标签:
上篇讲到SQL Server中DML的基本使用方法,其中SELECT语句是最常用的语句,其功能强大,结构复杂,下面通过例子,具体介绍其使用方法。
SELECT语句从数据表或视图中查找数据,SELECT语法归纳如下:
[WITH <common_table_expression>]
SELECT select_list [INTO new_table_name]
[FROM table_source] [WHERE search_condition]
[GROUP BY group_by_expression]
[HAVING search_condition]
[ORDER BY order_expression [ASC | DESC] ]
假设现有如下三张表格,名称分别为Student、Course和Grade,下面使用例子具体介绍各个子句的使用方法。
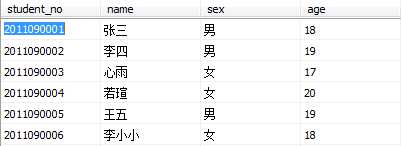
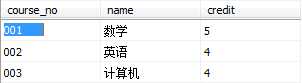
Student Course
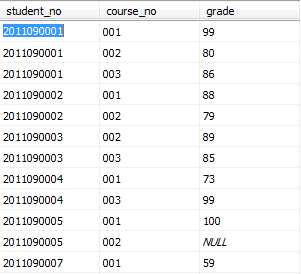
Grade
WITH子句用于指定临时命名的结果集,这些结果集称为共用表表达式(CTE),来自简单的查询。也就是说,先通过WITH子句查找出一个临时的表,再在该临时表中进行查询。语法如下(语法格式,大写为关键字,[]为可选项,[,...]为可重复前一项):
WITH expression_name [(column_name [,…])] AS
(CTE_query_definition)
CTE_query_definition: 指定一个其结果集填充共用表达式的SELECT语句。
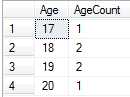
例如,在WITH子句中查找Student的年龄分布,放入临时表AgeReport中,再查找AgeReport表,SQL语句如下:

结果如下:
SELECT指明要读取的信息,FROM指定从中获取数据的一个或多个表。SELECT中为查询的列取别名方法:
别名 = 列名
列名 AS 别名
列名 别名
例如,查询Student表中student_no和name并设置别名为学号和姓名:
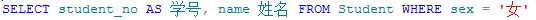
结果如下:
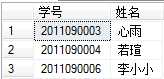
创建新表并将查询结果插入新表中。
[NOT] boolean_expression
Boolean_expression AND boolean_expression
Boolean_expression OR boolean_expressio
2. 比较运算符
= > < >= <= <>
例如,查找性别为女,年龄小于18的student:
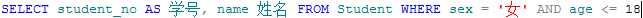

3. LIKE关键字
Match_expression [NOT] LIKE pattern [ESCAPE escape_expression]
通配符% _ [] [^],%可匹配任何0个或多个字符,_匹配一个字符,[]指定范围或集合,如 [a-f]或[abcdef]表示其中的一个字符,[^]同[]相反。
例如,查找姓李的学生:


4. BETWEEN关键字
BETWEEN...AND和NOT BETWEEN… AND
5. IS (NOT) NULL关键字
在WHERE子句中,不能用=来判断NULL,只能用IS (NOT) NULL
例如,超找成绩表中,成绩为空的记录:
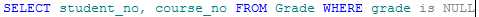
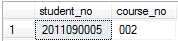
6. IN关键字
使用IN关键字来指定列表搜索的条件,确定指定的值是否与子查询或列表中的值相匹配。
Test_expression [NOT] IN (subquery | expression [,...])
7. ALL、SOME、ANY关键字
比较标量值和单列集中的值,与比较运算符和子查询一起使用。
Scalar_expression {= | <> | > | >= | < | <= } {ALL | SOME | ANY} (subquery)
例如,查找学生中年龄比心雨和李小小都大(> ALL)的学生:

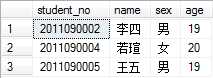
8. EXISTS关键字
用于指定一个子查询是否存在
EXISTS subquery
表示按照一个或多个列或表达式的值将一组选定行组合成一个摘要行集,针对每一组返回一行。
GROUP BY group_by_expression [,...]
SELECT子句必须包括在聚类函数或GROUP BY子句中。常用的行聚合函数如下:
|
COUNT(*) |
|
返回组中的项数 |
|
COUNT([ALL | DISTINCT] 列名]) |
|
返回某列的个数 |
|
AVG([ALL | DISTINCT] 列名]) |
|
返回某列的平均值 |
|
MAX([ALL | DISTINCT] 列名]) |
|
返回某列的最大值 |
|
MIN([ALL | DISTINCT] 列名]) |
|
最小值 |
|
SUM([ALL | DISTINCT] 列名]) |
|
总和 |
|
STDEV([ALL | DISTINCT] 列名]) |
|
标准偏差 |
|
STDEVP([ALL | DISTINCT] 列名]) |
|
总体标准偏差 |
|
VAR([ALL | DISTINCT] 列名]) |
|
方差 |
|
VARP([ALL | DISTINCT] 列名]) |
|
总体方差 |
例如,将学生按照性别分组,并统计人数:
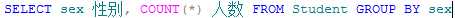
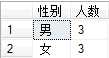
指定组或聚合的搜索条件,通常在GROUP BY中使用。
HAVING search_condition
例如,将学生按照性别分组,并统计女生的人数
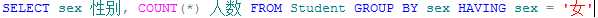
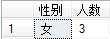
指定在SELECT语句返回的列表中所使用的排序方式。除非同时指定了TOP,否则ORDER BY子句在视图、内联函数、派生表和子查询中无效。
ORDER BY {order_by_expression [COLLATE collation_name] [ASC | DESC] [,...]}
[COLLATE collation_name] 指定为collation_name的排序规则,而不是表或视图中所定义的排序规则。
ASC 表示升序排列,DESC表示降序排列,默认为升序。
例如,将学生按照年龄排序:
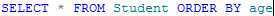
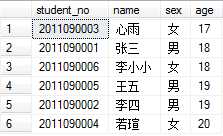
生成合计作为附加的汇总列出现在结果集的最后,当与BY一起使用时,COMPUTE子句在结果集中生成控制中断和小计。
COMPUTE
{ {AVG | COUNT | MAX | MIN | STDEV | STDEVP | VAR | VARP | SUM} (expression) }[,...]
[BY expression [,…]]
如果是使用COMPUTE子句指定的行聚合函数,不允许他们使用DISTINCT关键字。
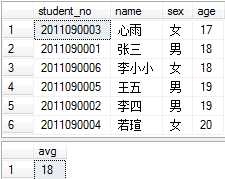
例如,将学生按照年龄排序,并计算平均年龄:
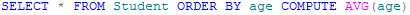
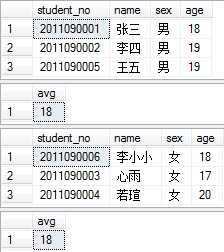
例如,将学生按照性别排序,并计算不同性别的平均年龄:
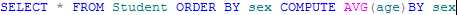
从SELECT语句的结果集中去掉重复的记录。
限制查询结构显示的条数。
SELECT TOP n [PERCENT] FROM table WHERE
PERCENT 表示百分之n。
例如,查找年龄最小的三个学生:

UNION合并是将两个表的行合并到一个表中。合并后新表的行数是两个表行数之和,列数不变。需满足一下规则:
UNION和联接查询之间的区别
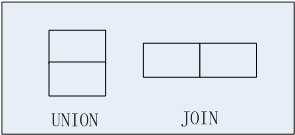
在合并中,两个表的列的数量必须相同,类型兼容;联接中,结果表的列可能来自第一个表、第二个表或两个表都有。
合并中,结构表的最大行数是两个表的行数和;联接中,行最大是两个表的乘积。
例如,合并学生和课程的表格:

子查询是一个嵌套在SELECT、INSERT、UPDATE或DELETE语句或其他子查询中的查询,任何使用表达式的地方都可以使用子查询。
嵌套查询是指将一个查询块嵌套在另一个查询块的WHERE或HAVING子句中,因此嵌套查询属于子查询。
嵌套查询常和比较运算符(<、>等)和逻辑运算符(IN、ANY等)一起使用。
例如,查找数学成绩大于90的学生信息:

关系数据库,经常通过主键、外键来建立一对一、一对多或多对多的关系表。联接查询就是将具有关系的两个或多个表联接起来查询。
联接查询是由一个笛卡尔乘积运算再加一个选取运算构成。联接可分为内部联接、外部联接和交叉联接。
SELECT fieldlist FROM table1 [INNER] JOIN table2 ON table1.column = table2.column
内部联接结果中,删除被连接表中没有匹配项的所有行,所以可能丢失信息。
例如,联接查询学生和成绩表:

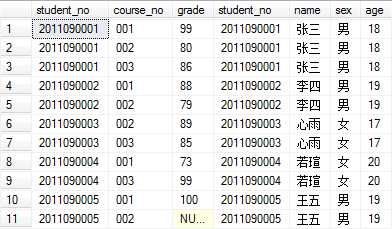
SELECT fieldlist FROM table1 LEFT JOIN table2 ON table1.column = table2.column
结果中保留左边表的所有项,删除右边表中没有匹配项的行。
例如,左联接查询学生和成绩表
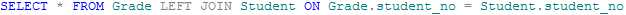
可见多了一行,其为成绩表中在学生表中没有匹配的项,该行中学生表数据全为NULL。
2. RIGHT JOIN
SELECT fieldlist FROM table1 RIGHT JOIN table2 ON table1.column = table2.column
结果中保留右边表的所有项,删除左边表中没有匹配项的行。
例如,右联接查询学生和成绩表:

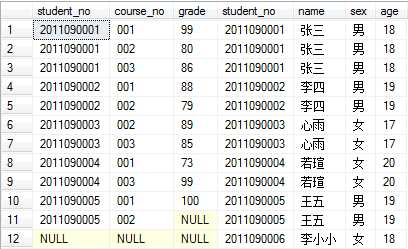
可见多了一行,其为学生表中在成绩表中没有匹配的项,该行中成绩表数据全为NULL。
3. FULL JOIN
SELECT fieldlist FROM table1 FULL JOIN table2 ON table1.column = table2.column
结果中保留左右边表的所有项
例如,全联接查询学生和成绩表:
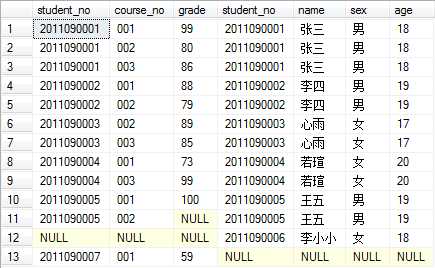
可见多了两行。 保留两个表完整的数据。
没有WHERE子句的交叉联接,产生两个表的笛卡尔集。结果集中的行为源表行的乘积,应该避免大型列表进行交叉联接。
SELECT fieldlist FROM table1 CROSS JOIN table2
例如,交叉联接课程和学生表,结果集的行数为两表行数的乘积。

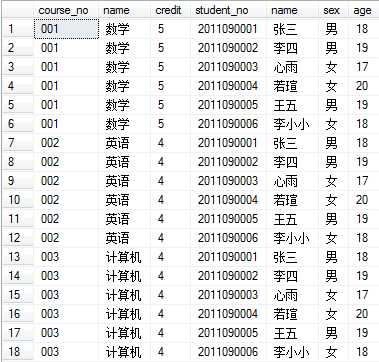
SELECT fieldlist FROM table1 , table2, table3... WHERE table1.column = table2.column and Table2.column = table3.column...
或
SELECT fieldlist FROM table1 JOIN table2 JOIN table3... ON table1.column = table2.column and Table2.column = table3.column…
ON语句必须遵循FROM后面所列表的顺序,即FROM后面先写的表相应的ON语句先写。
标签:
原文地址:http://www.cnblogs.com/yongyu/p/4573077.html