标签:
今天挑战下百度音乐抓取,先用Chrome分析下请求的链接。
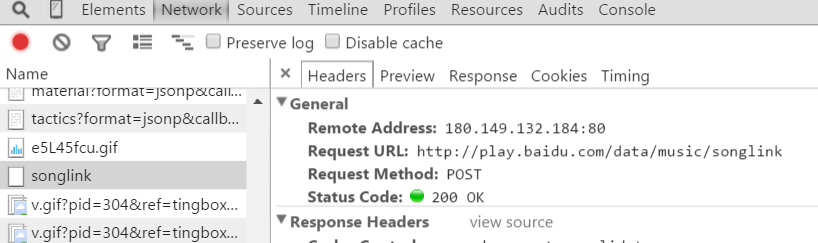
最关键的就是这个链接
http://play.baidu.com/data/music/songlink
请求这个带上songid就能返回给你音乐的json,那么怎么来获取songid呢?
点开 http://music.baidu.com/tag,找个标签进去。然后查看页面源码。发现有以下片段。

在每首歌曲的li元素的data-songitem里面恰巧包含我们需要的sid。ok,目标明确了,首先请求百度音乐的音乐标签页,然后获得sid。然后请求
http://play.baidu.com/data/music/songlink
并且带上我们组装好的sid。最后根据返回json获取我们需要的信息。
代码如下(刚学Python,写的不是太好):
#!/usr/bin/python
#coding=utf-8
__author__ = ‘zhm‘
import urllib
import urllib2
import re
from json import *
#
SONG_TAG_URL = ‘http://music.baidu.com/tag/%E7%BB%8F%E5%85%B8%E8%80%81%E6%AD%8C‘
SONG_LINK_URL = ‘http://play.baidu.com/data/music/songlink‘
def getContent(url,pattern):
try:
f=urllib2.urlopen(url)
result = f.read();
content = re.compile(pattern, re.DOTALL)
style = content.search(result)
if style:
result = style.group(0)
return result
else:
return None
except Exception ,e:
print e
if __name__=="__main__":
for i in range(0,1000,25):
#根据给出的百度音乐分类地址解析出songid
result = getContent(SONG_TAG_URL+‘?start=‘+unicode(i)+‘&size=25&third_type=0‘,‘<ul>.*?</ul>‘)
sids = []
sidPattern = re.findall(""sid":.*?,"",result)
for sid in sidPattern:
sids.append(re.sub(‘,"‘,‘‘,re.sub(‘"sid":‘,‘‘,sid)))
# print sids
#将songid构造成post请求参数
formdata = { "songIds" : ",".join(sids)}
data_encoded = urllib.urlencode(formdata)
# print data_encoded
songList = urllib2.urlopen(SONG_LINK_URL,data_encoded)
songListJson = songList.read()
# print songListJson
#json 转字典
song_dict = JSONDecoder().decode(songListJson)
#获取songList
song_data_dict = song_dict.get("data").get("songList")
for sond_data in song_data_dict:
song_name = sond_data.get(‘songName‘)
song_artistName = sond_data.get(‘artistName‘)
song_format = sond_data.get(‘format‘)
song_link = sond_data.get(‘songLink‘)
if song_name is None or song_artistName is None or song_format is None or song_link is None:
continue
print song_name+‘--‘+song_artistName+‘.‘+song_format+u‘ 下载链接为:‘+song_link
#下载方法此处就省略了。
标签:
原文地址:http://my.oschina.net/zhmlvft/blog/472466