标签:
11.2对应分析
在很多情况下,我们所关心的不仅仅是行或列变量本身,而是行变量和列变量的相互关系,这就是因子分析等方法无法解释的了。1970年法国统计学家J.P.Benzenci提出对应分析,也称关联分析、R-Q型因子分析,其是一种多元相依变量统计分析技术。它通过分析由定性变量构成的交互汇总表,来揭示同一变量各类别之间的差异,以及不同变量各类别之间的对应关系,这是一种非常好的分析调查问卷的手段。
对应分析是一种视觉化的数据分析方法,其基木思想是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来,优点在于能够将几组看不出任何联系的数据,通过视觉上可以接受的定位图展现出来,使用起来直观、简单、方便,因此广泛应用于市场细分、产品定位、地质研究以及计算机工程等领域。
11.2.1理论基础
对应分析是寻求样木(行)与指标(列)之间联系的低维图示法,其关键是利用一种数据变换方法,使含有n个样本观测值和m个变量的原始数据矩阵x变成另一个矩阵z, z是一个过渡知阵,在接下来的计算中使用。通过z将样本和变量结合起来。
11.2.2 R语言实现
R中的程序包MASS提供了两个函数,corresp()用于做简单一的对应分析,mca()用于计算多重对应分析,通常使用前者,其调用格式为corresp(x,nf=1,……)
x是数据矩阵:nf表示因子分析中计算因子的个数,通常取2.
【例】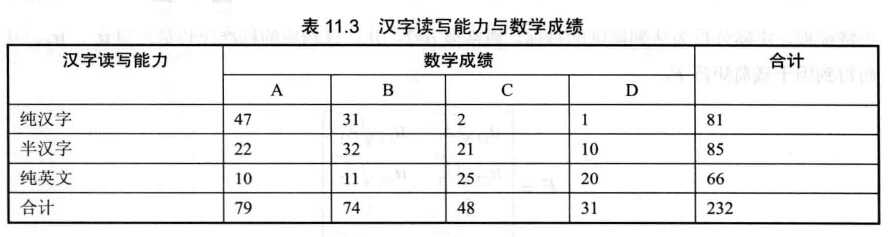
> ch=data.frame(A=c(47,22,10),B=c(31,32,11),C=c(2,21,25),D=c(1,10,20))> rownames(ch)=c("Pure-Chinese","Semi-Chinese","Pure-English")
> library(MASS)
> ch.ca=corresp(ch,nf=2)
> options(digits=4)
> ch.ca
First canonical correlation(s): 0.5521 0.1409
Row scores:
[,1] [,2]
Pure-Chinese 1.2069 0.6383
Semi-Chinese -0.1368 -1.3079
Pure-English -1.3051 0.9010
Column scores:
[,1] [,2]
A 0.9325 0.9196
B 0.4573 -1.1655
C -1.2486 -0.5417
D -1.5346 1.2773
分析结果给出了两个因子对应行变量、列变量的载荷系数。对应分析是一种可视化的多元统计方法,它主要是通过图形分析来得出结论,在R中我们使用函数biplot()可以提取因子分析的散点图,以直观地展示样本和变量各个水平之间的关系。
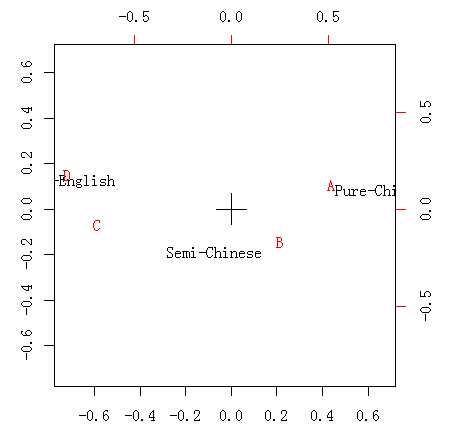

分析图时主要看两种散点的横坐标之间的距离,纵坐标的距离对于分析意义不大。散点“纯汉字”和数学成绩A最接近,说明数学好的人可以自如地进行纯汉字读写;散点“纯英文”与数学成绩D非常接近,说明数学差的人不会汉字只会英文;而“半汉字”介于数学成绩B和C之间,说明会部分汉字的学生数学成绩一般。
MASS程序包的函数功能还是有限的,于是一些R软件使用者开发了专门用来处理对应分析的程序包,如ca包,该包专门用于计算并可视化简单对应分析、多重及联合对应分析。
对应分析广泛地应用于市场研究中,常常结合问卷调查方法,在产品定位、市场细分方面是一项非常重要的统计技术。在企业营销中,经常需要明确产品定位:什么样的消费者在使用本企业生产的产品?在不同类型的消费者心目中,哪一个品牌更受欢迎?当数据量较小时,可以使用列联表来分析不同类型的消费者在选择品牌上的差异。但是列联表存在一个问题:当变量很多且每个变量又有多个类别时,数据量很大,很难直观地发现变量间的内在联系,这时对应分析就是一种有效的解决方案。
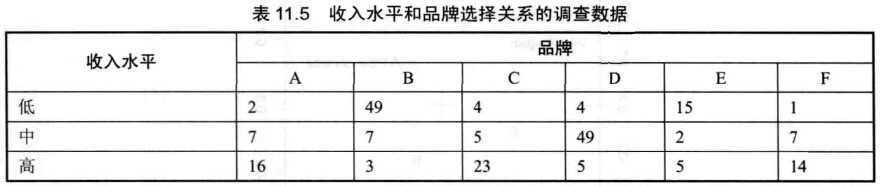
> brand=data.frame(low=c(2,49,4,4,15,1),medium=c(7,7,5,49,2,7),high=c(16,3,23,5,5,14))
> rownames(brand)=c("A","B","C","D","E","F")
> library(ca)
> options(digits=3)
> brand.ca=ca(brand)
> brand.ca
Principal inertias (eigenvalues):
1 2
Value 0.530966 0.343042
Percentage 60.75% 39.25%
Rows:
A B C D E F
Mass 0.1147 0.271 0.147 0.266 0.101 0.1009
ChiDist 0.7704 1.026 0.906 1.029 0.738 0.7939
Inertia 0.0681 0.285 0.120 0.282 0.055 0.0636
Dim. 1 -0.7267 1.399 -0.581 -0.850 0.988 -0.8296
Dim. 2 0.9553 -0.200 1.368 -1.403 0.281 0.8786
Columns:
low medium high
Mass 0.3440 0.353 0.303
ChiDist 1.0058 0.861 0.934
Inertia 0.3480 0.262 0.264
Dim. 1 1.3792 -0.778 -0.659
Dim. 2 -0.0663 -1.107 1.367
使用函数ca()得到的分析结果包含了更多的信息:ChiDist是列联表的卡方检验结果;Inertia是惯量,也就是我们所说的特征根;Dim. 1和Dim. 2是提取的两个因子对行、列变量的因子载荷。可通过names()查看因子分析输出的对象列表。
> names(brand.ca)
[1] "sv" "nd" "rownames" "rowmass"
[5] "rowdist" "rowinertia" "rowcoord" "rowsup"
[9] "colnames" "colmass" "coldist" "colinertia"
[13] "colcoord" "colsup" "call"
例如,如下语句可以得到两个因子对应的行的标准坐标:
> brand.ca$rowcoord
Dim1 Dim2
A -0.727 0.955
B 1.399 -0.200
C -0.581 1.368
D -0.850 -1.403
E 0.988 0.281
F -0.830 0.879
用plot()函数绘制因子分析的散点图
plot(brand.ca)
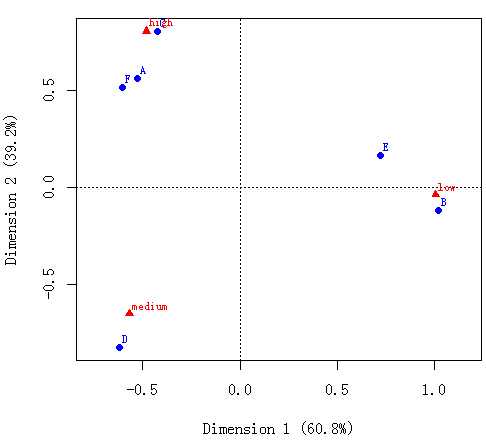
对应分析散点图是由品牌类别和收入类别的因子坐标值组成,从中可以看出,低收入人群倾向于选择品牌B和E,中收入水平倾向于选择品牌D,而高收入水平倾向于品牌A. C和F,这样企业就完成了初步的市场定位。
标签:
原文地址:http://www.cnblogs.com/jpld/p/4613109.html