标签:
大学课本复习笔记,知识点总结。
2012-08-15
数据模型中的 型,Type, 学号,姓名。。。。
值,Value, 0001, Ender。。。。。
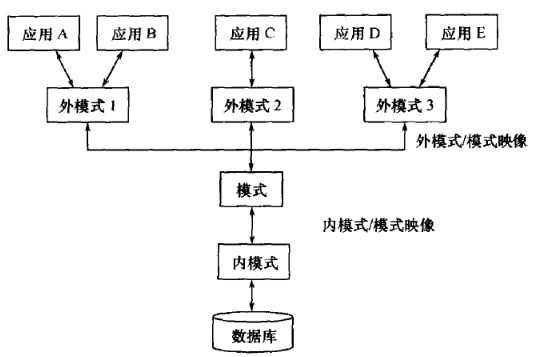
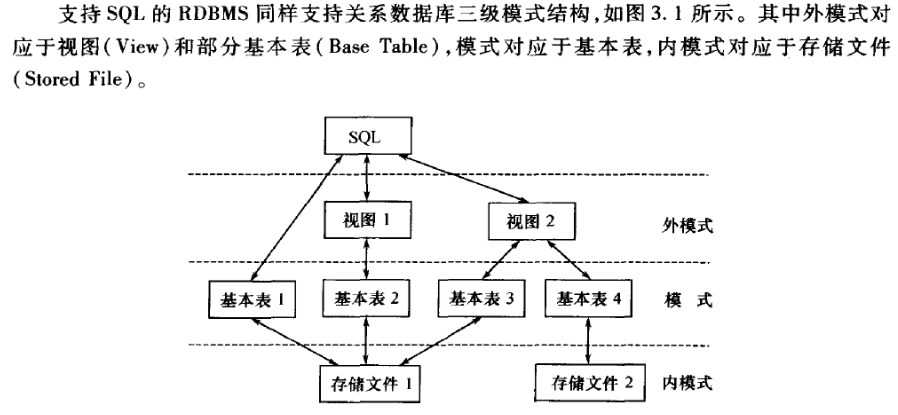
数据库系统的三级模式,两级映射,
外模式,External Schema/Sub Schema,
是用户能看得到的直接使用的。一个数据库有多个外模式,应用于用户的不同需求。但每个应用程序只能使用一个外模式。保证安全。每个用户只能访问对应的外模式。
模式,Schema,
是数据库中全体数据的逻辑结构和特征的描述,只涉及 型Type的描述。模式的一个具体值,叫实例Instance。是所有用户公共的数据视图。不涉及硬件物理存储,也与具体用户的应用程序无关。一个数据库只有一个模式。是数据库在逻辑级别上的视图。
内模式,Internal Schema/Storage Schema,
一个数据库只有一个内模式,是数据物理存储方式的描述。是否压缩,是否加密,如何索引.....
2012-08-17
完整性,Integrity,
1. 实体完整性,entity integrity主键不能为空。空值即为不可标实,是不允许的。
2.参照完整性,referential integrity, 学生的专业号必须存在于专业的专业号里面。学生的专业号取值,需要参照专业的专业号。
学生(学号,姓名,专业号)
专业(专业号,专业名称)
3.用户定义完整性,User-defined integrity,
视图是多个表综合导出的虚表。本身不存储数据,视图上可以再定义视图。
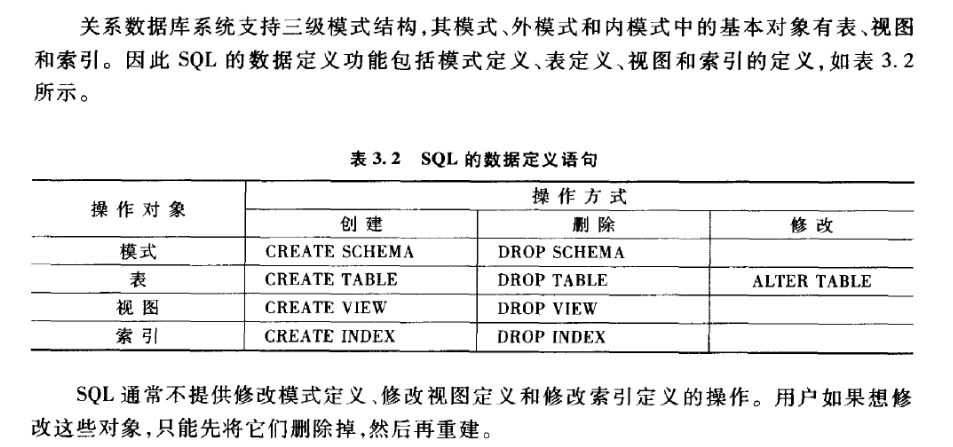
SCHEMA。
创建Schema其实是定义了一个命名空间,在这个空间中可以进一步定义本Schema包含的数据库对象(表,视图,索引)。
为用户Ender创建一个模式TEST,并为其建立一张表TBL。
CREATE SCHEMA TEST AUTHORIZATION ENDER
CREATE TABLE TBL(
ID NUMERIC(10,0),
NAME CHAR(20)
);
DROP SCHEMA CASCADE,级联,删除模式的同时删除下属的所有数据库对象。
RESTRICT,限制,当本模式中包含有数据库对象时,不允许执行,必须先删除下属对象后,才能删除此模式。
TABLE。
DROP TABLE CASCADE,级联,删除模式的同时删除索引,视图,触发器,存储过程,函数。
RESTRICT,限制,此表上不能有视图,触发器,存储过程,函数。
INDEX.
CREATE UNIQUE,每个索引值对已唯一记录,
CLUSTER,聚簇索引,建立此索引后表中的记录实际物理存放顺序按照此索引。
每个表只能建一个。当向表里面添加新记录时,导致表的记录顺序变更很大,
因此,对于经常变更的列,不适合建立聚簇索引。
INDEX ON TABLE_NAME(COLUMN1_NAME, COLUMN2_NAME.......)
索引一般采用B+树、HASH来实现,是关系数据库内部实现的技术,属于内模式。无需用户干预,建立索引为的是减少查询时间,但频繁的数据增加,删除,更新,会使得系统花费很多时间来维护索引,反而降低效率。
DROP INDEX INDEX_NAME;
建表时,若没有指定Shema,将会建立在当前的Shema中,用SHOW search_path查看当前搜索路径。
用SET search_path TO "SCHEMA_NAME", PUBLIC;设置当前搜索路径。
聚集函数
SELECT COUNT (DISTINCT SEX) FROM STUDENT;
SELECT MAX|MIN|AVG|SUM FROM STUDENT.
GROUP BY
将结果按指定列,如果只相等,则分为一组。
SELECT COURSE_NBR, COUNT(STUDENT_NBR) FROM SC GROUP BY COURSE_NBR; 各门课程及其选课人数,
此语句将选择出的记录按COURSE_NBR 分组,然后对每一组用COUNT 函数计算。
若要分组后还要求按条件筛选,用HAVING
SELECT STUDENT_NBR FROM SC GROUP BY STUDENT_NBR HAVING COUNT(*) > 3; 查询选课3门以上的学生。
此语句先用GROUP BY 将STUDENT_NBR 分组,再用COUNT 对每一组计算。
WHERE, HAVING 区别,
WHERE 作用于表,视图,从中选记录; HAVING 作用于组,从中选择组。
视图,VIEW
新建视图时并不会立即查询,只是存放结构,等到访问此视图时才会真正查询。不可以使用ORDER BY, DISTINCT. 可以使用聚集函数和GROUP BY,称为分组视图。
例子:基于多个表,连接查询,查询0002学生的名字和英语成绩。
CREATE VIEW STUDENT_GRADE(STUDENT_ID,STUDENT_NAME,STUDENT_GRADE)
AS
SELECT STUDENT.STUDENT_ID, STUDENT.STUDENT_NAME, COURSE.GRADE
FROM STUDENT, COURSE
WHERE STUDENT.ID=0002 AND
STUDENT.STUDENT_ID=COURSE.STUDENT_ID AND
COURSE.COURSE_NAME=‘ENGLISH‘;
对视图的更新,最终要被转换为对基本表的更新。
一般行列子集视图可以更新,每个DBMS规定不同。
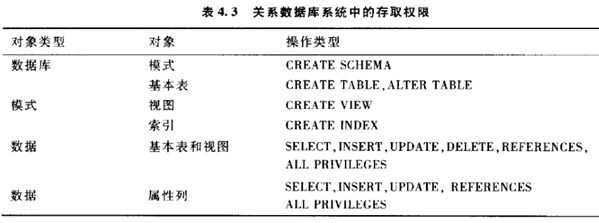
安全性
自主存取控制,DAC,Discretionary Access Control。通过GRANT, REVIKE 控制实现。
GRANT SELECT
ON TABLE STUDENT
TO ENDER;
GRANT ALL PRIVILEGES
ON TABLE STUENT, COURSE
TO ENDER, TOTO;
GRANT UPDATE(STUDENT_NAME), SELECT
ON TABLE STUDENT
TO ROCKY
WITH GRANT OPTION; (ROCKY 可以将此权限授予其他用户)
REVOKE UPDATE(STUDENT_NAME)
ON TABLE STUDENT
FROM ROCKY
CASCADE|RESTRICT
级联 |拒绝 ,默认值因DBMS不同而异。
角色,Role。
角色是一组权限的集合。为相同权限的多个用户创建一个角色。简化权限管理。
CREATE ROLE SELECT_STUDENT;
用GRANT 分配,
GRANT SELECT
ON STUDENT
TO SELECT_STUDENT;
也可以将角色分配给角色
GRANT SELECT_STUDENT, ... ...
TO SELECT_COURSE
WITH ADMIN OPTION; (可以转接,分配给其他角色)
回收,REVOKE
REVOKE SELECT
ON STUDENT
FROM SELECT_STUDENT;
审计,AUDIT, 费时间空间。但安全。DBA 操作。
AUDIT ALTER, UPDATE
ON STUDENT;
NOAUDIT ALTER
ON STUDENT
当审计开关打开(audit_trail为TRUE)时,可以在系统表SYS_AUDITTRAIL中看到审计信息。
2012.08.18
数据库完整性。
触发器, Trigger。
行触发器,FOR EACH ROW,
语句触发器,FOR EACH STATEMENT,
UPDATE STUDENT SET AGE=‘0‘; 如果有100条数据,行触发器,执行100次; 语句触发器只一次。
如果插入/更新的学生分数小于60,则给60.
CREATE TRIGGER INSERT_STUDENT_GRADE
BEFORE INSERT OR UPDATE ON STUDENT
FOR EACH ROW
AS BEGIN
IF (new.STUDENT_GRADE < 60)
new.STUDENT_GRADE:=60
END-IF;
END
如果学生姓名有变化,则新加一条数据到变更表。
CREATE TRIGGER UPDATE_NAME
AFTER UPDATE ON STUDENT
FOR EACH ROW
AS BEGIN
IF (new.STUDNET_NAME<>old.STUDENT_NAME)
THEN INSERT INTO NAME_CHANGE VALUES(old.STUDENT_NAME,new.STUDENT_NAME, CURRENT_USER);
END IF;
END;
DROP TRIGGER UPDATE_NAME
ON STUDENT;
范式,Normal Form
1NF,每一列都不可再分,是基本条件,若不满足,则不能称其为关系型数据库。
2NF,必须有主键,且其他属性完全依赖于主键。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。
3NF,属性不依赖于其他非主属性。要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表,如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,而不应该将所有属性存放于一个表中,否则就会有大量的数据冗余。
数据库系统设计
三分技术,七分管理,十二分的基础数据。
数据库编程,
嵌入式SQL(Embedded SQL),PL/SQL(Procedural Language/SQL),ODBC(Open Data Base Connectivity),JDBC(Java Data Base Connectivity),OLEDB(Object Linking and Embedding DB)。
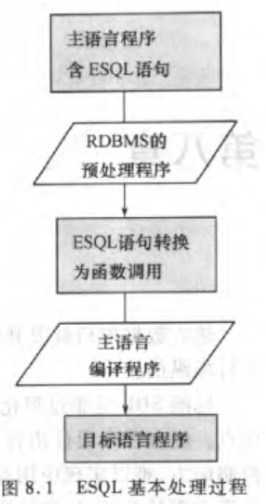
ESQL,一般采用预编译方法,由DBMS预处理程序对源程序扫描,识别出ESQL语句,并转换成主语言调用的语句,以便于主语言编译程序识别,并进行编译。
为便于预处理程序识别SQL语句,每个语句都以EXEC SQL 开头。
1. DB向主语言传递SQL执行状态信息,主要使用通信区SQLCA(SQL Communication Area);
SQL执行后,向SQLCA写入执行状态,应用程序从SQLCA读取这些状态。
用EXEC SQL INCLUDE SQLCA来定义;SQLCA 中有变量叫SQLCODE存放执行SQL的返回码;
2. 主语言向DB提供SQL语句的参数,主要使用主变量Host Variable;
SQL语句中使用主语言的变量,叫做主变量。分输入主变量和输出主变量。
所有主变量必须在BEGIN DECLARE SECTION 和END DECLARE SECTION 之间声明。为了与数据库对象名(表名,视图名,列名)区分,主变量要加“:”。
3. 执行SQL后的结果交给主语言处理,主要使用主变量和Cursor;
SQL面向集合,而主语言面向记录。游标用于协调。游标是用户开辟的数据缓冲区,存放SQL结果。
建立连接,EXEC SQL CONNECT TO (HOSTNAME:PORT)
关闭连接,EXEC SQL DISCONNECT
不使用游标的,查询结果为单记录的,非current形式的insert,delete,update。若结果不是单条,DBMS会返回错误信息到SQLCA。
必须使用游标的,查询结果为多条,current的insert,delete,update。
动态SQL
临时组装SQL语句,主变量,查询的列,条件等。
准备SQL,EXEC SQL PREPARE <语句变量名> FROM <SQL 语句主变量>.
Example:
EXEC SQL BEGIN DECLARE SECTINO
const char * stmt = “INSERT INTO ENDERTEST(?);”;
EXEC SQL END DECLARE SECTION;
EXEC SQL PREPARE mystmt FROM :stmt
EXEC SQL EXECUTE mystmt USING 100.
存储过程,属于SQL-invoked routines。
使用PL/SQL编写。PL/SQL是对SQL的扩展。效率高,降低通信量,一次执行一系列SQL。
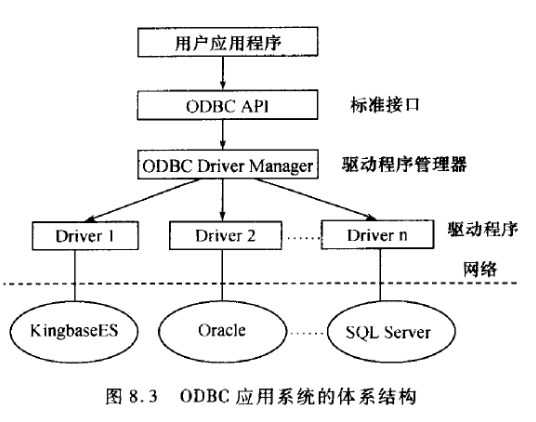
ODBC
开放数据库互连(Open Database Connectivity ODBC)是Microsoft引进的一种早期数据库接口技术。
是微软公司开放服务结构(WOSA,Windows Open Services Architecture)中有关数据库的一个组成部分
它是ADO的前身。ADO (ActiveX Data Objects) 是一个用于存取数据源的COM组件。
它提供了编程语言和统一数据访问方式OLE DB的一个中间层。允许开发人员编写访问数据的代码而不用关心数据库是如何实现的,而只用关心到数据库的连接。访问数据库的时候,关于SQL的知识不是必要的,但是特定数据库支持的SQL命令仍可以通过ADO中的命令对象来执行。
应用程序调用的是标准ODBC函数和SQL。应用层使用ODBC API调用接口和数据库进行交换。
数据源是用户最终要访问的数据,包含DB的位置和类型信息。是一种数据连接的抽象。
每个数据源都有一个数据源名DSN。用DNS代替用户名,服务器名,数据库名。
API一致性,
语法一致性,
查询优化
事务处理,Transaction
特性:ACID
原子性(Atomicity),一个事务要么都做,要么都不做。
一致性(Consistency),
隔离性(Isolation),不被并发事务干扰。
持续性(Durability),事务一旦提交,则是永久的。
END.
数据库系统概论 复习笔记。
标签:
原文地址:http://www.cnblogs.com/ECNB/p/4611282.html