标签:
本篇文章主要介绍.NET中6个重要的概念:栈,堆,值类型,引用类型,装箱,拆箱。文章开始介绍当你声明一个变量时,编译器内部发生了什么,然后介绍两个重要的概念:栈和堆;最后介绍值类型和引用类型,并说明一些有关它们的重要原理。
最后通过一个简单的示例代码说明装箱拆箱带来的性能损耗。
在.NET程序中,当你声明一个变量,将在内存中分配一块内存。这块内存分为三部分:1,变量名;2,变量类型;3,变量值。
下图揭示了声明一个变量时的内部机制,其中分配的内存类型依据你的变量类型。.NET中有两种类型的内存:栈内存和堆内存。在接下来的内容中,我们会了解到这两种类型的详细内容。
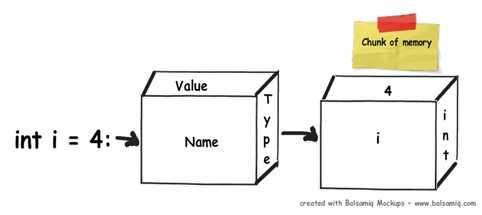
为了明白什么是栈和堆,先让我们看下下面示例代码的内部机制:
public void Method1(){
// Line 1
int i=4;
// Line 2
int y=2;
//Line 3
class1 cls1 = new class1();
}
这里一共有3行代码。让我们一下逐行看一下它们是如何执行的:
第1行:当这行代码执行时,编译器为它分配一小块栈内存。运行时栈负责提供程序所需的内存;
第2行:程序继续执行。如同名字一样,栈在第一块内存的顶部分配了一块内存。你也可以认为是模块或零件一块一块叠起来;
内存的分配与释放遵循后进先出(后进先出)逻辑,换句话说,内存只能在示例中i内存块的顶部分配或释放。
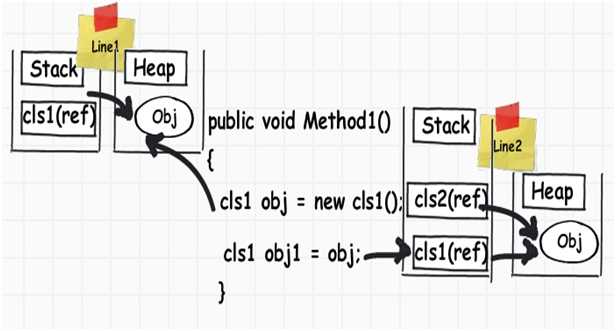
第3行:在第3行,我们创建了一个对象。当该行执行时,编译器在站上创建了一个指针,真实的对象存储在另一种叫“堆”的内存中。"堆"并不跟踪运行内存,它更像一堆随时可以访问的对象。堆用于动态分配内存。这里需要着重说明的是引用指针是分配在栈上。声明Class1 cls1时并不会给Class1的实例分配内存,而是分配一个栈变量cls1(并设置为null),然后把它指向“堆”。
退出方法:当方法退出时,它释放了栈上所有内存变量。换句话说,栈上所有的"Int"变量都依据后进先出的逻辑被释放掉了。要注意,此时不会释放堆内存,这种内存稍后会被“垃圾收集器”释放。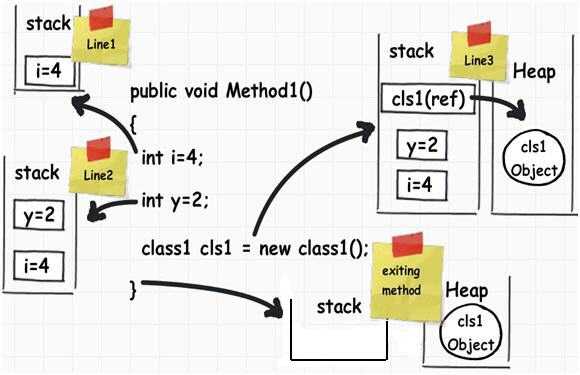
现在可能会有很多朋友奇怪为什么要分配2种内存,而不是仅用一种内存。
如果仔细观察,你会发现基本类型并不复杂,他们值包含简单的值,如i=0。对象数据类型很复杂,它们会引用其它对象或基本类型。换句话说,它要保持其它多种多样的引用,而每种类型必须存在内存中。对象类型需要动态内存而基本类型需要静态内存。如果需要分配动态内存,那么就分配到堆上;反之在栈上。
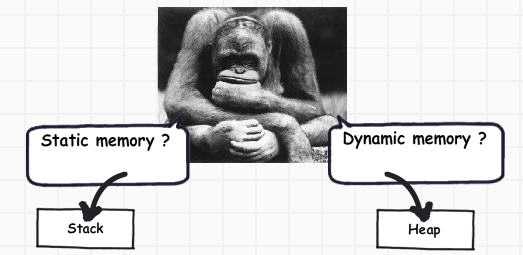
现在我们明白了栈和堆,接下来看值类型和引用类型。值类型的数据和内存在同一个位置,而引用类型是一个指向内存的指针。
下面示例是一个整形数据类型变量i被赋给另一个整形数据类型变量j。它们的内存值都分配在栈上。当我们把一个int值分配给另外一个int值时,需要创建一个完全不同的拷贝。换句话说,你可以改变其中任何一个而不会影响另外一个。这种数据类型被称为值类型。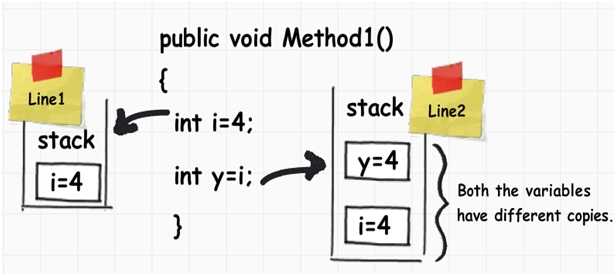 当我们创建一个对象,并把一个对象赋给另外一个对象时,它们的指针指向相同的内存(如下图,当我们把obj赋给obj1时,它们指向相同的内存)。换句话说,我们改变其中一个,会影响到另外一个,这种类型称为引用类型。
当我们创建一个对象,并把一个对象赋给另外一个对象时,它们的指针指向相同的内存(如下图,当我们把obj赋给obj1时,它们指向相同的内存)。换句话说,我们改变其中一个,会影响到另外一个,这种类型称为引用类型。
在.NET中,依据数据类型,变量被分配到堆或栈上。“string”和"Object"是引用类型,其他基本类型被分配到栈上,是值类型,如下图: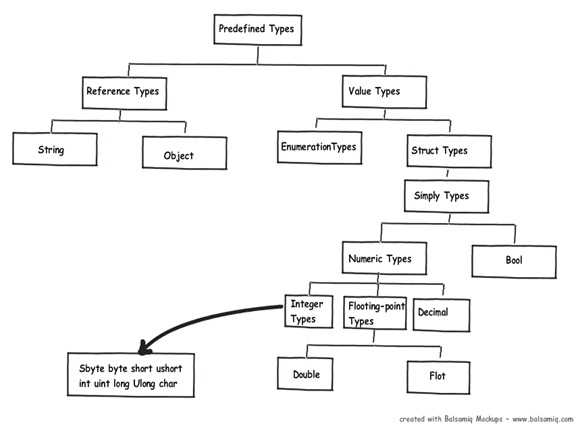
通过上面学习,我们学到了很多有用的东西,其中最有用的是明白了当把数据从栈移动到堆上时会有性能损失。如下图实例,当我们把一个值类型装箱为引用类型时,数据从栈移动到堆上。反之,数据从堆移动到栈上。这种在堆和栈之间的移动带来了性能的损失。数据从值类型转变为引用类型的过程称为“装箱”,反之为“拆箱”。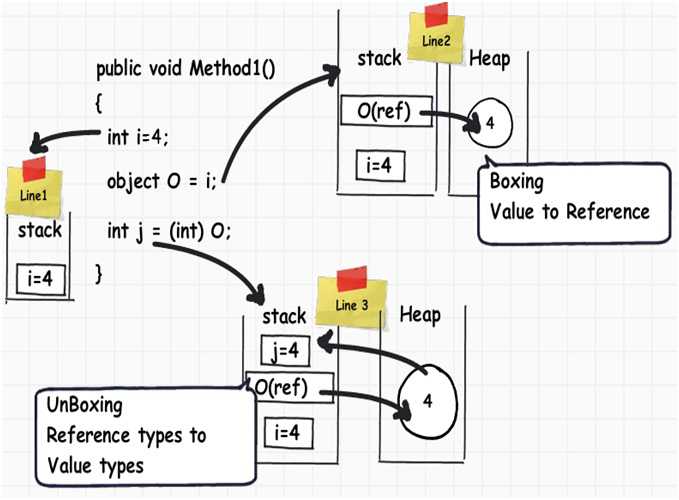
如果编译上面的代码,在ILDASM中看IL代码就会发下如何进行装箱拆箱操作的,如下:
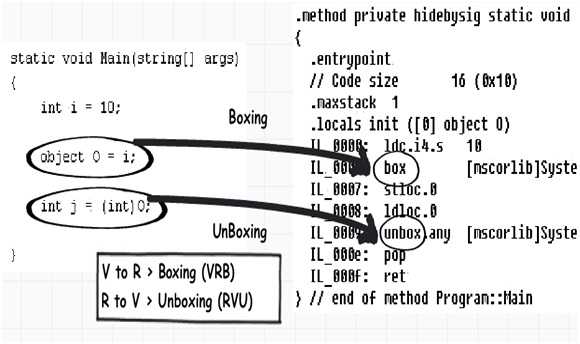
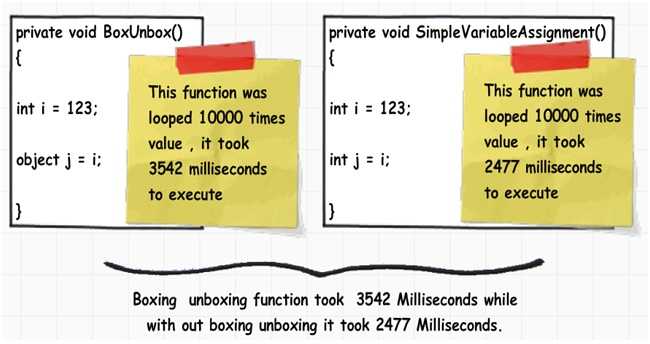
为了揭示装箱拆箱如何影响性能,我们把下面代码运行10000次。一个函数有装箱操作,另一个只有简单代码。我们用简单的计时器看它们的运行时间。装箱函数耗时 3542 MS,无装箱操作的耗时2477MS。这说明在实际项目中,除非必须,否则应避免装箱,拆箱操作。
备注:
最近在CodeProject上看到<6 important .NET concepts: - Stack, heap, Value types, reference types, boxing and Unboxing>一文,个人觉得非常好,所以就翻一下给不想看英文的同学。由于能力有限,翻译的不好,望大家多多包涵。
6个重要的.NET概念:栈,堆,值类型,引用类型,装箱,拆箱
标签:
原文地址:http://www.cnblogs.com/qixuejia/p/4609912.html