标签:
CUDA在执行的时候,每一个host里面的一个个kernel按照线程网格的概念在显卡硬件上执行,每一个线程网格又可以包含多个线程块,每个线程块又可以包含多个线程。
当程序执行时,每一个线程就相当于一个士兵,一个军队的将军就相当于host。当我们要执行某一个军事任务时,我们就要分配各个不同的任务,每个任务有一部分人完成,假设有M个任务,这就是M个kernel。而每一个任务(kernel)就交给一个grid看管,这里grid就相当于副将或者千户(grid管理线程的多少和GPU的性能有关)当执行具体任务的时候,一个grid又会将任务细分为block(百户)。等到bolck这一层时,就可以直接管理thread了。
在当前模型下,每一个block中的thread联系都很好,但是不同block之间的通信就不是很好了。同样的,同一个grid之间的bolck联系很好,但是不同grid之间的通信也不好。每一个grid都会从host那里分配到资源和任务,在这个grid中的block都可以分到资源。
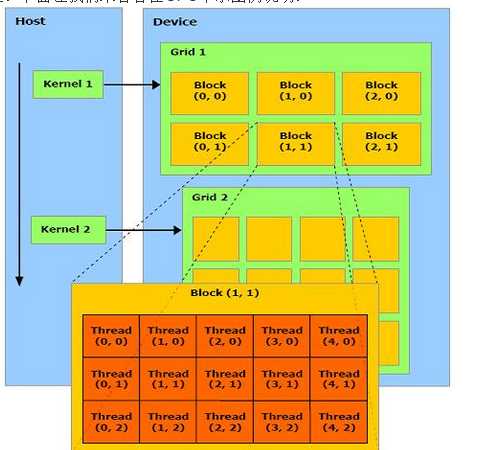
注意,这个编号可以很快找到每个thread的位置,这样就可以根据位置查到每一个thread的编号,反之也成立。
注:在二维线程中,线程的遍历实际是按列进行的。
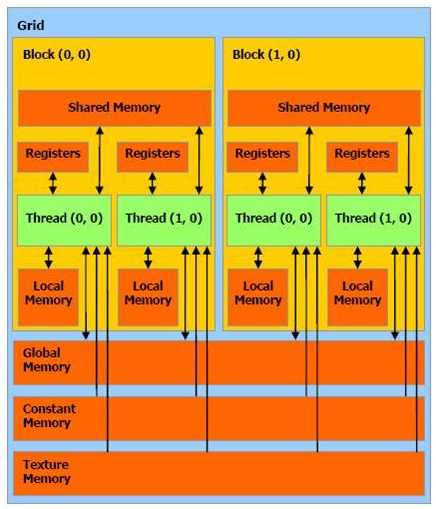
CUDA内存模型如下图所示:
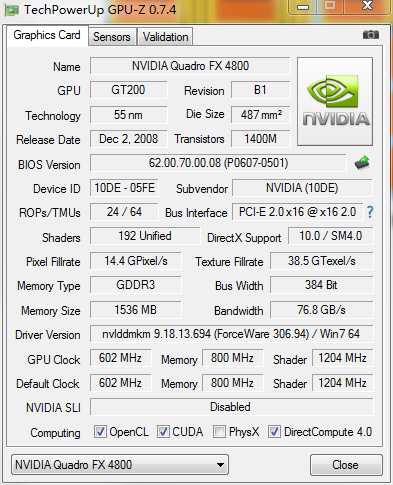
检查显卡的参数,这里使用GPU-Z工具,本机显卡参数如下图所示:
CUDA是扩展了的C语言,因为要在GPU显卡上面运行,规定了一个特定的环境,因此也定义了一些特定的变量。
线程分配的id在线程启动时就固定了,不会再更改。
标签:
原文地址:http://www.cnblogs.com/zhoushengpuBlogs/p/4611601.html