标签:
ANSER:
首先要搞清楚,假设STL问题,那么问题出在哪里?
STL能够简单地觉得就是算法+数据结构,全部容器的算法选择和实现都是经过精心设计和严格測试的,几个主流STL实现都不会有大问题。
性能问题通常都出在内存数据操作上,内存操作有三种。内存读取、内存复制和内存分配。
所以选择合适容器的根据就是要尽量降低内存操作尤其是复制操作,比方频繁中间插入删除就不要选Vector,频繁随机訪问就不要选list。
除了选错容器这种低级错误外,性能瓶颈基本都是出在容器内的对象身上。解决方式:
allocator,实现对象内存池,仅仅有在确认内存分配是瓶颈时才用。swap来实现容器数据传递,务必确认自己清楚知道在做什么。
对数组取地址时。数组名不会被解释为其地址。等等。数组名难道不被解释为数组的地址吗?不全然如此:数组名被解释为其第一个元素的地址,而对数组名应用地址运算符(即&)时,得到的是整个数组的地址:
short tell[10]; //声明一个长度为20字节的数组(short型变量大小为2字节)
cout << tell << endl; //显示&tell[0]
cout << &tell << endl; //显示整个数组的地址从数字上说,这两个地址同样;但从概念上说,&tell[0](即tell)是一个2字节内存块的地址,而&tell是一个20字节内存块的地址。
因此。表达式tell+1将地址值加2。而表达式&tell+1将地址值加20。换句话说。tell是一个short指针(short*),而&tell是一个指向包括10个元素的short数组的指针(short(*) [10])。
您可能会问,前面有关&tell的类型描写叙述是怎样来的呢?
首先,您能够这样声明和初始化这种指针:
short (*pas) [10] = &tell; //pas指向一个有10个short元素的数组假设省略括号,优先级规则将使pas先与[10]结合。导致pas是一个包括10个short型指针的数组。因此括号是不可缺少的。
其次,假设要描写叙述变量的类型。可将声明中的变量名删除。因此。pas的类型为short(*) [10]。
另外。由于pas被设置为tell。因此*pas与tell等价,所以(*pas) [0]为tell数组的第一个元素。
回到问题本身,当int型变量的大小为4字节时,arr是一个4字节内存块的地址,而&arr是一个40字节内存块的地址。
尽管这两个内存块的起始位置同样,可是大小不同。
题主能够在代码里加上这两行,对照一下输出结果:
cout << arr + 1 << endl; //地址+4
cout << &arr + 1 << endl; //地址+40演示样例代码:
int arr[10] = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
cout << &(arr[0]) << endl;
cout << arr << endl;
cout << &arr << endl;
cout << arr + 1 << endl;
cout << &arr + 1 << endl;输出:
0013FE60
0013FE60
0013FE60
0013FE64
0013FE88
请按随意键继续. . .ANSER:
首先呢。要明确一点儿。NULL是一个无类型的东西,并且是一个宏。而宏这个东西,从C++诞生開始。就是C++之父嗤之以鼻的东西,他推崇尽量避免宏。而在他的FAQ中,也有对应的一个关于NULL与0的解释。也谈到了这一点儿。
在C++标准中。我们能够见到一个词语叫做null pointer constant,事实上在C++11标准前。是仅仅承认0为null pointer constant的。所以,在C++中,我们也常常能听到一个说法,就是赋予null pointer。应该是使用0,而非NULL。
而nullptr pointer constant这个词语在C++11公布后,最终再添了一个成员,就是nullptr。而与NULL本质不同的是,nullptr是有类型的(放了在stddef头文件里),类型是 typdef decltype(nullptr) nullptr_t; 而正是由于是有类型的,这给我们编译器实现nullptr的时候带来了很多其它细节的考虑,当然也给了使用者很多其它的保障,所以假设你的编译器支持nullptr,请一定使用nullptr!
而nullptr的出现背景,事实上是很easy的,C++哲学上来说就是C++之父一直对null pointer没有一个正式的表示感到很不满。而更project的来说,就是关于重载这个问题。
void f(void*)
{
}
void f(int)
{
}
int main()
{
f(0); // what function will be called?
}而引入了nullptr。这个问题就得到了真正解决,会很顺利的调到void f(void*)这个版本号。
好了。真的以为nullptr就这样了么? 我前面说过了nullptr是有类型的,叫做nullptr_t,这给我们编译器实现带来了诸多要考虑的东西。不幸的话让我们来举点儿奇葩样例吧。
union U
{
long i;
nullptr_t t;
};
int main()
{
U u;
u.i = 3;
printf("%ld\n",(long)u.t); // What it is? 0 or 3?
}那么这是应该符合union语意还是nullptr的语意呢?这在标准中是没有说的,我们也为此争论了很久。
当然在我们编译器的实现还是保持了nullptr的语意,结果是0。
而nullptr有类型后。还能做什么呢?那当然就是能够捕获异常了。
int main()
{
try
{
throw nullptr;
}
catch(nullptr_t)
{
}
}你扔一个NULL试试?看他应该用什么收,正是由于没有类型,所以就要用它的本质类型。比方long什么的来说。你扔一个0试试?那就也不是所谓的空指针类型了,就是要用int什么的来收了。
所以,推崇nullptr是有道理的,我们在编译器实现nullptr的时候考虑了很很多的细节。还有很多你们可能一直用不到的情况,我们都要用来測试。目的就是保障开发人员的使用。再次那句话。假设你的编译器支持nullptr,请一定使用nullptr!
最后再扯一点儿,0在C++是很奇妙的东西。比方纯虚函数为什么是用=0来设置的,不知道有没有同学去考虑过这个问题没有。
假设你深刻理解了C++哲学,这应该就是很简答的问题了。学语言嘛,一定要学到其哲学,你才干知道其之美。其之威力。尤其是C++。
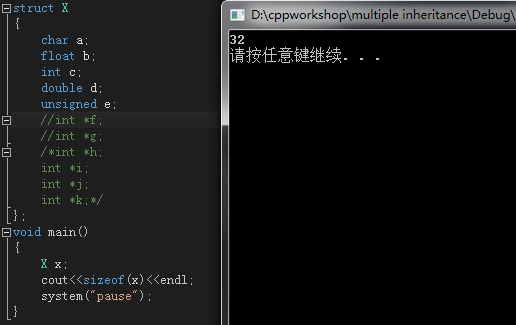
struct X
{
char a;
float b;
int c;
double d;
unsigned e;
};由于存储变量时地址对齐的要求,所以这个结构体大小应该是32。
假设我多定义一个随意型的指针
struct X
{
char a;
float b;
int c;
double d;
unsigned e;
int *f;
};依照地址对齐的要求。这样结构体大小应该是40,但它仍然是32。
我再加一个随意型的指针
struct X
{
char a;
float b;
int c;
double d;
unsigned e;
int *f;
double *g;
};结果这样结构体大小就直接变成40了。假设指针大小是地址总线大小的话,2个指针就是8字节,加上原来的32字节也刚好等于40字节,并且也满足存储变量时地址对齐的要求。
可是为什么刚才加一个指针不变。两个就变了。
一開始的时候是这种
struct X {
char a; // 1 bytes
char padding1[3]; // 3 bytes
float b; // 4 bytes
int c; // 4 bytes
char padding2[4]; // 4 bytes
double d; // 8 bytes
unsigned e; // 4 bytes
char padding3[4]; // 4 bytes
};加了一个指针以后是这种
struct X {
char a; // 1 bytes
char padding1[3]; // 3 bytes
float b; // 4 bytes
int c; // 4 bytes
char padding2[4]; // 4 bytes
double d; // 8 bytes
unsigned e; // 4 bytes
int *f; // 4 bytes
};再加一个指针以后是这种
struct X {
char a; // 1 bytes
char padding1[3]; // 3 bytes
float b; // 4 bytes
int c; // 4 bytes
char padding2[4]; // 4 bytes
double d; // 8 bytes
unsigned e; // 4 bytes
int *f; // 4 bytes
double *g; // 4 bytes
char padding3[4]; // 4 bytes
};这样就好懂多了吧?
我来补充一下匿名用户的答案。
第一个图是这种
struct X {
char a; // 1 bytes
char padding1[3]; // 3 bytes
float b; // 4 bytes
int c; // 4 bytes
char padding2[4]; // 4 bytes
double d; // 8 bytes
unsigned e; // 4 bytes
char padding3[4]; // 4 bytes
};padding1的存在是由于,offset(b)必须能够被align(b)整除,所以塞三个char。
b的偏移字节是它自身字节的整数倍,因此要加入三个字节的偏移
padding2的存在是由于,offset(d)必须能够被align(d)整除,所以塞4个char。
原因同上
对于全部基本类型,align(T)==sizeof(T),所以有了上面两条。
那align(X)是多少呢?当然就是全部成员里面align最大的那个,是align(d)==8
好了,因此sizeof(X)必须能够被align(X)整除,就有了padding3。
整个结构体的大小必须能被当中最大
align的树整除。
标签:
原文地址:http://www.cnblogs.com/gcczhongduan/p/4585626.html