标签:
爬虫学习一系列:urllib2抓取网页内容
所谓网页抓取,就是把URL地址中指定的网络资源从网络中读取出来,保存到本地。我们平时在浏览器中通过网址浏览网页,只不过我们看到的是解析过的页面效果,而通过程序获取的则是程序源代码。我们通过使用Python中urllib2来获取网页的URL资源,最简单方法就是调用urlopen 方法。
1 # coding : utf-8 2 import urllib2 3 import urllib 4 5 url = ‘http://www.baidu.com‘ 6 res = urllib2.urlopen(url) 7 print res.read()
HTTP是基于请求和应答机制—客户端提出请求,服务端提供应答。
urllib2用一个Request对象来映射你提出的HTTP请求,通过调用urlopen来传入Request对象,将返回一个相关请求response对象,这个应答对象如同一个文件对象,所以我们可以在Response对象中调用read()方法来读取。
1 # coding : utf-8 2 import urllib2 3 import urllib 4 5 url = ‘http://www.baidu.com‘ 6 request = urllib2.Request(url) 7 res = urllib2.urlopen(request) 8 print res.read()
在HTTP请求时,我们还可以发送data表单数据。一般的HTML表单,data需要编码成标准形成,然后作为data参数传到Request对象。而相应的编码工作就不能用urllib2来完成了,而是我们urllib组件。
1 import urllib 2 import urllib2 3 4 url = ‘http://www.someserver.com/register.cgi‘ 5 6 values = {‘name‘ : ‘BaiYiShaoNian‘, 7 ‘localtion‘ : ‘ChongQing‘, 8 ‘language‘ : ‘Python‘, 9 } 10 11 data = urllib.urlencode(values) 12 req = urllib2.Request(url,data) 13 response = urllib2.urlopen(req) 14 the_page = response.read() 15 16 print the_page
但是我有一个疑问:就是这一份代码并不能运行,我还不知道传入数据表单的作用是什么,或者我们在抓cnblogs页面时,传入登录的信息,是不是我们就可以登录博客园了啊,所以在这里请教一下大牛,先感谢了。
正则表达式,又称为正则表示法、常规表示法。正则表达式使用单个字符串来描述、匹配一系列符号某个句法规则的字符串。通俗的说,正则表达式就是在程序中定义了字符串的某种规则,然后我们在网页源代码中找出符合这种规则的所有代码语句,不符合的就淘汰不要。
关于正则表达式的很多具体用法,我后面会边学边为大家讲解的,这里先略过。
我们可以通过Python爬虫来获取以下网页中新闻标题和新闻的ID。
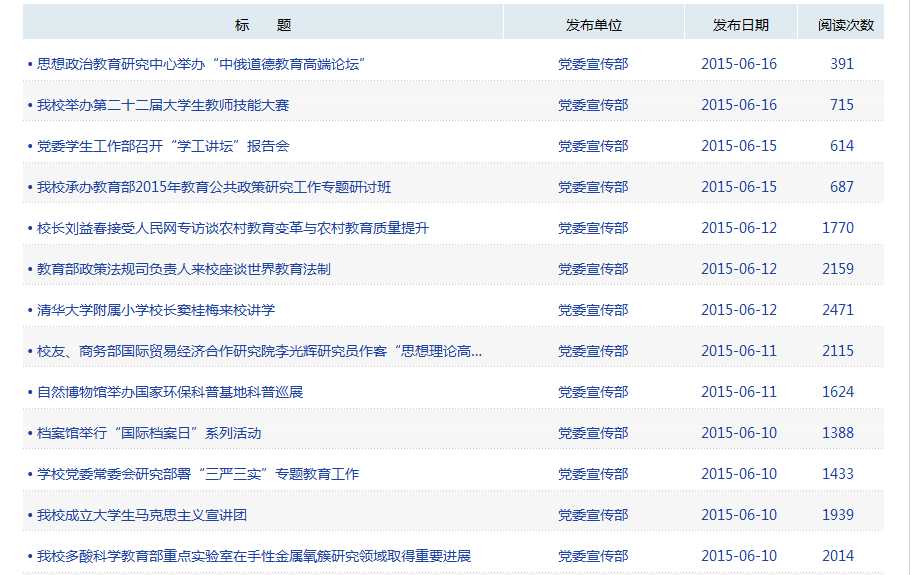
1 # -*- coding: utf-8 -*- 2 import urllib2 3 import re 4 5 # 1.获取访问页面的HMTL 6 url = "http://www.nenu.edu.cn/newslist.php?cid=1" 7 8 response = urllib2.urlopen(url) 9 html = response.read() 10 # 2.根据正则表达式抓取特定内容 11 r = re.compile(r‘<a href="intramural/content/news/(?P<ID>.{5}).*" target="_blank">(?P<Title>.+)</a>‘) 12 news = r.findall(html) 13 for i in range(len(news)): 14 ID = news[i][0] 15 title = news[i][1] 16 # data = data.decode(‘utf-8‘) 17 # title = title.decode(‘utf-8‘) 18 print title + " " + ID + " "
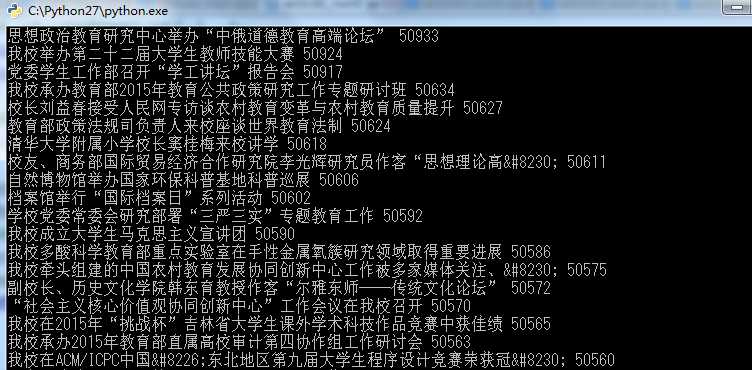
我们运行这一份代码看看结果是什么样的,是否已经成功获取。
标签:
原文地址:http://www.cnblogs.com/BaiYiShaoNian/p/4582131.html