标签:
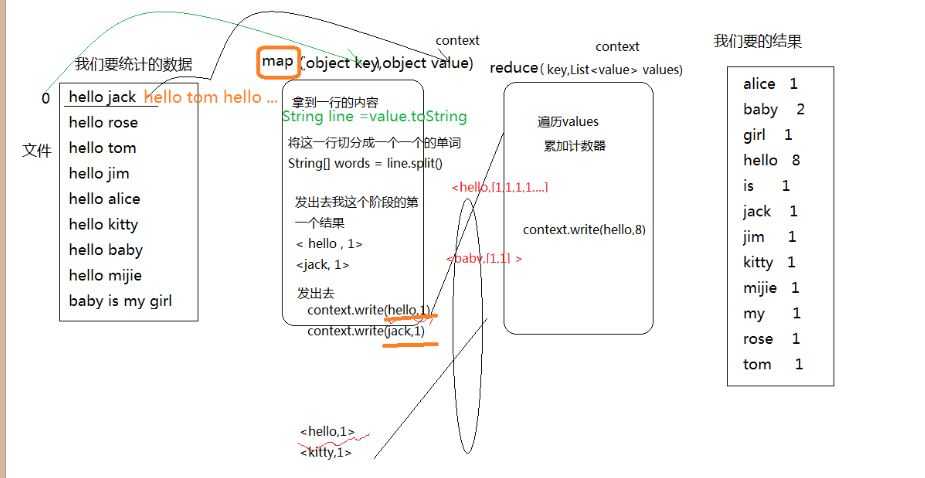
wordcount原理:
1.mapper(Object key,Object value ,Context contex)阶段
2.从数据源读取一行数据传递给mapper函数的value
3.处理数据并将处理结果输出到reduce中去
String line = value.toString();
String[] words = line.split(" ");
context.write(word,1)
4.reduce(Object key ,List<value> values ,Context context)阶段
遍历values累加技术结果,并将数据输出
context.write(word,1)
代码示例:
Mapper类:
package com.hadoop.mr; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /** * Mapper <Long, String, String, Long> * Mapper<LongWritable, Text, Text, LongWritable>//hadoop对上边的数据类型进行了封装 * LongWritable(Long):偏移量 * Text(String):输入数据的数据类型 * Text(String):输出数据的key的数据类型 * LongWritable(Long):输出数据的key的数据类型 * @author shiwen */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { //1.读取一行 String line = value.toString(); //2.分割单词 String[] words = line.split(" "); //3.统计单词 for(String word : words){ //4.输出统计 context.write(new Text(word), new LongWritable(1)); } } }
reduce类
package com.hadoop.mr; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordCountReduce extends Reducer<Text, LongWritable, Text, LongWritable>{ @Override protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { long count = 0; //1.遍历vlues统计数据 for(LongWritable value : values){ count += value.get(); } //输出统计 context.write(key, new LongWritable(count)); } }
运行类:
package com.hadoop.mr; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import com.sun.jersey.core.impl.provider.entity.XMLJAXBElementProvider.Text; public class WordCountRunner { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { //1.创建配置对象 Configuration config = new Configuration(); //2.Job对象 Job job = new Job(config); //3.设置mapperreduce所在的jar包 job.setJarByClass(WordCountRunner.class); //4.设置mapper的类 job.setMapOutputKeyClass(WordCountMapper.class); //5.设置reduce的类 job.setReducerClass(WordCountReduce.class); //6.设置reduce输入的key的数据类型 job.setOutputKeyClass(Text.class); //7.设置reduce输出的value的数据类型 job.setOutputValueClass(LongWritable.class); //8.设置输入的文件位置 FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.1.10:9000/input")); //9.设置输出的文件位置 FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.1.10:9000/input")); //10.将任务提交给集群 job.waitForCompletion(true); } }
标签:
原文地址:http://www.cnblogs.com/zhangshiwen/p/4567898.html