标签:
第二讲:简单的词向量表示:word2vec, Glove(Simple Word Vector representations: word2vec, GloVe)
转载请注明出处及保留链接“我爱自然语言处理”:http://www.52nlp.cn
本文链接地址:斯坦福大学深度学习与自然语言处理第二讲:词向量
推荐阅读材料:
以下是第二讲的相关笔记,主要参考自课程的slides,视频和其他相关资料。
如何来表示一个词的意思(meaning)
在计算机中如何表示一个词的意思


语义词典存在的问题
One-hot Representation

Distributional similarity based representations


如何使用上下文来表示单词
基于窗口的共现矩阵:一个简单例子
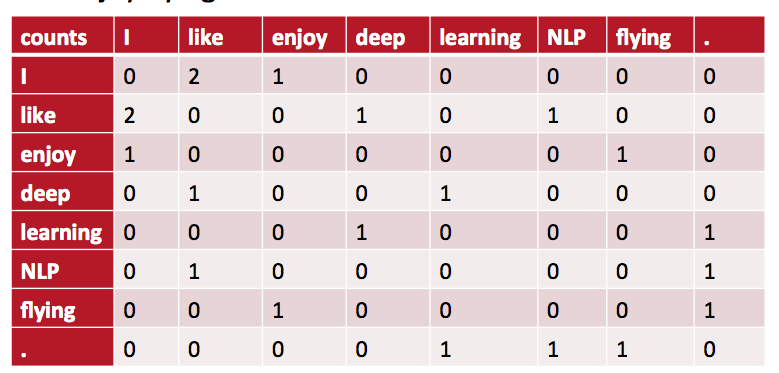
存在的问题
解决方案:低维向量
方法1:SVD(奇异值分解)
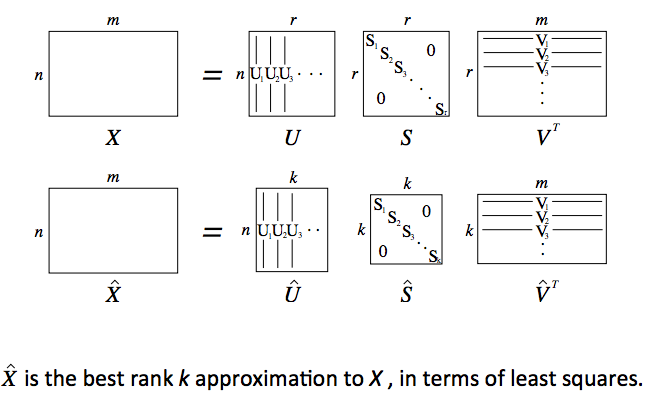
Python中简单的词向量SVD分解

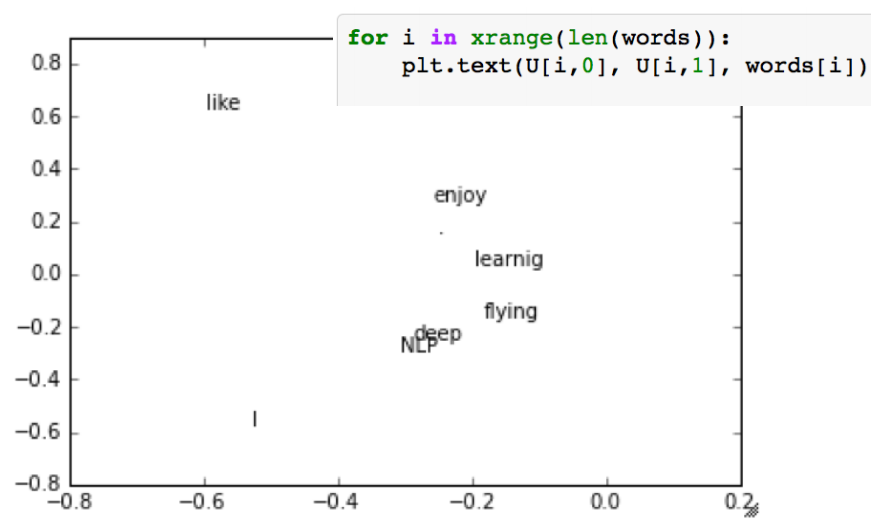
用向量来定义单词的意思:

Hacks to X
词向量中出现的一些有趣的语义Pattern
An improved model of semantic similarity based on lexical co-occurence

使用SVD存在的问题
解决方案:直接学习低维度的词向量
word2vec的主要思路
word2vec的主要思路
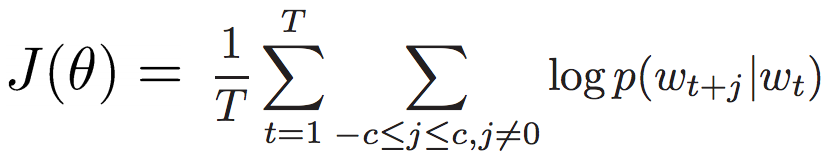
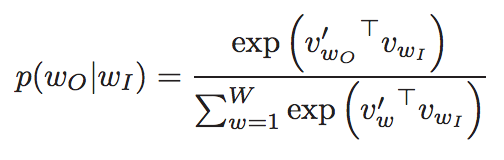
代价/目标函数


梯度的导数
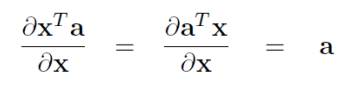
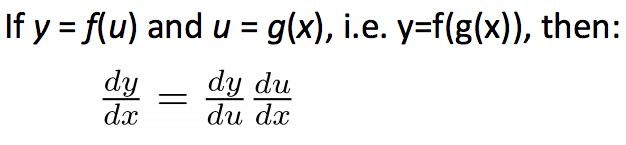
word2vec中的线性关系

计数的方法 vs 直接预测
GloVe: 综合了两类方法的优点
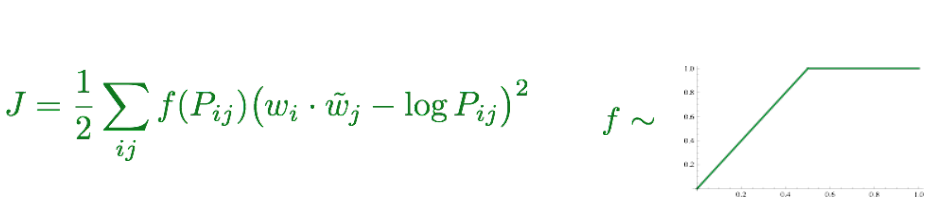
GloVe的效果

Word Analogies(词类比)
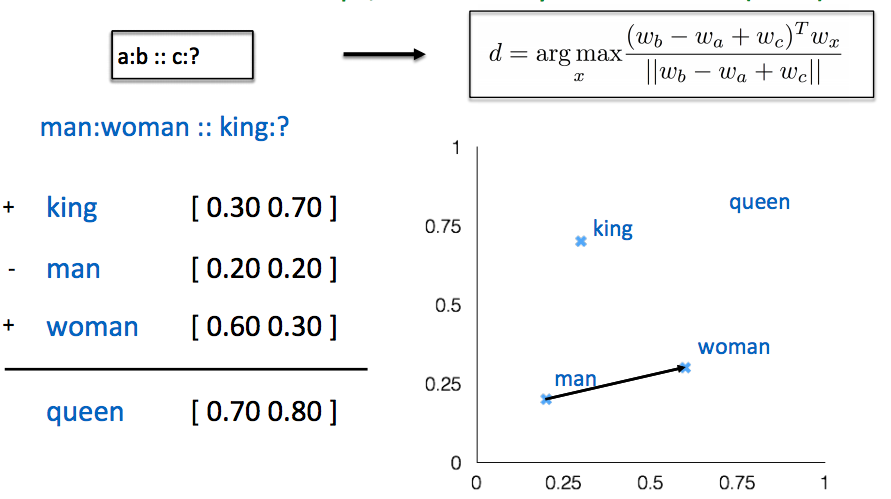
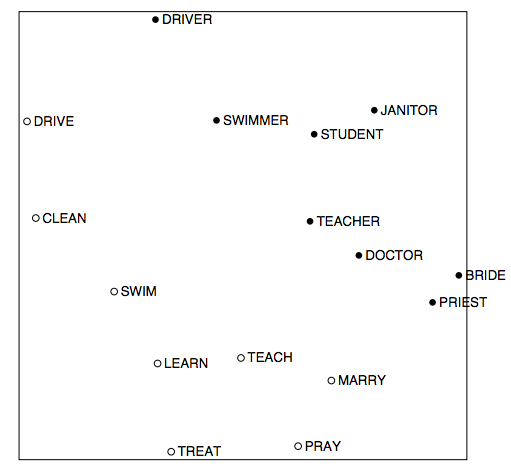
Glove可视化一
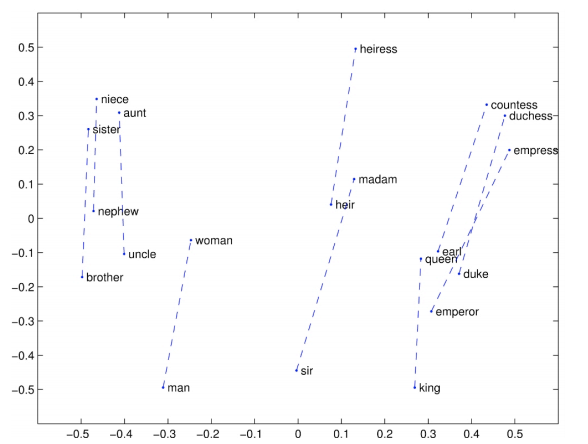
Glove可视化二:Company-CEO
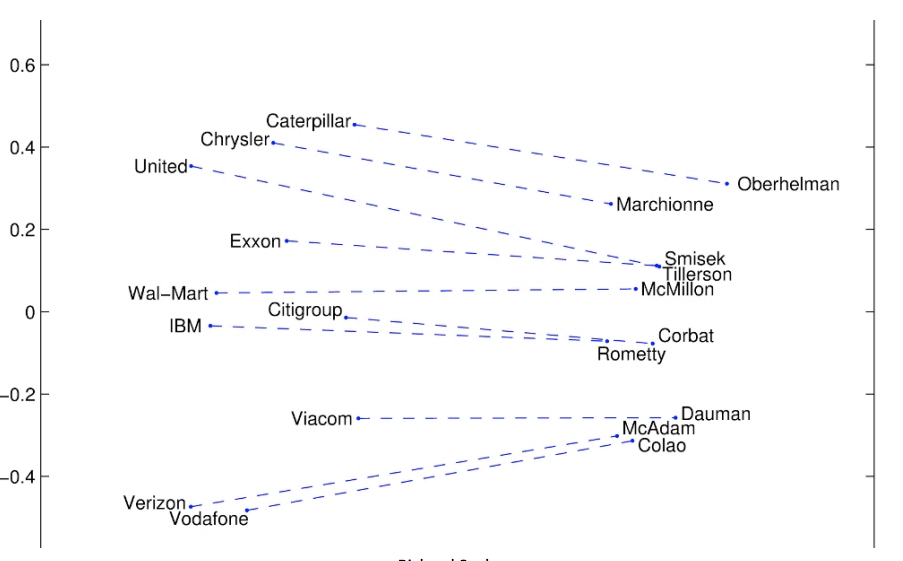
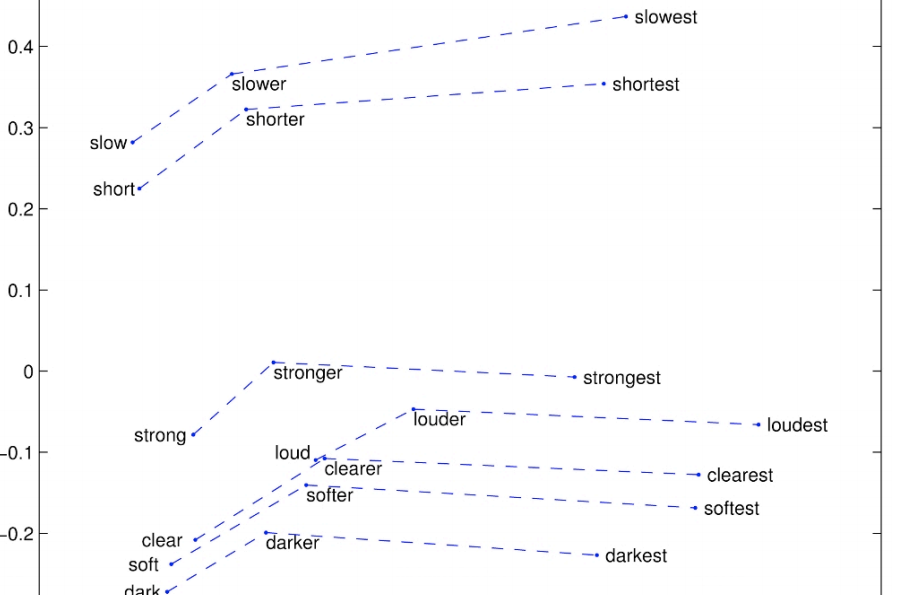
Glove可视化三:Superlatives
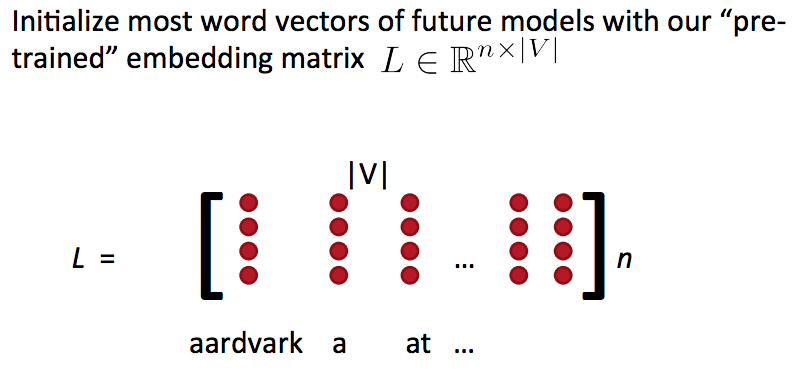
Word embedding matrix(词嵌入矩阵)
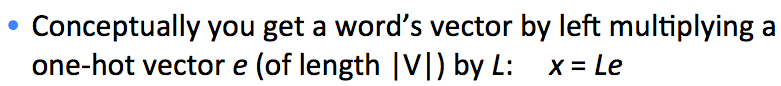
低维度词向量的优点
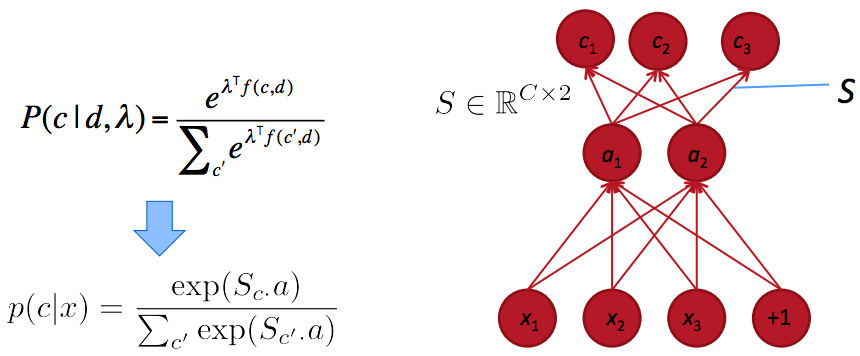
课程笔记索引:
斯坦福大学深度学习与自然语言处理第一讲:引言
参考资料:
Deep Learning in NLP (一)词向量和语言模型
奇异值分解(We Recommend a Singular Value Decomposition)
标签:
原文地址:http://www.cnblogs.com/zhang-m/p/4572114.html