标签:
HTTP协议介绍:
绝大多数的Web开发,都是构建在Http协议之上的Web应用,理解和掌握Http协议,将有助于我们更好的学习和掌握Servlet和Jsp技术,以及其他相关的Web开发技术。
网络基础知识:
网络编程的目的就是指直接或间接地通过网络协议与其他计算机进行通讯。网络编程中有两个主要的问题,一个是如何准确定位网络上一台或多台主机,另一个就是找到主机后如何可靠高效的进行数据传输。
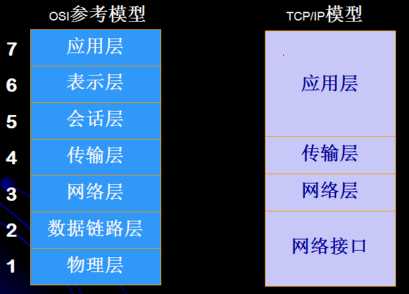
ISO/OSI(Open System Interconnection)七层参考模型:应用层(处理网络应用)、表示层(数据表示)、会话层(主机间通信)、传输层(端到端的连接)、网络层(寻址和最短路径)、数据链路层(介质访问(接入))、物理层(二进制传输)
OSI各层所使用的协议:
应用层:远程登录协议Telnet、文件传输协议FTP、超文本传输协议HTTP、域名服务DNS、简单邮件传输协议SMTP、邮局协议POP3等。
传输层:传输控制协议TCP(Transfer Control Protocol,面向连接的可靠的传输协议,类比打电话)、用户数据报协议UDP(User Datagram Protocol无连接的,不可靠的传输协议,类比写信)。
TCP和UDP的比较:
那么问题来了,既然有了保证可靠传输的TCP协议,为什么还需要非可靠传输的UDP协议呢?
主要原因有二:
端口:在互联网上传输的数据都包含有用来识别目的地的IP地址和端口号。IP地址用来标识网络上的计算机,而端口号用来指明该计算机上的应用程序,端口使用一个16位的数字来表示,范围从0~65535,1024以下的端口号保留给预定义的服务。例如:http使用80端口,比如访问百度的时候可以在www.baidu.com后面加一个‘:80‘,而加上‘:81‘,访问就失败了。
数据封装:一台计算机要发送数据到另一台计算机,数据首先必须打包,打包的过程称为封装。封装就是在数据前面加上特定的协议头部。
TCP/IP模型:
TCP/IP起源于美国国防部高级研究规划署(DARPA)的一项计划——实现若干台主机的相互通信,现在TCP/IP已称为Internet上通信工业标准,TCP/IP模型包括四个层次:应用层、传输层、网络层、网络接口。
TCP/IP与OSI参考模型的对应关系如下:
HTTP协议:
Http(Hypertext Transfer Protocol)超文本传输协议,是现今WWW上应用得最多的协议,目前的版本为1.1;Http是应用层协议,当你上网浏览网页的时候,浏览器和服务器之间就会通过Http在Internet上进行数据的发送和接收;http是一个基于请求/响应模式的,无状态的协议(request/response based,stateless protocol)
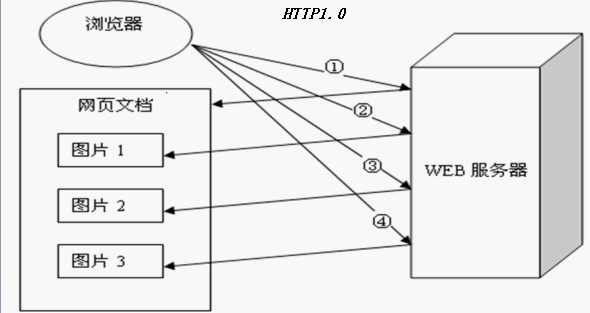
浏览器与服务器通信的过程(HTTP1.0):客户发起连接;客户发送请求;服务器响应请求;服务器关闭连接
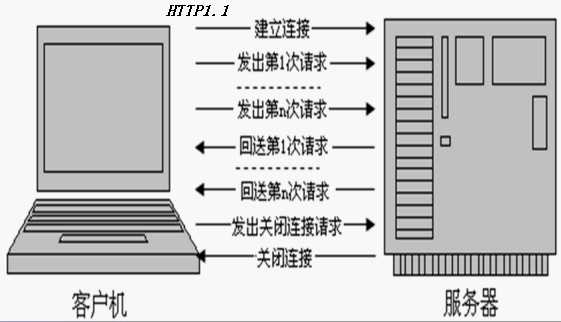
持续连接(Persistent Connections):
一个Web站点每天可能要接收上百万的用户请求,为了提高系统效率,HTTP1.0规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接,服务器完成请求处理后立即断开TCP连接,服务器不跟踪每个客户也不记录过去的请求。但是,这也造成了一些性能上的缺陷,例如,一个包含有许多图像的网页文件中并没有包含真正的图像数据内容,而只是指明了这些图像的URL地址,当Web浏览器访问这个网页文件时,浏览器首先由发出针对该网页文件的请求,当浏览器解析Web服务器返回的该网页文档中的HTML内容时,发现其中的<img>图像标签后,浏览器根据<img>标签中的src属性所指定的URL地址再次向服务器发出下载图像数据的请求。
下面通过图示的方式对这两种协议进行区分:
HTTP URL:
格式:http://host[:port][abs_path]
其中http表示要通过HTTP协议来定位网络资源;host表示合法的Internet主机域名或IP地址(以点分十进制格式表示);port用于指定一个端口号,拥有被请求资源的服务器主机监听该端口的TCP连接。如果port为空,则使用缺省的端口80;abs_path指定请求资源的URI(Uniform Resource Identifier,统一资源标识符),如果URL中没有给出abs_path,那么当它作为请求URI时,必须以"/"的形式给出。通常这个工作浏览器就帮我们完成了。
HTTP请求:
客户端通过发送HTTP请求向服务器请求对资源的访问。HTTP请求由三部分组成,分别是:请求行,消息报头,请求正文。
标签:
原文地址:http://www.cnblogs.com/Code-Rush/p/4610986.html