test_string_exist
awk ‘BEGIN {print match("test_string_exist","string")}‘

#sub("name2","rep",$0):将$0第1次出现的name2替换成rep
awk ‘BEGIN {FS=":"} $2~122 sub("name2","rep",$0);print $0}‘ num.txt

#substr("get_string_test",5):获取从5个字符开始到行末字符串
#substr("get_string_test",5,6):获取从5个字符开始长度为6个字符的字符串
awk ‘BEGIN {print substr("get_string_test",5)}‘
awk ‘BEGIN {print substr("get_string_test",5,6)}‘

#if条件语句。
if (条件表达式)
{
动作
}
else
{
动作
}
#for循环语句
for(n=0;n<=10;i++)
{
动作
}
#while循环语句,第1个while至少执行1次,
#第2个while可能1次都没有执行(条件不符合)
do
{
动作
}
while (条件表达式)
while(条件表达式)
{
动作
}
本文出自 “爱就行动” 博客,请务必保留此出处http://1055745601.blog.51cto.com/5003160/1660417
标签:shell脚本(六)
原文地址:http://1055745601.blog.51cto.com/5003160/1660417