标签:
最近在学习lucene原理方面的知识,将学习中学到的知识和问题记录下来,今天学习的主要内容就是关于索引方面的内容。我们知道lucene是实现全文检索的工具包,要在工程里面加入搜索的功能还需要基于lucene的api进行开发。那么全文检索的步骤分为哪几步呢。全文检索大体上分为两个步骤,索引的创建和搜索索引。于是乎全文检索就涉及到如下几个问题:
1.如何创建索引。2.如果搜索索引。3.索引里面存储的信息都有什么。
索引里面存储的都有什么信息呢,可以用一下的例子来说明,一个文件包含多个字符,当要查询一个文件中是否包含某个字符串的时候,也就是已知文件,想要查询字符串相对容易,也即从文件到字符串的映射,而全文检索要解决的问题是给定一个字符串查询出来那几个文件包含这个字符串,也就是已知字符串求文件,即从字符串到文件的映射。如果索引能够存储从字符串到文件的映射关系,则会大大提高检索的速度。由于从字符串到文件的映射是文件到字符串的映射的反向过程,所以保存的这种信息被称为反向索引。
反向索引保存的信息一般如下:
假设我的文档集合里面有100个文档,为了方便表示,为文档编号,从1到100,得到如下图所示的结构。
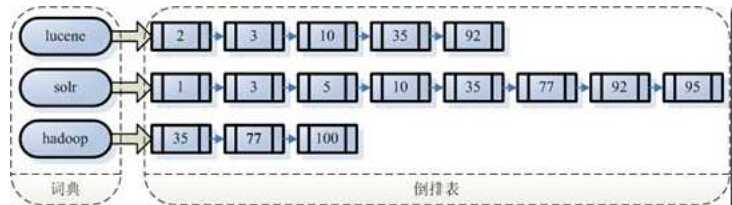
左边保存的是字符串,称为词典。
每个字符串指向的是包含此字符串的文档链表,此文档链表称为倒排表。
有了索引便使保存的信息和要搜索的信息保持一致,加快了搜索的速度。
比如说我们要搜索即包含solr和hadoop的文档,可以分为以下步骤,
1.通过solr的倒排表取到包含solr的文档链表。
2.通过hadoop的字符串去到包含hadoop的文档链表。
3.通过合并前面两步得到的文档链表即可找到即包含solr又包含hadoop的文档列表,加快了查找的速度。
虽然查找变的方便了,但是多了创建索引的过程,但是通过索引查找的优势就是索引建好之后就不必在重新创建了,可以达到一次创建多次使用的效果。
创建索引的过程一般如下:
第一步.一些要索引的源文档(Document),为了说明以字符串为例,如以下字符串:
Students should be allowed to go out with their friends, but not allowed to drink beer.
第二步.将源文档传给分词组件,分词组件一般做以下几件事情:
1.将文档分成一个一个的单词。
2.去除标点符号。
3.去掉停词。所谓停词就是指那些最普通的单词,由于没有特别的意义,不能区分不同的文档,因而大多数情况下不能成为搜索的关键词。
经过分词得到的结果成为词元。
第三步,将得到的词元传给语言处理组件。
语言处理组件主要是针对得到的词元做一些语言方面的处理。比如在英语里面把词元变成小写,将单词转为词根等。经过语言处理组件得到的信息叫做词。
第四步,将得到的词传给索引组件。
索引组件主要做以下几件事情:1,利用得到的词创建一个字典。2,对字典按字母顺序进行排序。2,合并相同的词成为倒排列表。
到此创建索引的过程就完成了。
标签:
原文地址:http://www.cnblogs.com/wangxiaomeng/p/4596603.html