标签:
创建目录上传英文测试文档(如果已有则无需配置)。
a.dfs上创建input目录
hadoop@ubuntu-V01:~/data/hadoop-2.5.2$bin/hadoop fs -mkdir -p input
b.把hadoop目录下的README.txt拷贝到dfs新建的input里
hadoop@ubuntu-V01:~/data/hadoop-2.5.2$bin/hadoop fs -copyFromLocal README.txt input
—————————————————————————————————
注:方法一和方法二的具体类可以略过不看。不过中间的红字要看
————————————————————————————————
方法一:
2) 创建类org.apache.hadoop.examples.WordCount,从hadoop-2.5.2-src中拷贝粘贴
(E:\hadoop\hadoop-2.5.2-src\hadoop-mapreduce-project\hadoop-mapreduce-examples\src\main\java\org\apache\hadoop\examples\WordCount.java)
3)然后创建类org.apache.hadoop.io.nativeio.NativeIO,从hadoop-2.5.2-src中拷贝粘贴
(E:\hadoop\hadoop-2.5.2-src\hadoop-common-project\hadoop-common\src\main\java\org\apache\hadoop\io\nativeio \ NativeIO.java)
以下两步可以不做:
4) 创建log4j.properties文件 (这步可以不做)
在src目录下创建log4j.properties文件,内容如下:
log4j.rootLogger=debug,stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=mapreduce_test.log
log4j.appender.R.MaxFileSize=1MB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n
log4j.logger.com.codefutures=DEBUG
5) 解决java.lang.UnsatisfiedLinkError(这步我没有做):
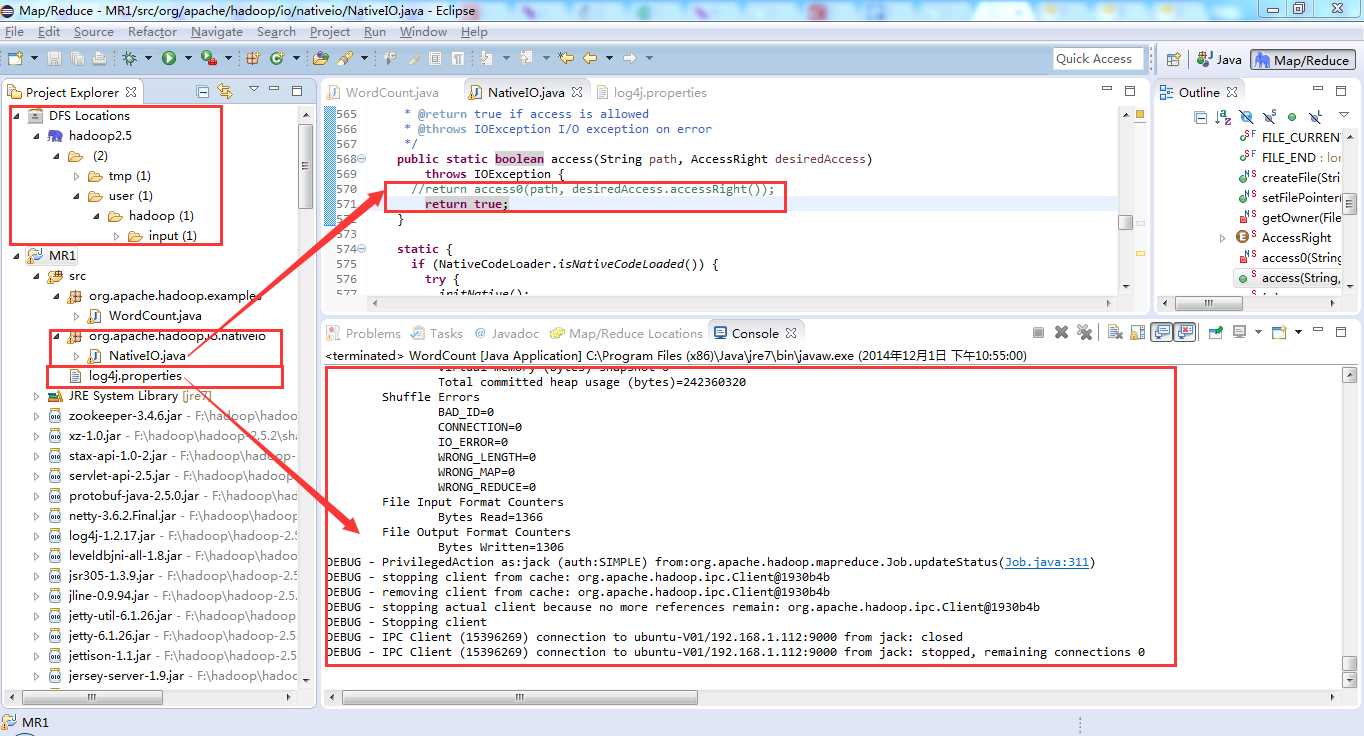
3. windows下运行环境配置(如果不生效,则需要重启机器)
需要hadoop.dll,winutils.exe (这两个文件在hadoop2.5.2(x64).zip中)。拷贝E:\hadoop\bin目录下这两文件添至E:\hadoop\hadoop-2.5.2\bin 即可。
4. 运行project
在eclipse中点击WordCount.java,右键,点击Run As—>Run Configurations,配置运行参数,即输入和输出文件夹
hdfs://192.168.0.6:9000/input hdfs://192.168.0.6:9000/output2
如下图所示:
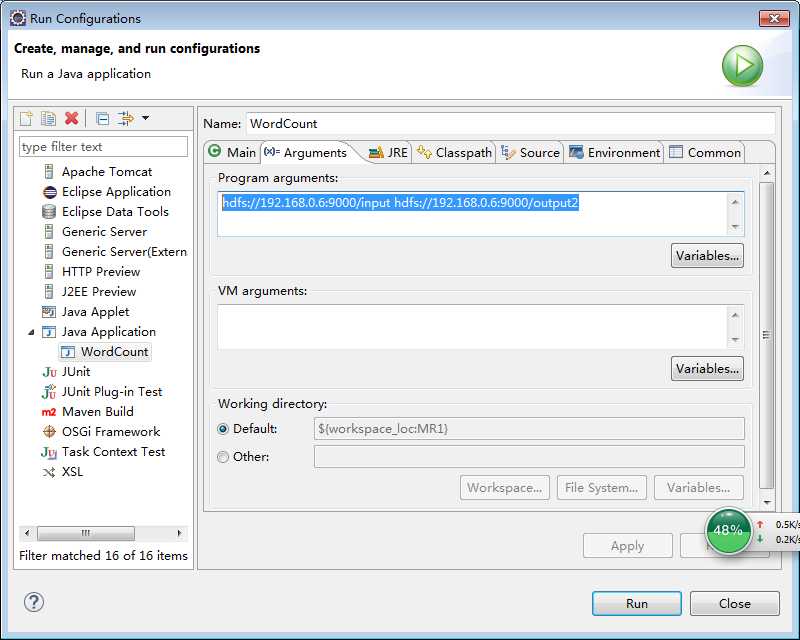
注意:以后再运行别的project时,打开上面的对话框后,需在java application上右键新建一个configuration。
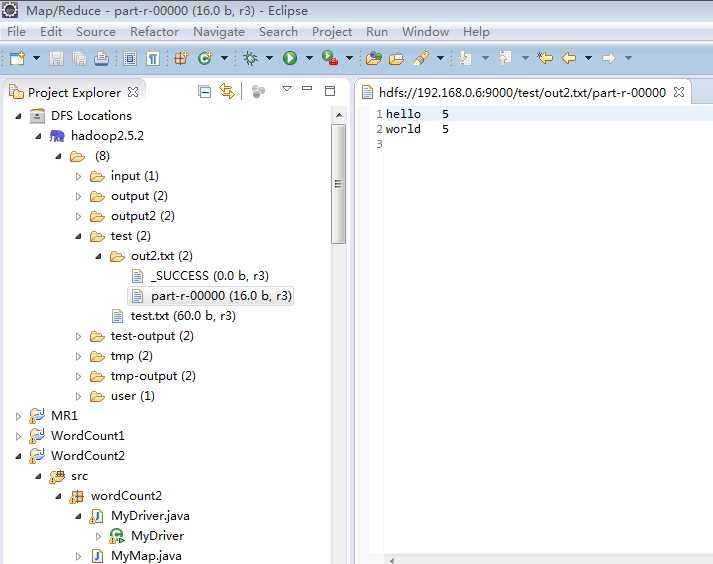
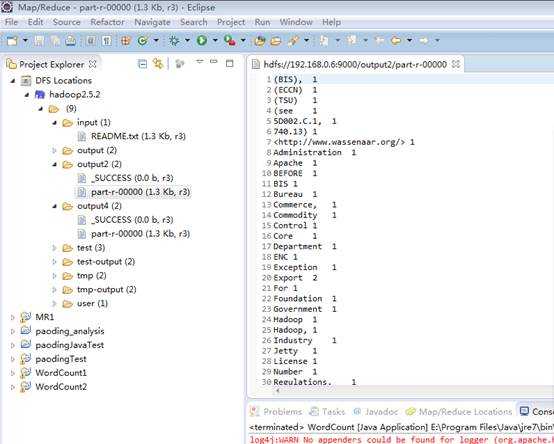
选择run运行,运行之后可以看到hdfs文件系统中出现了output文件夹,并且在该文件夹下面可以看到运行结果part-r-00000。双击即可打开该文件,如下图所示:
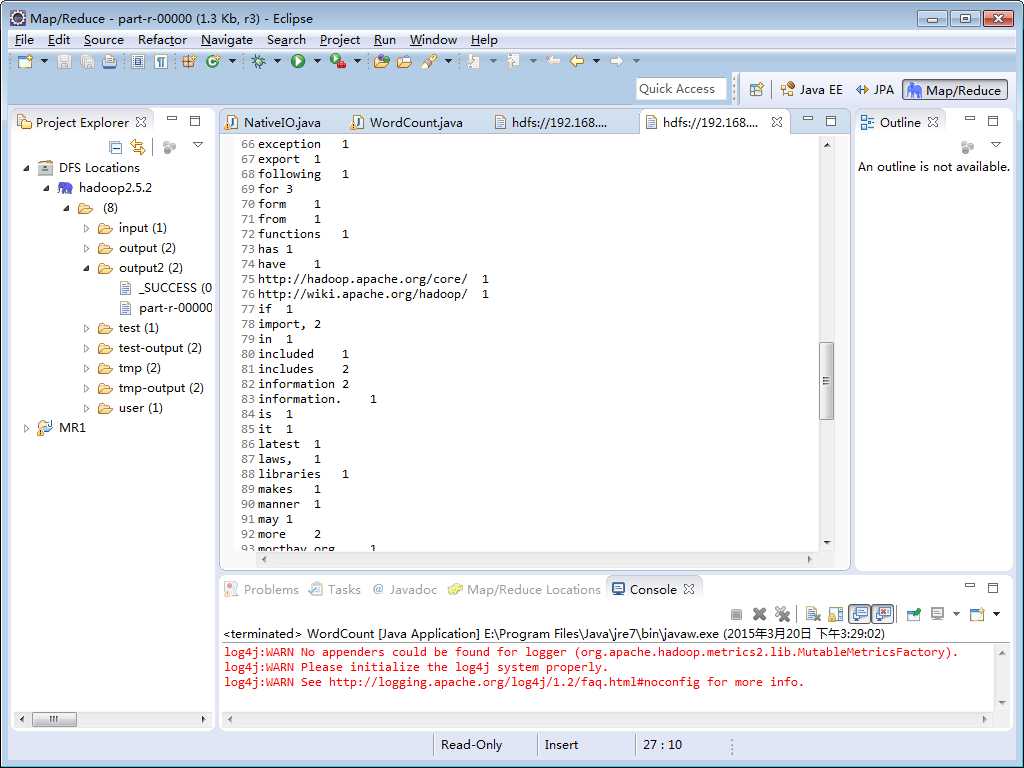
注意:如果output目录已经存在,则删掉或换个名字,如output01,output02 。。。
另外,出现问题可以多看日志(http://192.168.0.6:8088/logs/)
方法二:具体见http://www.2cto.com/kf/201212/173857.html
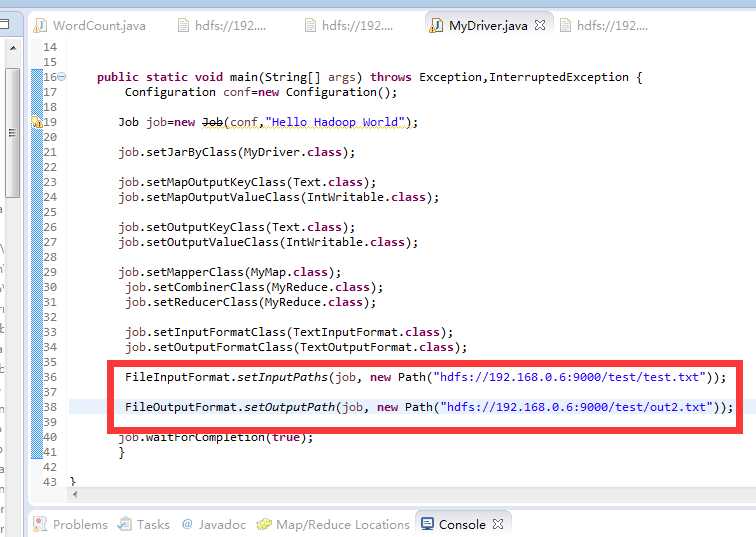
该方法在程序中指定了输入输出路径,所以在eclipse上运行的时候不需要指定输入输出路径,如下即可。
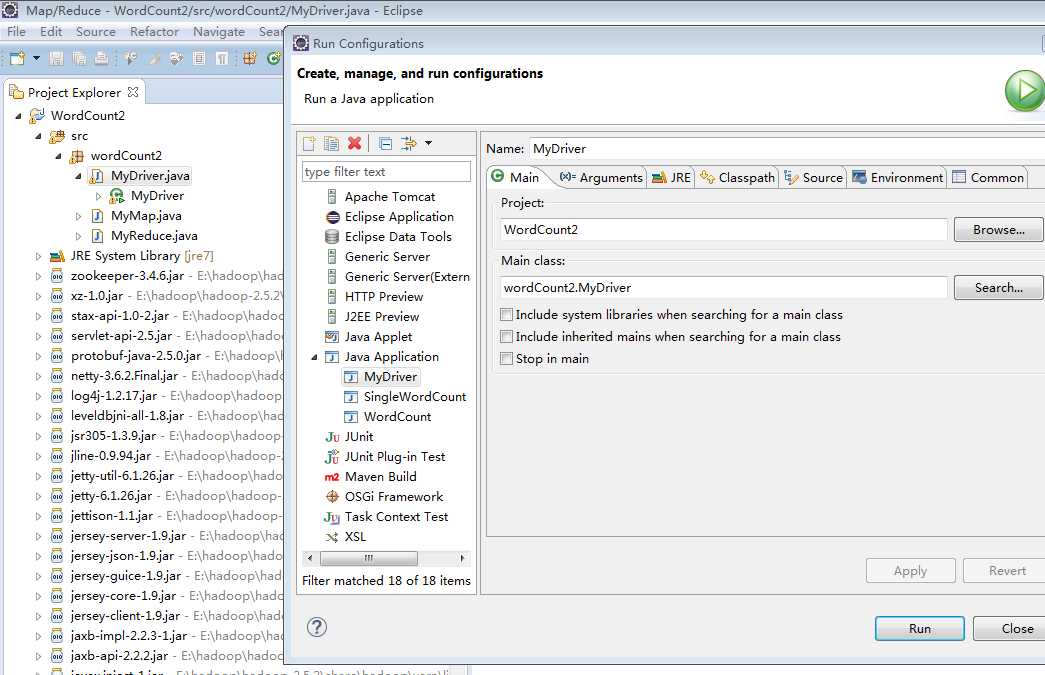
打包成jar
选中src包右键——export——java——JAR file——next——只选择左侧src文件夹就可以了,lib下的jar是hadoop自带的,不需要把它添加到jar文件里(后面的庖丁中文分词需要注意的是,庖丁的jar不是hadoop自带的,所以需要添加到jar文件里),注意不要把右侧.classpath和.project文件添加到jar文件中。再将下面的jar file选择jar包存放的路径和文件名。如下图:
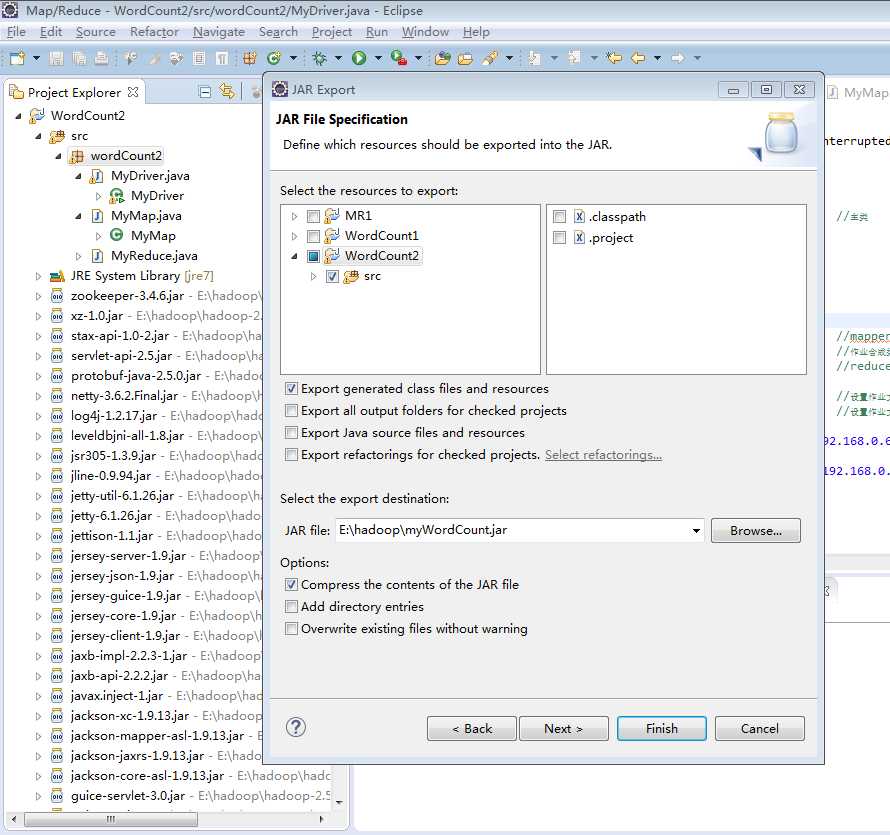
将生成的.jar文件上传到master节点的%HADOOP_HOME中(即/home/hadoop/hadoop-2.5.2)代码见实验一
cd /home/hadoop/hadoop-2.5.2
bin/hadoop jar myWordCount.jar myWordCount.MyDriver
(由于程序中已经指定文件的输入和输出,故而此时命令无需再指定,即使指定也没用)
报错,原因在于刚刚程序已经在Eclipse中执行了一遍,已经生成了输出目录,删除即可。
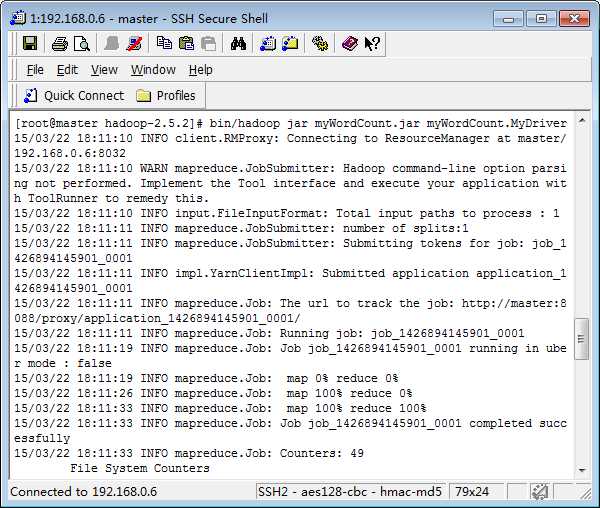
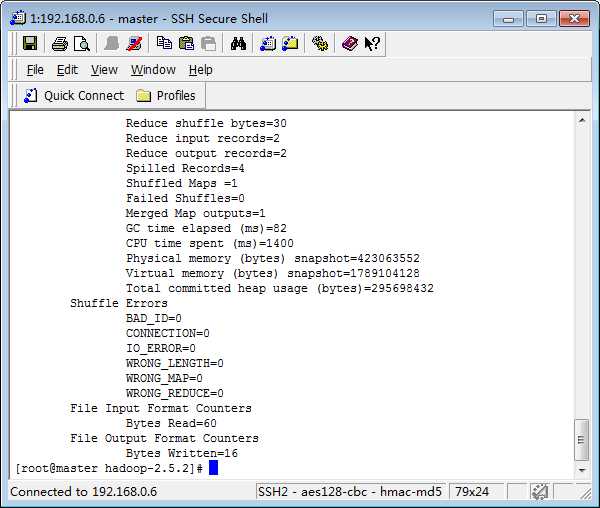
可以在Eclipse端查看结果。
注意::
同上,如果在打包时已经指定主类,那么在打包后丢到hadoop上去运行时就不要写主类,否则程序可能会将主类当成输入路径,而将输入路径当成输出路径。上图写了主类每报错是因为在打包时没有指定主类。
——————————————————————————————————
接下来的方法三是我们书上的方法,需要看。
——————————————————————————————————
方法三:
该方法我是在经历过各种失败后重新做的,此时eclipse中的编码方式已经改为UTF-8(原先没有改时的注释在改后变成了乱码,原因至今不明)
4. 结合课本修改代码,如下:
myMapper.java
|
package twoWordCount;
import java.io.IOException; import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper;
public class myMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1); private Text word = new Text();
public void map(LongWritable ikey, Text value, Context context) throws IOException, InterruptedException { /* *将字符串解析成Key-Value的形式 * ikey 偏移量 * value 内容 * context 上下文 */ StringTokenizer tokenizer = new StringTokenizer(value.toString()); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); context.write(word, one); } }
} |
myReducer.java
|
package twoWordCount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer;
public class myReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable();
public void reduce(Text _key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { /* * 获取map方法的Key—Value结果,相同的Key发送到同一个Reducer里面,迭代Key,把value想加,结果写到HDFS系统中 * _key map端输出的key值 * values Map端输出的value集合(相同key值的集合) * context Reducer端的上下文 */ int sum=0; for (IntWritable val : values) { sum=sum+val.get(); } result.set(sum); context.write(_key,result); } } |
myDriver.java
|
package twoWordCount;
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser;
public class myDriver {
public static void main(String[] args) throws Exception { // Configuration conf = new Configuration(); // String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); // //这里必须有输入输出 // if (otherArgs.length != 2) { // System.err.println("Usage: wordcount <in> <out>"); // System.exit(2); // }
Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length < 2) { System.err.println("Usage: wordcount <in> [<in>...] <out>"); System.exit(2); }
Job job = Job.getInstance(conf, "EnglishWordCount");
job.setJarByClass(twoWordCount.myDriver.class);
// TODO: specify a mapper job.setMapperClass(twoWordCount.myMapper.class); //Mapper
job.setCombinerClass(twoWordCount.myReducer.class);//作业合成类 // TODO: specify a reducer job.setReducerClass(twoWordCount.myReducer.class);//Reducer
// TODO: specify output types job.setOutputKeyClass(Text.class); //设置作业输出数据的关键类 job.setOutputValueClass(IntWritable.class); //设置作业输出值类
// TODO: specify input and output DIRECTORIES (not files) // FileInputFormat.setInputPaths(job, new Path(otherArgs[0])); //文件输入 // FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); //文件输出 // // if (!job.waitForCompletion(true)) //等待完成输出 // return;
for (int i = 0; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i])); } FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); System.exit(job.waitForCompletion(true) ? 0 : 1); }
} |
备注:里的代码也可以,用没注释的代码也可以。注释的代码是找错的时候用到的,后面遇到的问题中有说(问题一)。
5. 然后分别在eclipse上和hadoop上运行。需要注意的是,在eclipse上运行时在输入输出路径设置方式同方法二;在hadoop上运行时注意打包时是否有指定主程序,若有,则命令中不要再指定,否则就会出现各种错误,具体错误可以见后面的遇到的问题。
至此测试完毕。
实验二-2 Eclipse&Hadoop 做英文词频统计进行集群测试
标签:
原文地址:http://www.cnblogs.com/qianqianjun/p/4579330.html