标签:
因为使用需要,在自己小本上建了四个虚拟机,打算搭建一个1+3的hadoop分布式系统。
环境:hadoop2.7.0+ubuntu14.04 (64位)
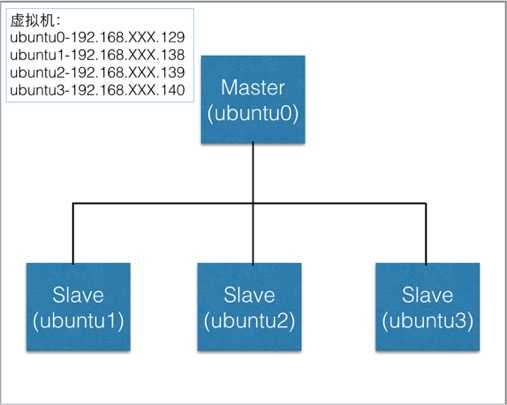
首先分别为搭建好的虚拟机的各主机重命名
方法:vi /etc/hostname
例如:ubuntu0 ubuntu1 ubuntu2 ubuntu3
一. 配置hosts文件
通过ifconfig命令查看虚拟机的IP,配置hosts文件
方法:vi /etc/hosts
192.168.186.XXX ubuntu0
192.168.186.XXX ubuntu1
192.168.186.XXX ubuntu2
192.168.186.XXX ubuntu3
二. 建立hadoop运行账号
创建hadoop用户组:sudo addgroup hadoop
创建hadoop用户:sudo adduser -ingroup hadoop hadoop
为hadoop用户添加权限
方法:sudo vi /etc/sudoers
添加hadoop ALL=(ALL:ALL)ALL
->切换hadoop用户:su hadoop
三. ssh配置(master-slave免密码登录)
1)每个节点分别产生公私密匙(生成目录为.ssh)
ssh-keygen -t dsa -P ‘‘ -f ~/.ssh/id_dsa
cd .ssh
cat id_dsa.pub >> authorized_keys
单机测试免密码登录:ssh localhost(或主机名)
退出命令:exit
2)让主节点通过ssh登录子节点
scp hadoop@ubuntu0:~/.ssh/id_dsa.pub ./master_dsa.pub
cat master_dsa.pub >> authorized_keys
在子节点重复上诉操作。
四. 下载并解压hadoop安装包
1安装JAVA环境
sudo apt-get install openjdk-7-jdk
查看安装结果:java -version
2下载hadoop2.7.0
解压:sudo tar xzf hadoop-2.7.0.tar.gz
解压hadoop在/usr/local/hadoop下:
sudo mv hadoop-2.7.0 /usr/local/hadoop
修改权限:sudo chmod 777 /usr/local/hadoop
3配置~/.bashrc
查看java的安装路径:update-alternatives --config java
配置.bashrc文件:vi ~/.bashrc 在末尾添加:
#HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-i386
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
#HADOOP VARIABLES END
执行source ~/.bashrc ,使添加的环境变量生效。
4.编辑/usr/local/hadoop/etc/hadoop/hadoop-env.sh
添加
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export YARN_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
5.编辑/usr/local/hadoop/etc/hadoop/yarn-env.sh
export YARN_CONF_DIR="${YARN_CONF_DIR:-$HADOOP_YARN_HOME/etc/hadoop}"
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
五. 配置namenode,修改site文件(/usr/local/hadoop/etc/hadoop/)
1、配置core-site.xml
<property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property>
2、yarn-site.xml
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property>
3、创建mapred-site.xml,
cp mapred-site.xml.template mapred-site.xml
并添加
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
4、配置hdfs-site.xml
cd /usr/local/hadoop/
mkdir hdfs
mkdir hdfs/data
mkdir hdfs/name
编辑打开hdfs-site.xml
<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/hdfs/data</value> </property>
六. 配置masters和slaves文件
在两个文件中分别填入适合的主机名
七. 向节点复制hadoop
scp -r ./hadoop ubuntu1:~
scp -r ./hadoop ubuntu2:~
scp -r ./hadoop ubuntu3:~
八、格式化namenode
hdfs namenode -format
注意:上面只要出现“successfully formatted”就表示成功了。
九.启动hadoop
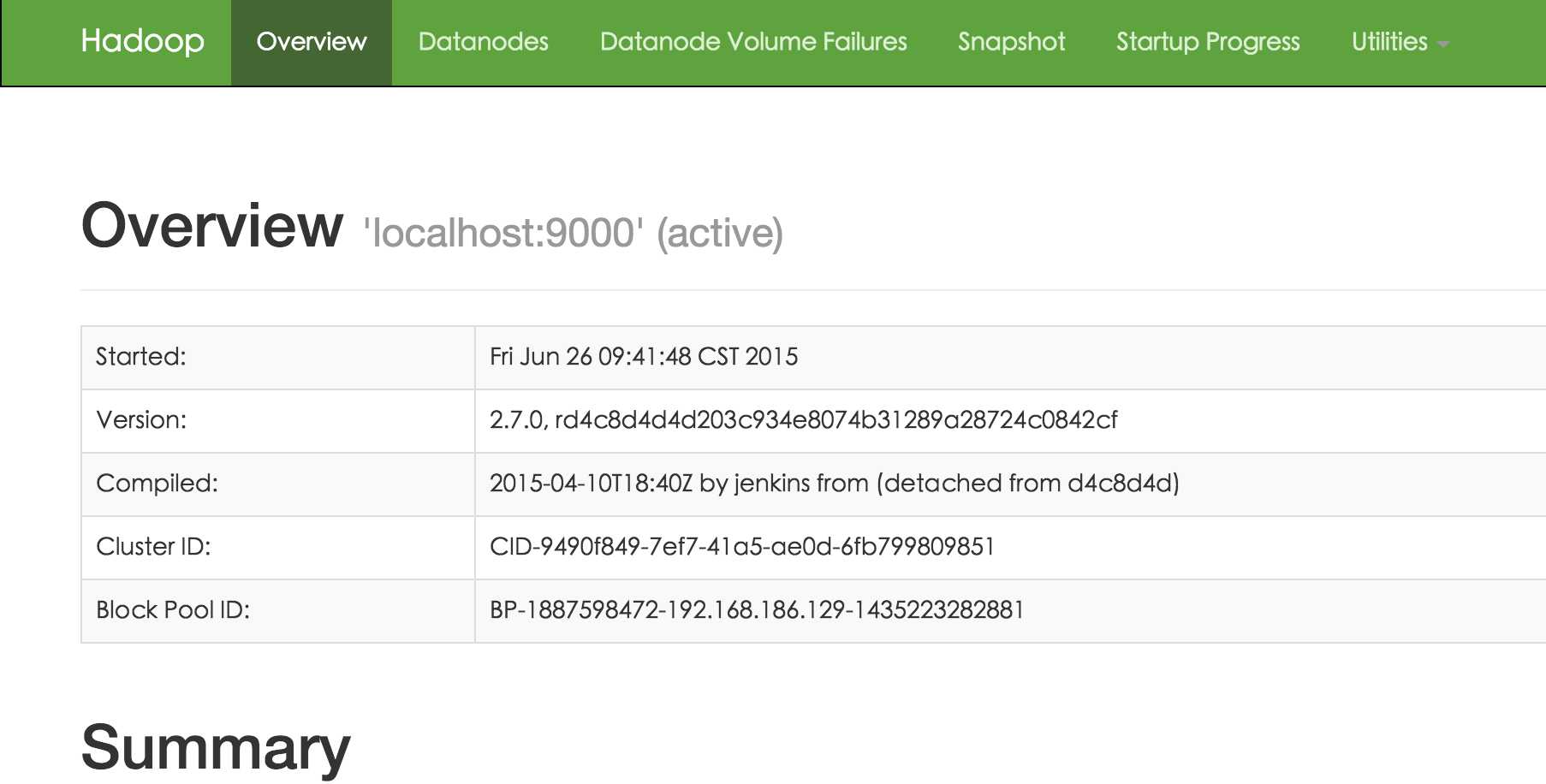
浏览器打开 http://localhost:50070/,会看到hdfs管理页面
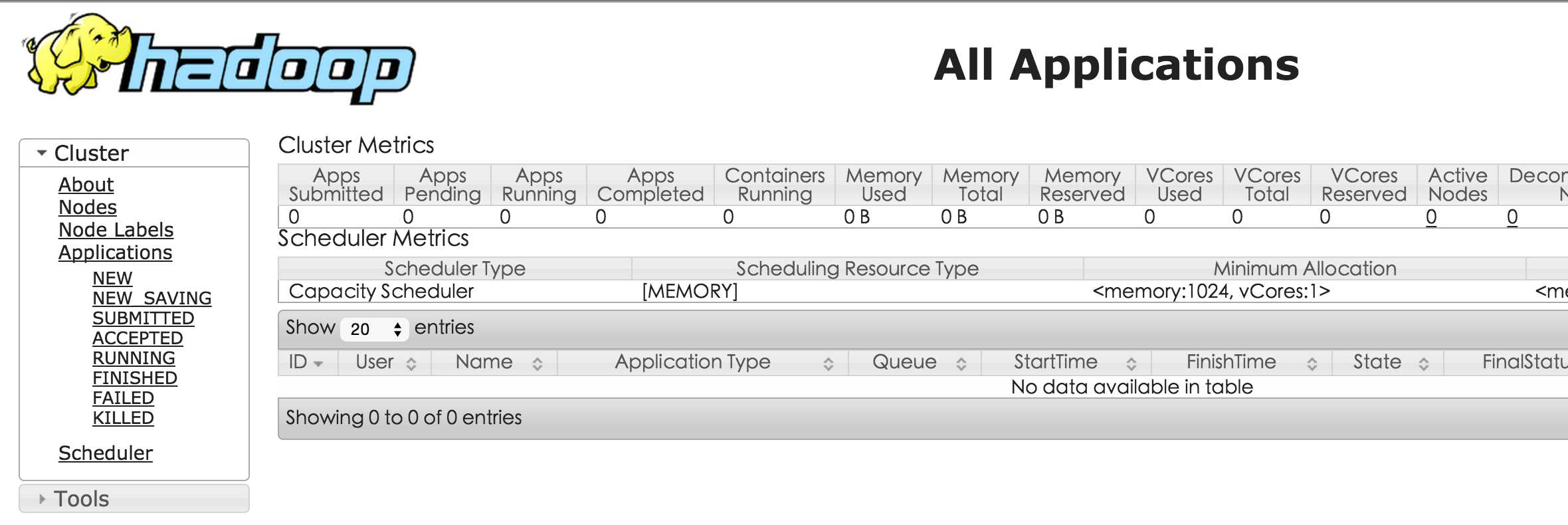
浏览器打开http://localhost:8088,会看到hadoop进程管理页面
hadoop2.7.0分布式系统搭建(ubuntu14.04)
标签:
原文地址:http://www.cnblogs.com/ryuham/p/4601783.html