标签:
字符串用单引号‘,判断用单等号=,两个单引号‘‘转义为一个单引号‘
1 --创建数据库 2 create database School; 3 --删除数据库 4 drop database School; 5 --创建数据库的时候指定一些选项 6 create database School; 7 on primary--配置主数据文件 8 ( 9 name=‘School‘,--逻辑名称,数据库内部用的名字 10 filename=‘‘,--保存路径 11 size=5MB,--设置初始化大小 12 filegrowth=10MB或10%,--设置增长速度 13 maxsize=100MB--设置最大大小 14 ) 15 log on--配置主日志文件 16 ( 17 name=‘‘,--设置逻辑名称 18 filename=‘‘,--设置路径 19 size=3MB, 20 filegrowth=3%, 21 maxsize=20MB 22 )
1 --每个项设置后面都加逗号 最后一项不加 2 --切换数据库 3 use School; 4 --在School数据库中创建一个学生表 5 create table TblStudent 6 ( 7 --表中的定义在这对的小括号中 8 --开始创建列 9 --列名 数据类型 自动编号(从几开始,增长步长) 是否为空(不写默认允许,或者写null 不允许空写 not null) 10 --tsid int identity(1,1) not null 11 --设置名为tsid 类型为int 从1开始增长,每次增长1的主键列 12 tsid int identity(1,1) primary key, 13 )
1 --查询表 2 select * from TblClass 3 --insert向表插入数据(一次只能插一条) 4 insert into TblClass(tclassName,tclassDesc) values(‘tclassName的值‘,‘tclassDesc的值‘) 5 --TblClass后面的括号设置在哪些列插入数据,value后面的括号要与前面的一一对应.如果要给除自动编号的所有列插入数据,TblClass后面的括号可省 6 --插入同时返回指定列的数据:在value前加上output inserted.列名 7 8 9 --向自动编号列插入数据 10 --先把一个选项打开 倒数第二个是列名 11 set IDENTITY_INSERT tblclass on 12 insert........ 13 --最后记得把选项关掉 14 --听过一条语句插入多条数据 15 insert into TblClass(tclassName,tclassDesc) 16 select ‘...‘,‘...‘ union 17 select ‘...‘,‘...‘ union 18 select ‘...‘,‘...‘ union 19 select ‘...‘,‘...‘ --最后一项不用union 20 --把一个表的书数据插入另一个表 21 insert into 被插表(列名,列名) 22 select 列名,列名 from 数据来源表 23 --插入汉字记得在字符串前加入N
1 update 表名 set 列名=值,列名2=值2 where 条件 and..or... 2 --如果没有条件,所有数据都会更新
1 --删除 2 delete from 表名 where 条件 3 --删除整表数!据!与drop不同,两种 4 --1,delete from 表名 5 --速度慢 6 --自动编号依然保留当前已经增长的位置 7 delete from 表名 8 --2,truncate table 表名 9 --速度快 10 --自动编号重置 11 truncate table 表名
1 --修该列 2 --删除指定列 3 alter table 表名 drop column 列名 4 --增加指定列 5 alter table 表名 add 列名(这里跟创建表一样) 6 7 --修改指定列 8 alter table 表名 alter column 列名 9 --增加约束 10 --给指定列添加主键约束 11 alter table 表名 add constraint 约束名 primary key(列名) 12 --给指定列添加非空约束 13 alter table 表名 alter column 列名 数据类型 not null 14 --给指定列添加唯一约束 15 alter table 表名 add constrainy UQ开头的约束名 unique(列名) 16 --给指定列添加默认约束 17 alter table 表名 add constraint 约束名 default(值) for 列名 18 --给指定列添加检查约束 19 alter table 表名 add constraint 约束名 check(表达式) 20 --增加外键约束 21 alter table 表名 add constraint FK_约束名 foreign key(外键列名)references 主键表名(列名) 22 23 --删除多个约束 24 alter table 表名 drop constraint 约束名,...,... 25 26 --创建多个约束 27 alter table 表名 add 28 constraint 约束名 unique(列名), 29 constraint 约束名 check(表达式), 30 constraint 约束名 foreign key(要引用列) 31 references 被引用表(列) 32 on delete cascade on update cascade --设置级联删除和更新
1 --数据检索,查询指定列的数据,不加where返回所有 2 select 列名,列名,... from 表名 where 条件 3 --用select显示东西,列名可省略,列名可以不‘‘起来,除非名字有特殊符号 4 select 值 (空格或者as) 列名 5 --top获得前几条数据,选到的都是向上取整 6 select top (数字或数字 percent) * from 表名 order by 列名 (asc//升序,默认值 desc//降序) 7 --Distinct去除查询出的重复数据,只要有一点不同(显示出来的列的内容不同)不算重复,比如自动增长的那列 8 select distinct 要显示的列 from 表名 ...
合并行叫做"联合"联合必须保证每行的数据数目与第一行一致,数据类型兼容列名为第一行的列名union all 在联合时不会去除重复数据,也不自动排序不能分别排序常用:底部总和例:select商品名称,销售总价格=(sum(销售数量*销售价格))fromMyOrdersgroupby商品名称union allselect‘销售总价:‘,sum(销售数量*销售价格)fromMyOrders1 select*from TblClass 2 jion tblstudent on TblClass.tClassId=TblStudent.tSClassId 3 --查询出两个表符合TblClass.tClassId=TblStudent.tSClassId的数据行,并显示其所有数据
1 select*from TblClass 2 jion tblstudent on TblClass.tClassId=TblStudent.tSClassId
1 select * from TestJoin1Emp emp inner join TestJoin2Dept dept on emp.EmpDeptid=dept.DeptId 2 --两者等效 3 select * from TestJoin1Emp emp , TestJoin2Dept dept 4 --假设emp与dept,行数分别是3,5.select * from 这两个表,实际会形成3*5=15行的临时表 5 --再在这个表中筛选,而这个表叫做笛卡尔表 6 where 7 emp.EmpDeptid=dept.DeptId
1 create table groups 2 ( 3 gid int identity(1,1) primary key not null, 4 gname nvarchar(10), 5 gparent int 6 ) 7 select * from groups 8 insert into groups values(‘总部‘,0) 9 insert into groups values(‘北京分公司‘,1) 10 insert into groups values(‘上海分公司‘,1) 11 insert into groups values(‘.net部门‘,2) 12 insert into groups values(‘.net部门‘,3) 13 --查询部门对应的上级部门 14 use Temp 15 select deparment.gname as ‘部门名称‘,company.gname as ‘所属部门‘ 16 from groups as deparment 17 inner join groups as company 18 on deparment.gparent=company.gid
1 ------多表查询案例分析: 2 3 -- dbo.Branch:结构表: 银行,开发商,政府房管局 4 5 --dbo.BuildingInfo: 建筑信息表。 天堂花园 1号楼。 6 7 --dbo.ProjectInfo:项目信息表。天堂花园1期。 8 9 --dbo.UserInfo:用户信息表 10 11 ---查询建筑信息表,顺便:建筑信息所属的项目名,项目所属的机构名字,项目创建人的名字 12 13 select B.*,P.ProjectName,BR.BranchName,u.UName as SubBy from dbo.BuildingInfo as B 14 left join dbo.ProjectInfo as P on B.ProjectId=P.Id 15 left join dbo.Branch as Br On P.BranchId=BR.Id 16 left join dbo.UserInfo as U On P.SubBy=U.Id
1 --模糊查询,通配符,当使用通配符必须使用like,可以在like前面加no 表示除了匹配数据的数据 2 --%,表示匹配任意多个字符 3 --例子,查询以张开头的字符串 4 select * from 表名 where 列名 like N‘张%‘ 5 --查询包含%的字符串 6 select * from 表名 where 列名 like ‘%[%]%‘ 7 8 -- _ ,表示一个任意字符 9 -- [ ],表示匹配一个字符,这个字符是[]访问内的通常是[0-9][a-z] 10 -- ^ 非
1 --例子,统计学生表中每个班的男生人数,且显示id 2 select 3 班级id=tsclassId 4 男同学人数=count(*) 5 from TblStudent 6 where tsgender=‘男‘ 7 group by (tsclassId,这就是group by包含的列,可以逗号添加多个列,意味着分组后在分组) 8 --有时候要把一些信息放到group by后才能放到select,这时不一定担心,在group by 语句写过多会造成过多的分组, 9 --例子如下 10 --列1 列2 列 3 11 --A aa 少壮不努力 12 --B bb 老大LOL 13 --如果group 列1,列2 因为当列1为A,列2必须aa,列1B,列2必须bb时最终只会会分成两个组,所以有时候不用担心分组过多 14 15 16 --对得到的组进一步筛选(having) 17 18 --例子:按笔记编号分组,筛选出班级人数大于10的班级 19 select 20 tsclassId as 班级编号 21 count(*) as 人数 22 from TbStudent 23 --如果这里有where,where这不能用聚合函数 24 group by tsclassId 25 having count(*)>10//having的内容只能是select选择的内容
select * from TblStudent as ts where exists//如果查到数据返回true ( select * from TblClass as tc where tc.tclassId=ts.tsclassId and (tc.tclassname=‘高一一班‘or tc.tclassname=‘高二二班‘) )
1 select top 5 * from Customers where CustomerId not in 2 (select top (n-1)*5 CutomerID from Customers order by CustomerId asc) 3 order by CustomerId asc
1 --每页7条,看第4页。 2 select * from 3 ( 4 select 5 row_number() over(order by CustomerId asc) as Rn , 6 * 7 --over()子句把数据按CustomerId排序 8 --通过row_number()函数吧查到的数据添加一条编号列,列名为Rn 9 --再通过编号得到想要的数据 10 from Customers 11 ) as Tbl where Tbl.Rn between (4-1)*7+1 and 4*7
1 select b.studentid,b.score ,b.courseName , 2 (select count(*) from StudentScore where courseName=b.courseName group by courseName) as ‘参加该科目考试的额人数为‘ 3 from StudentScore as b 4 order by b.studentid,courseName 5 --等效于 6 select studentid,score,courseName, 7 count(*) over (partition by courseName) as‘参加该科目考试的额人数为‘ 8 from StudentScore 9 order by studentid,courseName
create view v_Areaasselect * from 表alter view v_Areaasselect * from 表drop view v_Areaselect * from v_Areaselect * from v_Areaorder by....1 select a1.AreaId,a1.AreaName,a2.AreaName 2 from TblArea as a1 inner join TblArea as a2 on a2.AreaId=a1.AreaPId 3 --这个select用了两个AreaName,这样不能确定视图的列名,会报错
1 update bank set balance=balance-1000 where cid=‘0001‘ 2 update bank set balance=balance + 1000 where cid=‘0002‘ 3 --模拟银行转账,如果第一条出错,第二条还是会执行 4 --所以这里需要用到事务
1 begin transaction 2 declare @sumErrors int=0 3 --执行操作 4 update bank set balance=balance-1190 where cid=‘0001‘ 5 --立刻验证一下这句话是否执行成功了。。 6 set @sumErrors=@sumErrors+@@error 7 update bank set balance=balance+1190 where cid=‘0002‘ 8 set @sumErrors=@sumErrors+@@error 9 10 --验证是否执行成功 11 if @sumErrors=0 12 begin 13 --表示没有出错 14 commit transaction --将事务提交 15 end 16 else 17 begin 18 rollback --失败则回滚 19 end
1 create procedure usp_Add1 2 @num1 int, 3 @num2 int 4 as 5 begin 6 print @num1+@num2 7 end 8 --带默认值的存储过程 9 create procedure usp_Add2 10 @num1 int=3, 11 @num2 int 12 as 13 begin 14 print @num1+@num2 15 end 16 --带输出参数的存储过程 17 create procedure usp_Add3 18 @num1 int, 19 @num2 int, 20 @num3 int output 21 as 22 begin 23 @num3=@num1+@num2 24 end
1 exec usp_Add1 5,4 --输出9 2 3 exec sp_helptext ‘sp_databases‘ --看指定存储过程源码的 4 5 exec usp_Add2 @num2=8 --输出11,usp_Add2如果给@num2赋值必须写@num2=...,否则会认为给@num1赋值 6 7 delcare @answer int--跟c#里面out参数差不多,声明与调用都要写output 8 exec usp_Add3 6,6,@answer ouput
1 alter procedure usp_fenye 2 @pageSize int,--每页的记录条数 3 @pageIndex int,--用户当前要查看第几页 4 @pageCount int output --输出参数,返回总共有几页 5 as 6 begin 7 select * 8 from 9 ( 10 select *,Rn=row_number()over(order by tSid) 11 from TblStudent 12 ) as stu 13 where Rn between (@pageIndex-1)*@pageSize+1 and @pageIndex* @pageSize 14 15 --设置输出参数的值 16 declare @datacount int=(select count(*) from TblStudent) 17 set @pageCount=ceiling(@datacount/(@pageSize*1.0)) 18 --向较大的数取整 19 end
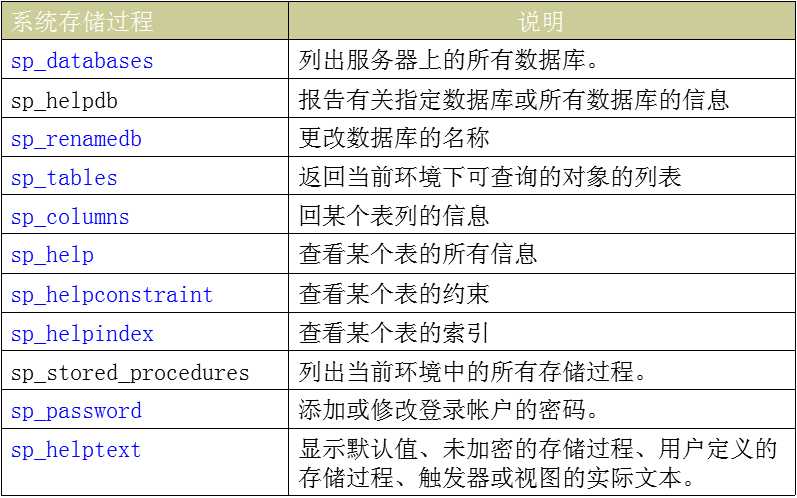
1 --聚集索引创建 2 create clustered index 名字 on 表(列) 3 --非聚集索引创建 4 create index 名字 on 表(列) 5 --删除索引(略有不同) 6 drop index 表名.索引名
1 --create trigger 触发器名 on 表名 2 create trigger tri_delete_TblPerson on TblPerson 3 --for/after/instead of(for与after都表示after触发器) delete/insert/update,可以写多个触发器类型用逗号隔开 4 instead of delete,insert 5 as 6 begin 7 --执行内容,会用到selected表或inserted表 8 end
1 --1.定义一个游标 2 declare cur_Area cursor fast_forward for select top 100 * from Area 3 --2.打开游标 4 open cur_Area 5 6 --3.查询使用游标 7 fetch next from cur_Area 8 while @@fetch_status=0 9 begin 10 fetch next from cur_Area 11 end 12 13 --4.关闭游标 14 close cur_Area 15 --5。释放资源 16 deallocate cur_Area
DROP TABLE 语句显式除去临时表,否则临时表将在退出其作用域时由系统自动除去:
(1)、当存储过程完成时,将自动除去在存储过程中创建的本地临时表。由创建表的存储过程执行的所有嵌套存储过程都可以引用此表。但调用创建此表的存储过程的进程无法引用此表;
(2)、所有其它本地临时表在当前会话结束时自动除去;
(3)、全局临时表在创建此表的会话结束且其它任务停止对其引用时自动除去。任务与表之间的关联只在单个Transact-SQL语句的生存周期内保持。换言之,当创建全局临时表的会话结束时,最后一条引用此表的Transact-SQL语句完成后,将自动除去此表。
3、示例代码
(1)创建
标签:
原文地址:http://www.cnblogs.com/Recoding/p/4590960.html