标签:
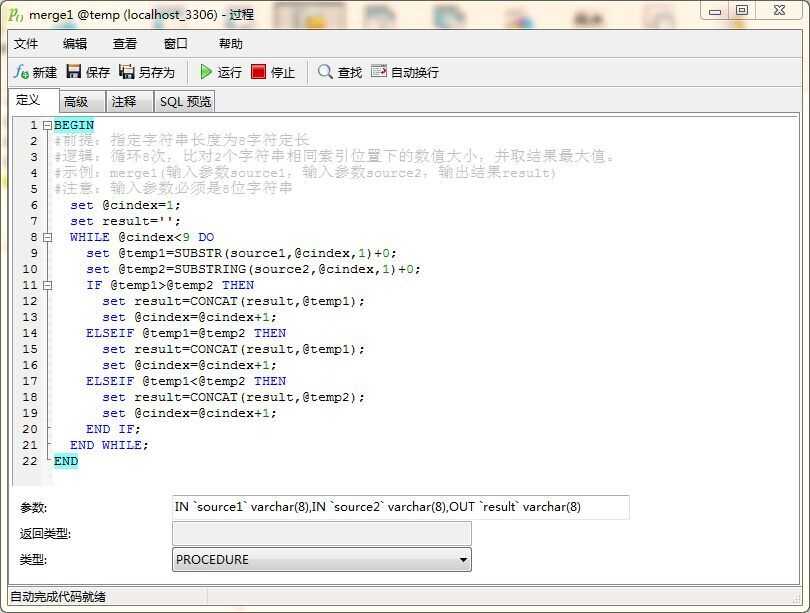
BEGIN
#前提:指定字符串长度为8字符定长
#逻辑:循环8次,比对2个字符串相同索引位置下的数值大小,并取结果最大值。
#示例:merge1(输入参数source1,输入参数source2,输出结果result)
#注意:输入参数必须是8位字符串
set @cindex=1;
set result=‘‘;
WHILE @cindex<9 DO
set @temp1=SUBSTR(source1,@cindex,1)+0;
set @temp2=SUBSTRING(source2,@cindex,1)+0;
IF @temp1>@temp2 THEN
set result=CONCAT(result,@temp1);
set @cindex=@cindex+1;
ELSEIF @temp1=@temp2 THEN
set result=CONCAT(result,@temp1);
set @cindex=@cindex+1;
ELSEIF @temp1<@temp2 THEN
set result=CONCAT(result,@temp2);
set @cindex=@cindex+1;
END IF;
END WHILE;
END
这个过程是用来 合并 2个 8为varchar类型字符串的
参数 见截图
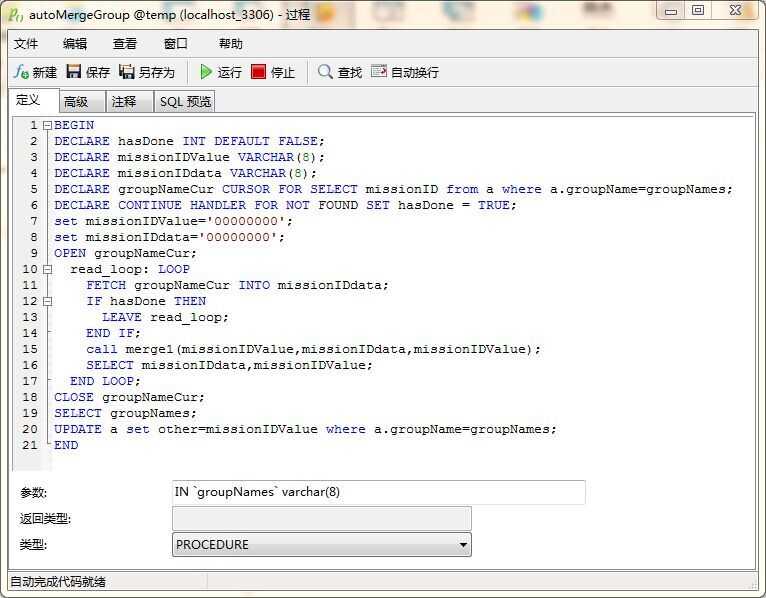
BEGIN
DECLARE hasDone INT DEFAULT FALSE;
DECLARE missionIDValue VARCHAR(8);
DECLARE missionIDdata VARCHAR(8);
DECLARE groupNameCur CURSOR FOR SELECT missionID from a where a.groupName=groupNames;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET hasDone = TRUE;
set missionIDValue=‘00000000‘;
set missionIDdata=‘00000000‘;
OPEN groupNameCur;
read_loop: LOOP
FETCH groupNameCur INTO missionIDdata;
IF hasDone THEN
LEAVE read_loop;
END IF;
call merge1(missionIDValue,missionIDdata,missionIDValue);
SELECT missionIDdata,missionIDValue;
END LOOP;
CLOSE groupNameCur;
SELECT groupNames;
UPDATE a set other=missionIDValue where a.groupName=groupNames;
END
这个函数是用来 把分组数据进行逐条合并的。它需要一个 分组名称
然后根据分组名称去循环调用 merge1 函数,并把最终结果更新到同组数据的 other 列中
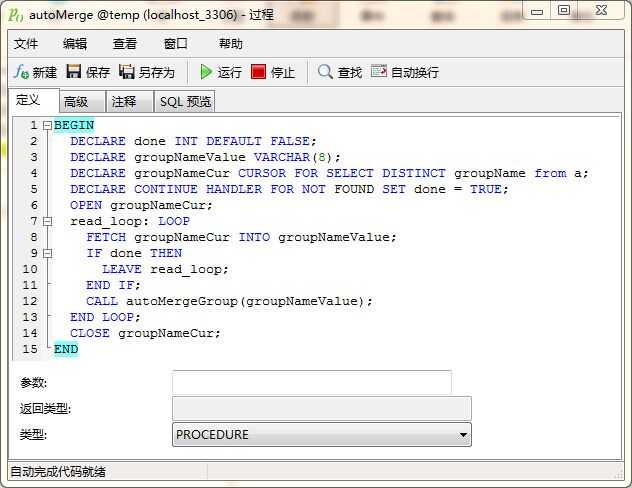
BEGIN
DECLARE done INT DEFAULT FALSE;
DECLARE groupNameValue VARCHAR(8);
DECLARE groupNameCur CURSOR FOR SELECT DISTINCT groupName from a;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
OPEN groupNameCur;
read_loop: LOOP
FETCH groupNameCur INTO groupNameValue;
IF done THEN
LEAVE read_loop;
END IF;
CALL autoMergeGroup(groupNameValue);
END LOOP;
CLOSE groupNameCur;
END
这个是自动化合并的入口函数。它负责对数据进行分组,并循环调用 autoMergeGroup 过程,就是上面的存储过程。
你的程序在执行时,只需要调用这个存储过程就可以了,就能做到:先把数据分组,再循环每组执行。在每组执行中,循环查询每条数据,把当前条和参考值‘00000000‘最合并操作
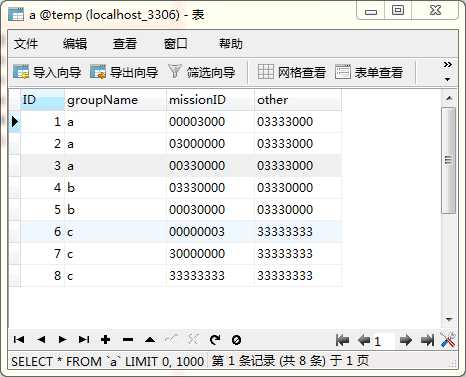
这是我的a表执行结果截图
varchar类型,必须提供长度,否则 就无法检验到底问题出在那里
自动分组+合并完整的sql脚本
标签:
原文地址:http://www.cnblogs.com/zh1989/p/4596881.html