标签:
在了解JSON协议之前,朋友们可以先去了解一下JSON的基础知识,和ASCII基本分布,关于JSON一些常识请见这里;
JSON (JavaScript Object Notation)是一种数据交换格式,是以JavaScript为基础的数据表示语言,是在以下两种数据结构的基础上来定义基本的数据描述格式的:1) 含有名称/值对的Object;2) 以”[“,",","]"组成的数组。对于 JSON,下例:形如{“name”:”tom”,”age”:23}就表示一个JSON 对象,其有两个属性,值分别为tom和23。key必须为string。JSON支持的基本数据类型,包括Number,Boolean, null, String; boolean, null类型值不能加” “,不然会当做string来出来,再通过object, array来组合成丰富的类型结构。
来看看Thrift中JSON常用标签的定义:
private static final byte[] COMMA = new byte[] {‘,‘}; //json object中键值对之间, json array中元素之间的 private static final byte[] COLON = new byte[] {‘:‘}; //json object中key : value private static final byte[] LBRACE = new byte[] {‘{‘}; //json object开始标签 private static final byte[] RBRACE = new byte[] {‘}‘}; //json object结束标签 private static final byte[] LBRACKET = new byte[] {‘[‘}; //json array开始标签 private static final byte[] RBRACKET = new byte[] {‘]‘}; //json array结束标签 private static final byte[] QUOTE = new byte[] {‘"‘}; //json 字符串标签 private static final byte[] BACKSLASH = new byte[] {‘\\‘}; //json中转义 private static final byte[] ZERO = new byte[] {‘0‘}; // 0字符
Unicode编码形式:
private static final byte[] ESCSEQ = new byte[] {‘\\‘,‘u‘,‘0‘,‘0‘};
JSON中字符串是由双引号包围的任意数量的unicode字符结合,当然还要包含通过‘\‘转义字符(不多),如下;
private static final String ESCAPE_CHARS = "\"\\/bfnrt"; //需要转义的字符 ‘"‘ , ‘\‘ , ‘ /‘ ,‘b‘ , ‘f‘ , ‘n‘ ,‘r‘ ,‘t‘ private static final byte[] ESCAPE_CHAR_VALS = { ‘"‘, ‘\\‘, ‘/‘, ‘\b‘, ‘\f‘, ‘\n‘, ‘\r‘, ‘\t‘, // 转义字符对应的字节数组 };
ASCII表前48字符表:
1 private static final byte[] JSON_CHAR_TABLE = { 2 /* 0 1 2 3 4 5 6 7 8 9 A B C D E F */ 3 0, 0, 0, 0, 0, 0, 0, 0,‘b‘,‘t‘,‘n‘, 0,‘f‘,‘r‘, 0, 0, // 0 4 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, // 1 5 1, 1,‘"‘, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, // 2 6 };
前48个字符中,值为0的是一些不常用的控制字符,所以这里标为0,unicode输出;值为1的为那些可显示非转义字符,输出时直接按其ASCII编码值输出即可;其他的是需要转义的字符,按照上面的转义字符的字节数组输出,
下面是ASCII编码图,朋友们可以参照着看一下:
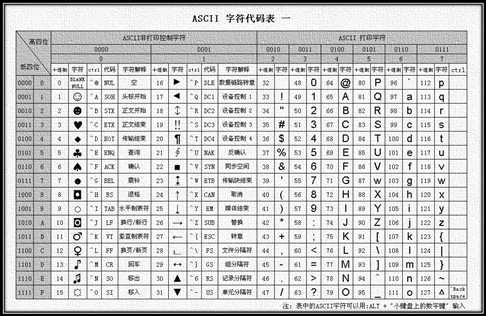
下面是Thrift内部数据类型对应的JSON输出字节数组标志,在write和read时,会按照其进行相应的转换,源码时,具体分析:
private static final byte[] NAME_BOOL = new byte[] {‘t‘, ‘f‘}; private static final byte[] NAME_BYTE = new byte[] {‘i‘,‘8‘}; private static final byte[] NAME_I16 = new byte[] {‘i‘,‘1‘,‘6‘}; private static final byte[] NAME_I32 = new byte[] {‘i‘,‘3‘,‘2‘}; private static final byte[] NAME_I64 = new byte[] {‘i‘,‘6‘,‘4‘}; private static final byte[] NAME_DOUBLE = new byte[] {‘d‘,‘b‘,‘l‘}; private static final byte[] NAME_STRUCT = new byte[] {‘r‘,‘e‘,‘c‘}; private static final byte[] NAME_STRING = new byte[] {‘s‘,‘t‘,‘r‘}; private static final byte[] NAME_MAP = new byte[] {‘m‘,‘a‘,‘p‘}; private static final byte[] NAME_LIST = new byte[] {‘l‘,‘s‘,‘t‘}; private static final byte[] NAME_SET = new byte[] {‘s‘,‘e‘,‘t‘};
基本重要数据成员介绍完毕,在具体分析读写前,再来介绍下写辅助方法和类,有助于后面读写的具体理解:
// 把char(‘0 - 9‘ & ‘ a - f‘)字符转变为相应的hex十六进制值。 private static final byte hexVal(byte ch) throws TException { if ((ch >= ‘0‘) && (ch <= ‘9‘)) { return (byte)((char)ch - ‘0‘); } else if ((ch >= ‘a‘) && (ch <= ‘f‘)) { return (byte)((char)ch - ‘a‘ + 10); } else { throw new TProtocolException(TProtocolException.INVALID_DATA, "Expected hex character"); } } // 上面的反过程,把hex十六进制值转变为相应的字符。 private static final byte hexChar(byte val) { val &= 0x0F; if (val < 10) { return (byte)((char)val + ‘0‘); } else { return (byte)((char)(val - 10) + ‘a‘); } }
辅助类,用于具体读写过程中写入,或读取JSON语法字符,该类为基类,no-op:
protected class JSONBaseContext { protected void write() throws TException {} protected void read() throws TException {} protected boolean escapeNum() { return false; } }
用于读取JSON数组的JSONBASEContext子类, 用于写入,读取元素item之间的JSON语法字符 ‘ ,‘:
protected class JSONListContext extends JSONBaseContext { private boolean first_ = true; //第一个元素之前不要添加,读取 ‘,‘; @Override protected void write() throws TException { if (first_) { first_ = false; } else { trans_.write(COMMA); } } @Override protected void read() throws TException { if (first_) { first_ = false; } else { readJSONSyntaxChar(COMMA); } } }
用于读取JSON 对象(Object)的JSONBASEContext子类, 用于写入,读取元素item之间的 ‘ ,‘ , 和key, value对之间的 ‘:‘ JSON语法字符:
protected class JSONPairContext extends JSONBaseContext { private boolean first_ = true; //添加,读取 ‘,‘字符的标志,第一个不需要加入和读取; private boolean colon_ = true; //添加,读取 ‘:‘字符的标志, @Override protected void write() throws TException { if (first_) { first_ = false; colon_ = true; } else { trans_.write(colon_ ? COLON : COMMA); colon_ = !colon_; } } @Override protected void read() throws TException { if (first_) { first_ = false; colon_ = true; } else { readJSONSyntaxChar(colon_ ? COLON : COMMA); colon_ = !colon_; } } @Override protected boolean escapeNum() { //由于JSON Object的key必须为string类型,所以这里用colon标志,同时标注是否需要写入,读取‘"‘字符; return colon_; } }
private Stack<JSONBaseContext> contextStack_ = new Stack<JSONBaseContext>(); //用于读取不同类型时,上下文上下切换,上面提及的两种上下文,读取和写入JSON Object,和JSON array,当递归解析和写入时,得随时切换
private JSONBaseContext context_ = new JSONBaseContext(); //当前读取,写入上下文。
// private void pushContext(JSONBaseContext c) { //吧方法参数的上下文设为当前上下文(比如当前真在解析JSON array,而array中出现一个JOSN object(map) item时,得切换到JSONPairContext来解析) contextStack_.push(context_); //当前上下文压入栈, context_ = c; } private void popContext() { context_ = contextStack_.pop(); //吧之前压入栈的上下文设为当前上下文(还是上面的例子,当JSON object解析完后,接着解析array别的item,所以还得之前压入栈的上下文) }
上面两个类都用到readJSONSyntaxChar(xxx)方法,我们再来看看:
protected void readJSONSyntaxChar(byte[] b) throws TException { byte ch = reader_.read(); //方法参数设定一个字节数组,当读取的字节不等于b[0]抛异常,要来验证读取的字节是否为指定的JSON语句字符的。 if (ch != b[0]) { throw new TProtocolException(TProtocolException.INVALID_DATA, "Unexpected character:" + (char)ch); } }
JOSN协议从传输层读取字节时都是一字节一字节的读取:
protected class LookaheadReader { private boolean hasData_; private byte[] data_ = new byte[1]; //检测当前容量为1的字节数组中是否有数据,没有从底层传输层读取一字节,该方法是消耗型的 protected byte read() throws TException { if (hasData_) { hasData_ = false; } else { trans_.readAll(data_, 0, 1); } return data_[0]; } // 同上,不同的是该方法不发生消耗 protected byte peek() throws TException { if (!hasData_) { trans_.readAll(data_, 0, 1); } hasData_ = true; return data_[0]; } }
别的参数成员:
// 上面已经介绍,当前解析的底层读取器,一个字节一个字节的读取 private LookaheadReader reader_ = new LookaheadReader(); // 是否写入TField的(即方法参数的参数名)的标志,不写入参数名,就要参数标号来代替 private boolean fieldNamesAsString_ = false;
OK!进入正文,首先看看JSON协议怎么写数据的,从string开始,JSON String分Unicode和转义字符两种:
private void writeJSONString(byte[] b) throws TException { context_.write(); // JSONBaseContext 空操作 trans_.write(QUOTE); //写入‘"‘字符 int len = b.length; for (int i = 0; i < len; i++) { if ((b[i] & 0x00FF) >= 0x30) { //对照上面的ASCII表, >= 0x30即 >= 48(上面JSON_CHAR_TABLE表述的为0 - 47,48以上的用的着的转义字符就‘\‘) if (b[i] == BACKSLASH[0]) { //如果写入的字符为 ‘\‘,需要转义。 trans_.write(BACKSLASH);// trans_.write(BACKSLASH); // 写两次‘\‘ } else { trans_.write(b, i, 1);// 0x30上除‘\‘,之外的字符直接写入 } } else { // b[i] < 48的情况,即上面设计的那张JSON_CHAR_TABLE倍 tmpbuf_[0] = JSON_CHAR_TABLE[b[i]]; if (tmpbuf_[0] == 1) { //查表后,表对应的值为1的情况:非转义,即可直接写入。 trans_.write(b, i, 1); } else if (tmpbuf_[0] > 1) { //即为那些转义字符 ‘"‘ , ‘/‘ , ‘b‘ , ‘t‘ , ‘r‘ , ‘n‘; trans_.write(BACKSLASH); // 写之前先追加‘\‘; trans_.write(tmpbuf_, 0, 1); } else { // 0 trans_.write(ESCSEQ);//unicode \u00xx形式写入。 tmpbuf_[0] = hexChar((byte)(b[i] >> 4)); tmpbuf_[1] = hexChar(b[i]); trans_.write(tmpbuf_, 0, 2); } } } trans_.write(QUOTE); // 最后再加上‘"‘; }
JSON 整形输出:
private void writeJSONInteger(long num) throws TException { //虽然这里取long的字符串表现形式,但是输出是按JSON 整数表示输出(没加 ‘"‘); context_.write(); //no -op String str = Long.toString(num); //string表示形式 boolean escapeNum = context_.escapeNum(); //false if (escapeNum) { trans_.write(QUOTE); } try { byte[] buf = str.getBytes("UTF-8"); //UTF-8字符编码得到字节数组 trans_.write(buf); } catch (UnsupportedEncodingException uex) { throw new TException("JVM DOES NOT SUPPORT UTF-8"); } if (escapeNum) { trans_.write(QUOTE); } }
JSON 浮点数写入,JSON浮点数有几点特殊,JSON几种特殊的浮点数用字符串表示和传输:
a. NaN表示不是数字值;
b. Infinity表示正无穷大;
c. –Infinity表示负无穷大。
private void writeJSONDouble(double num) throws TException { context_.write(); String str = Double.toString(num); boolean special = false; switch (str.charAt(0)) { case ‘N‘: // NaN case ‘I‘: // Infinity special = true; break; case ‘-‘: if (str.charAt(1) == ‘I‘) { // -Infinity special = true; } break; default: break; } boolean escapeNum = special || context_.escapeNum(); //三种特殊情况,special标志位true,此时escapeNum为true, 即用JSON字符串形式表示和输出,否则还是以JSON Number类型输出 if (escapeNum) { trans_.write(QUOTE); // ‘"‘ } try { byte[] b = str.getBytes("UTF-8"); trans_.write(b, 0, b.length); } catch (UnsupportedEncodingException uex) { throw new TException("JVM DOES NOT SUPPORT UTF-8"); } if (escapeNum) { trans_.write(QUOTE); // ‘"‘ } }
Thrift的二进制值并编码为base64编码然后作为JSON的字符串:
public void writeBinary(ByteBuffer bin) throws TException {
writeJSONBase64(bin.array(), bin.position() + bin.arrayOffset(), bin.limit() - bin.position() - bin.arrayOffset());
}
private void writeJSONBase64(byte[] b, int offset, int length) throws TException { context_.write(); trans_.write(QUOTE); int len = length; int off = offset; while (len >= 3) { // Encode 3 bytes at a time TBase64Utils.encode(b, off, 3, tmpbuf_, 0); trans_.write(tmpbuf_, 0, 4); off += 3; len -= 3; } if (len > 0) { // Encode remainder TBase64Utils.encode(b, off, len, tmpbuf_, 0); trans_.write(tmpbuf_, 0, len + 1); } trans_.write(QUOTE); }
Thrift的bool类型写入方式是按JSON 整形写入,false = 0 , ture = 1:
public void writeBool(boolean b) throws TException { writeJSONInteger(b ? (long)1 : (long)0); }
Thrift其他整型和字节写入方式一并贴出,转换为long类型,都是按JSON整形写入:
@Override public void writeByte(byte b) throws TException { writeJSONInteger((long)b); } @Override public void writeI16(short i16) throws TException { writeJSONInteger((long)i16); } @Override public void writeI32(int i32) throws TException { writeJSONInteger((long)i32); } @Override public void writeI64(long i64) throws TException { writeJSONInteger(i64); }
Thrift的double类型,按照JSON浮点数写入:
public void writeDouble(double dub) throws TException { writeJSONDouble(dub); }
Thrift的string类型按照JSON字符串写入,JSON在处理时,会对一些字符进行转义:
public void writeString(String str) throws TException { try { byte[] b = str.getBytes("UTF-8"); //string utf-8编码之后得到字节数组 writeJSONString(b); } catch (UnsupportedEncodingException uex) { throw new TException("JVM DOES NOT SUPPORT UTF-8"); } }
再来看看Thrift 的set , list写入方法:
@Override public void writeListBegin(TList list) throws TException { writeJSONArrayStart(); writeJSONString(getTypeNameForTypeID(list.elemType)); writeJSONInteger(list.size); } @Override public void writeListEnd() throws TException { writeJSONArrayEnd(); } @Override public void writeSetBegin(TSet set) throws TException { writeJSONArrayStart(); writeJSONString(getTypeNameForTypeID(set.elemType)); writeJSONInteger(set.size); } @Override public void writeSetEnd() throws TException { writeJSONArrayEnd(); }
Thrift的lists和sets被表示为JSON的array(数组),其中数组的第一个元素表示Thrift元素的数据类型,数组第二值表示后面Thrift元素的个数。接着后面就是所有的元素:
private void writeJSONArrayStart() throws TException { context_.write(); trans_.write(LBRACKET); //写入JSON array语法字符 ‘[’ pushContext(new JSONListContext()); //设置当前处理解析上下文, } private void writeJSONArrayEnd() throws TException { popContext(); //回复之前的处理解析上下文 trans_.write(RBRACKET); //补上JSON array语句结束字符‘]‘ }
数组的第一个元素为数据类型,按JSON字符串写入,即本篇开头贴出的代码,getTypeNameForTypeID(set.elemType) 用于Thrift数据类型和JSON为该类型表示的字符串的字节数组之间的转换:
private static final byte[] getTypeNameForTypeID(byte typeID) throws TException { switch (typeID) { case TType.BOOL: return NAME_BOOL; case TType.BYTE: return NAME_BYTE; case TType.I16: return NAME_I16; case TType.I32: return NAME_I32; case TType.I64: return NAME_I64; case TType.DOUBLE: return NAME_DOUBLE; case TType.STRING: return NAME_STRING; case TType.STRUCT: return NAME_STRUCT; case TType.MAP: return NAME_MAP; case TType.SET: return NAME_SET; case TType.LIST: return NAME_LIST; default: throw new TProtocolException(TProtocolException.NOT_IMPLEMENTED, "Unrecognized type"); } }
数组的第二个元素为整个list , set的长度,按JSON整形写入,然后写入各个容器成员。
Thrift map数据类型写入方式:
public void writeMapBegin(TMap map) throws TException { writeJSONArrayStart(); // ‘[‘ ,设置当前处理解析上下文 writeJSONString(getTypeNameForTypeID(map.keyType)); //数组的第一个元素为key类型 =>JSON的类型字符串表示字节数组 writeJSONString(getTypeNameForTypeID(map.valueType)); // 数组的第二个元素 为 value类型 writeJSONInteger(map.size); //数组的第三个元素,map的长度 writeJSONObjectStart(); //map的key,value对按 Json object输出。 } @Override public void writeMapEnd() throws TException { writeJSONObjectEnd(); //回复当前上下文 ‘}’ writeJSONArrayEnd(); //回复当前上下文 ‘]‘ }
private void writeJSONObjectStart() throws TException { context_.write(); trans_.write(LBRACE); pushContext(new JSONPairContext()); } private void writeJSONObjectEnd() throws TException { popContext(); trans_.write(RBRACE); }
Thrift的maps被表示为JSON的array,其中前两个值分别表示键和值的类型,跟着就是键值对的个数,接着就是包含具体键值对的JSON对象了。注意了JSON的键只能是字符串,这就是要求Thrift的maps类型的键必须是数字和字符串的,并且数字和字符串做转换,就是下面提及的字符串。
有效的类型标识是:"tf"代表 bool,"i8" 表示 byte,"i16"表示16位整数,"i32"表示32位整数,"i64"表示64位整数,"dbl"表示双精度浮点型,"str" 表示字符串(包括二进制),"rec"表示结构体 ("records"),"map"表示 map,"lst" 表示 list, "set" 表示set。
Thrift的messages(消息)被表示为JSON的array,前四个元素分别代表协议版本、消息名称、消息类型和序列ID:
public void writeMessageBegin(TMessage message) throws TException { writeJSONArrayStart(); writeJSONInteger(VERSION); try { byte[] b = message.name.getBytes("UTF-8"); writeJSONString(b); } catch (UnsupportedEncodingException uex) { throw new TException("JVM DOES NOT SUPPORT UTF-8"); } writeJSONInteger(message.type); writeJSONInteger(message.seqid); }
然后呢?该写Thrift的tstructs了(具体的RPC方法参数封装),struct是按照JSON object写入:
public void writeStructBegin(TStruct struct) throws TException { writeJSONObjectStart(); }
Thrift的TField(具体的每个参数)的写入:
public void writeFieldBegin(TField field) throws TException { if (fieldNamesAsString_) { writeString(field.name); //参数名 } else { writeJSONInteger(field.id); //或者参数id } writeJSONObjectStart(); // ‘{‘ writeJSONString(getTypeNameForTypeID(field.type)); Thrift数据类型的字符串表示 }
即Thrift的消息类型形如:
[ 1 (version) , "messageName" , type (call, oneway, reply, exception (byte)) , seq id , { "argument name" : { " argument type" : value }, "argument name" : { " argument type" : value}, .................................................................... } ]
Thrift之TProtocol系列TJSONProtocol解析
标签:
原文地址:http://www.cnblogs.com/onlysun/p/4611566.html