标签:machine-learning deep-learning pre-train cnn
还记得在刚开始的时候我们丢掉的70%的训练数据吗?如果我们想要得到一个在Kaggle排行榜上有竞争力的成绩,那不是一个好主意。在70%的数据中,还有相当多的特征我们没有看到。
所以改变之前只训练一个模型的方式,我们训练几个专项网络,每一个都可以预测不同的目标集合。我们训练一个模型预测left_eye_center和right_eye_center,另一个模型预测nose_tip……;最终,我们有6个模型,使得我们可以完全利用训练数据,希望能够得到更好的预测效果。
这6个专项网络全都使用同样的网络结构。因为训练时间变得超级久,所以我们可以想一些策略让我们可以不用等到max_epochs结束,甚至让验证错误早点停止改善。这种策略叫做early stopping,我们将会写另外一个on_epoch_finished回调函数来实现这个。下面是实现:
class EarlyStopping(object):
def __init__(self, patience=100):
self.patience = patience
self.best_valid = np.inf
self.best_valid_epoch = 0
self.best_weights = None
def __call__(self, nn, train_history):
current_valid = train_history[-1][‘valid_loss‘]
current_epoch = train_history[-1][‘epoch‘]
if current_valid < self.best_valid:
self.best_valid = current_valid
self.best_valid_epoch = current_epoch
self.best_weights = nn.get_all_params_values()
elif self.best_valid_epoch + self.patience < current_epoch:
print("Early stopping.")
print("Best valid loss was {:.6f} at epoch {}.".format(
self.best_valid, self.best_valid_epoch))
nn.load_params_from(self.best_weights)
raise StopIteration()可以看到,在call函数里面有两个分支:第一个是现在的验证错误比我们之前看到的要好,第二个是最好的验证错误所在的迭代次数和当前迭代次数的距离已经超过了我们的耐心。在第一个分支里,我们存下网络的权重:
self.best_weights = nn.get_all_params_values()第二个分支里,我们将网络的权重设置成最优的验证错误时存下的值,然后发出一个StopIteration,告诉NeuralNet我们想要停止训练。
nn.load_params_from(self.best_weights)
raise StopIteration()让我们更新网络定义中的op_epoch_finished句柄,添加early stopping :
net8 = NeuralNet(
# ...
on_epoch_finished=[
AdjustVariable(‘update_learning_rate‘, start=0.03, stop=0.0001),
AdjustVariable(‘update_momentum‘, start=0.9, stop=0.999),
EarlyStopping(patience=200),
],
# ...
)到目前为止一切顺利,但是如何定义这些专项网络进行相应的预测呢?让我们做一个列表:
SPECIALIST_SETTINGS = [
dict(
columns=(
‘left_eye_center_x‘, ‘left_eye_center_y‘,
‘right_eye_center_x‘, ‘right_eye_center_y‘,
),
flip_indices=((0, 2), (1, 3)),
),
dict(
columns=(
‘nose_tip_x‘, ‘nose_tip_y‘,
),
flip_indices=(),
),
dict(
columns=(
‘mouth_left_corner_x‘, ‘mouth_left_corner_y‘,
‘mouth_right_corner_x‘, ‘mouth_right_corner_y‘,
‘mouth_center_top_lip_x‘, ‘mouth_center_top_lip_y‘,
),
flip_indices=((0, 2), (1, 3)),
),
dict(
columns=(
‘mouth_center_bottom_lip_x‘,
‘mouth_center_bottom_lip_y‘,
),
flip_indices=(),
),
dict(
columns=(
‘left_eye_inner_corner_x‘, ‘left_eye_inner_corner_y‘,
‘right_eye_inner_corner_x‘, ‘right_eye_inner_corner_y‘,
‘left_eye_outer_corner_x‘, ‘left_eye_outer_corner_y‘,
‘right_eye_outer_corner_x‘, ‘right_eye_outer_corner_y‘,
),
flip_indices=((0, 2), (1, 3), (4, 6), (5, 7)),
),
dict(
columns=(
‘left_eyebrow_inner_end_x‘, ‘left_eyebrow_inner_end_y‘,
‘right_eyebrow_inner_end_x‘, ‘right_eyebrow_inner_end_y‘,
‘left_eyebrow_outer_end_x‘, ‘left_eyebrow_outer_end_y‘,
‘right_eyebrow_outer_end_x‘, ‘right_eyebrow_outer_end_y‘,
),
flip_indices=((0, 2), (1, 3), (4, 6), (5, 7)),
),
]我们很早前就讨论过在数据扩充中flip_indices的重要性。在数据介绍部分,我们的load_data()函数也接受一个可选参数,来抽取某些列。我们将在用专项网络预测结果的fit_specialists()中使用这些特性:
from collections import OrderedDict
from sklearn.base import clone
def fit_specialists():
specialists = OrderedDict()
for setting in SPECIALIST_SETTINGS:
cols = setting[‘columns‘]
X, y = load2d(cols=cols)
model = clone(net)
model.output_num_units = y.shape[1]
model.batch_iterator_train.flip_indices = setting[‘flip_indices‘]
# set number of epochs relative to number of training examples:
model.max_epochs = int(1e7 / y.shape[0])
if ‘kwargs‘ in setting:
# an option ‘kwargs‘ in the settings list may be used to
# set any other parameter of the net:
vars(model).update(setting[‘kwargs‘])
print("Training model for columns {} for {} epochs".format(
cols, model.max_epochs))
model.fit(X, y)
specialists[cols] = model
with open(‘net-specialists.pickle‘, ‘wb‘) as f:
# we persist a dictionary with all models:
pickle.dump(specialists, f, -1)没有什么值得大惊小怪的事情,只不过是训练了一系列模型,并存进了字典。尽管有early stopping 但是在单块GPU上训练仍然要花上半天时间,而且我也不建议你运行这个。
在多块GPU上跑当然会快,但是还是太奢侈了。下一节介绍一种可以减少训练时间的方法,在这里,我们先看一下这些花费了大量资源的模型的结果。
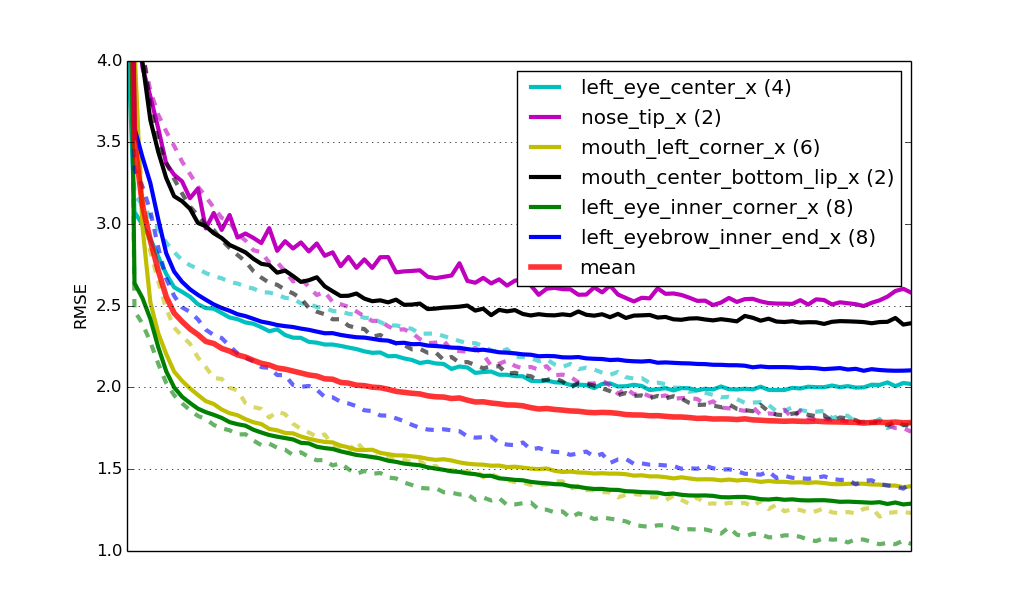
6个模型的学习率,实线代表验证集合上的RMSE(均方根误差),虚线是训练集误差。Mean代表 所有模型乘以权重(模型所拥有的目标数量)的平均验证误差。所有的曲线都在x轴缩放到同样的尺度。
教程的最后一部分,讨论一种新的方式让专项网络训练的更快。思路是:用net6或者是net7训练好的权重替代随即值来初始化网络权重。如果你还记得early stopping的实现的话,从一个网络复制权重到另一个网络是非常简单的,只要使用load_params_form()方法。下面我们改变fit_specialists方法来实现上述功能。仍然是加了#!的行是新添加的行:
def fit_specialists(fname_pretrain=None):
if fname_pretrain: # !
with open(fname_pretrain, ‘rb‘) as f: # !
net_pretrain = pickle.load(f) # !
else: # !
net_pretrain = None # !
specialists = OrderedDict()
for setting in SPECIALIST_SETTINGS:
cols = setting[‘columns‘]
X, y = load2d(cols=cols)
model = clone(net)
model.output_num_units = y.shape[1]
model.batch_iterator_train.flip_indices = setting[‘flip_indices‘]
model.max_epochs = int(4e6 / y.shape[0])
if ‘kwargs‘ in setting:
# an option ‘kwargs‘ in the settings list may be used to
# set any other parameter of the net:
vars(model).update(setting[‘kwargs‘])
if net_pretrain is not None: # !
# if a pretrain model was given, use it to initialize the
# weights of our new specialist model:
model.load_params_from(net_pretrain) # !
print("Training model for columns {} for {} epochs".format(
cols, model.max_epochs))
model.fit(X, y)
specialists[cols] = model
with open(‘net-specialists.pickle‘, ‘wb‘) as f:
# this time we‘re persisting a dictionary with all models:
pickle.dump(specialists, f, -1)事实证明复用训练好的网络的权重代替随机初始化有两个实际上的好处:一个是训练收敛的更快,在这里大概有四倍快;第二个优点是网络的泛化能力更强,前训练起到了正则化项的效果。还是和刚刚一样的学习曲线图,展示了采用了前训练的网络:
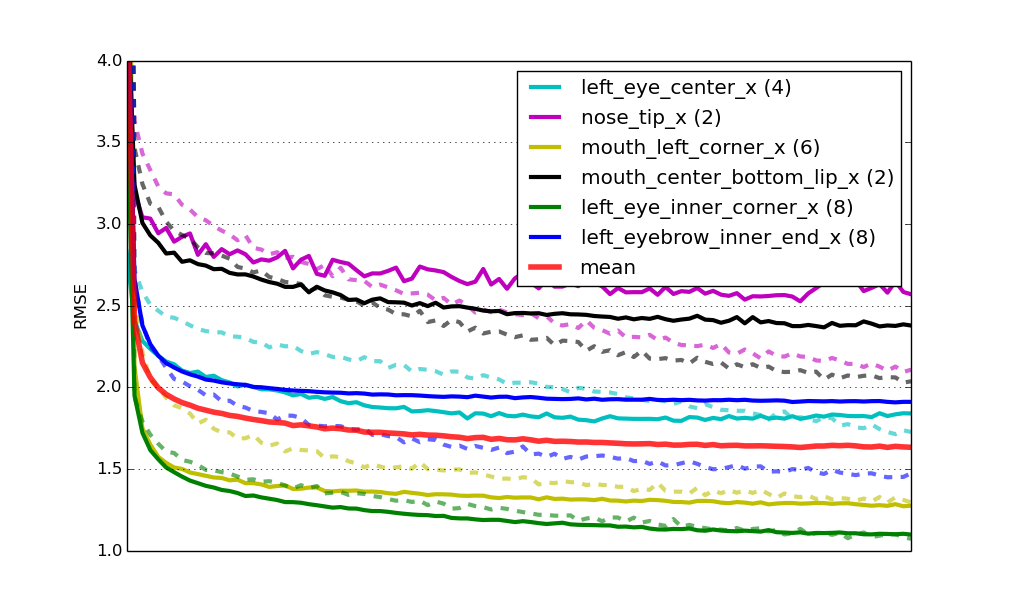
最终,这个解决方案在排行榜上的成绩是2.13 RMSE。
现在也许你已经有了一打想法想去尝试,你可以找到教程最终方案的源代码,开始你的尝试。代码中还包括生成提交文件,运行python kfkd.py找出如何在命令行使用这个脚本。
还有一大堆很明显的你可以做的改进:尝试将每一个专项网络进行优化;观察6个网络,可以发现素有的模型都存在不同程度的过拟合。如果模型像绿色或者黄色的曲线那样几乎没有任何过拟合呢,你可以尝试减少dropout的数量;要是过拟合的厉害,就增加dropout的数量。
在SPECIALIST_SETTINGS的定义中,我们能够添加针对某个特定网络的设置。如果说我们想要给第二个网络添加更多的正则化项,我们可以像下面这样改变:
dict(
columns=(
‘nose_tip_x‘, ‘nose_tip_y‘,
),
flip_indices=(),
kwargs=dict(dropout2_p=0.3, dropout3_p=0.4), # !
),还有各种各样的可以尝试改进的地方,也许你可以再加一个卷积层或者全连接层?期待你的好消息。
使用CNN(convolutional neural nets)检测脸部关键点教程(五):通过前训练(pre-train)训练专项网络
标签:machine-learning deep-learning pre-train cnn
原文地址:http://blog.csdn.net/tanhongguang1/article/details/46492599