标签:
摘要:在PHP爬虫(1)中详细了介绍了CURL抓取HTML数据的技术。采集数据处理也是爬虫技术中非常重要的部分。处理HTML数据可以用字符串查找,也可以利用正则表达式,但采用Dom处理是最高级的方法。
现在我们要抓取中国军网首页“军媒要闻要论”第一条内容,
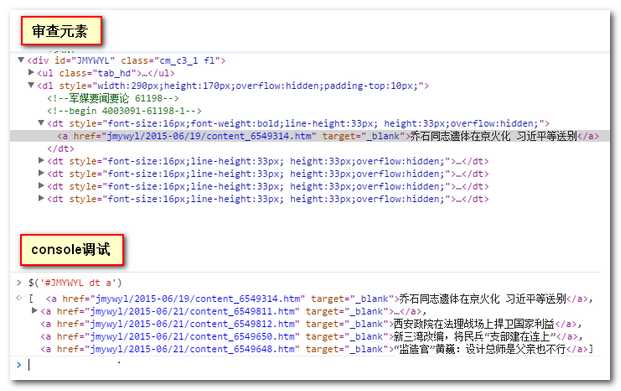
通过浏览器工具查看网页元素,通过console获取数据。通过下图我们可以看到,在浏览器中我们可以方便调用Jquery的dom查找函数,轻松找到数据,PHP中是否也有这样的工具可以很方便的处理DOM?
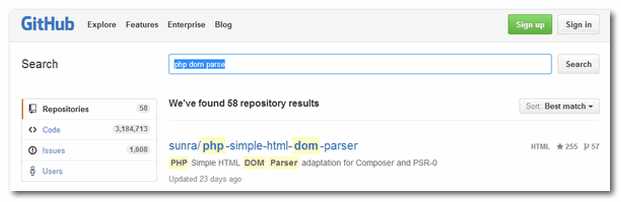
在github上查找php dom parse,我们找到sunra/php-simple-html-dom-parser,使用用户还挺多的。下面我们介绍如何使用PhpDomParse组件,分别介绍直接引用、composer、ThinkPhp中如何使用。
1.直接引用
首选下载组件文件夹,在当前工程目录中执行
git clone https://github.com/sunra/php-simple-html-dom-parser.git
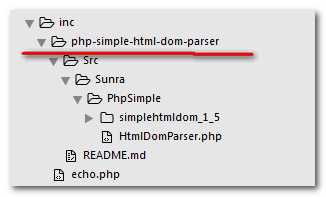
此时,工程目录下就会多出php-simpple-html-dom-parser文件夹,文件夹目录如下图
引用HtmlDomParaer.php
<?php include "./php-simple-html-dom-parser/Src/Sunra/PhpSimple/HtmlDomParser.php"; use Sunra\PhpSimple\HtmlDomParser; $url = "http://www.81.cn"; $dom = HtmlDomParser::file_get_html( $url ); $u = $dom->find("#JMYWYL dt",0); $title = $u ->find(‘a‘,0); echo $title->innertext; ?>
2.Composer调用方法
在工程目录下安装Composer.phar,创建composer.json文件,
{ "require": { "sunra/php-simple-html-dom-parser": "v1.5.0" } }
运行,php compose.phar install
Composer会根据composer.json内容,下载需要的文件,安装成功之后,工程文件夹如下,
代码如下,系统会自动加载\Sunra\PhpSimple\HtmlDomParse
<?php require __DIR__ . ‘/vendor/autoload.php‘; $url = "http://www.81.cn"; $dom = \Sunra\PhpSimple\HtmlDomParser::file_get_html( $url ); $u = $dom->find("#JMYWYL dt",0); $title = $u ->find(‘a‘,0); echo $title->innertext; ?>
3、thinkphp框架
笔者日常也是使用TP框架的,也许有的读者没在TP中引入其他框架。TP提供了进入框架的机制,我们将Sunra文件夹放在“安装路径-->ThinkPHP->Library->Vendor”目录中,结构如下图所示,
工程代码如下
class IndexController extends Controller { public function index(){ } public function dom() { Vendor(‘Sunra.PhpSimple.HtmlDomParser‘); $url = "http://www.81.cn"; //$dom = \Sunra\PhpSimple\HtmlDomParser::file_get_html( $url ); $dom =file_get_html( $url ); $u = $dom->find("#JMYWYL dt",0); $title = $u ->find(‘a‘,0); echo $title->innertext; } }
附录
php composer.phar install,出现下列错误,
SSL3_GET_SERVER_CERTIFICATE:certificate verify failed
解决办法,
(1)wget http://curl.haxx.se/ca/cacert.pem
(2)修改php.ini,添加
openssl.cafile="/opt/lampp/cacert.pem"
标签:
原文地址:http://www.cnblogs.com/jbexploit/p/4592527.html