标签:
最近做了一个项目,把整个数据仓库平台下所有的表和索引都改成页级别的数据压缩。昨天发现测试环境下的某个workload跑得比平时慢。最后我们定位了到这个workload做的事情中可能造成性能下降的地方,其实也就是定位到某条SQL语句。这条语句是一条MERGE语句。我们通过复制出另外两张表(MERGE语句中的target表)。这样我们就有三张表:一张是PAGE DATA_COMPRESSION,一张是ROW DATA_COMPRESSION,最后一张是NONE DATA_COMPRESSION。此举是为了得出整个性能的统计。
表的数据量是两千三百多万,聚集索引加四条非聚集索引。服务器有58个处理核心,内存256G。
| No. | NonDCP | DCP(PAGE) | DCP(ROW) | ||||||
| Duration | CPU Time | Elapse Time | Duration | CPU Time | Elapse Time | Duration | CPU Time | Elapse Time | |
| (mm:ss) | (ms) | (ms) | (mm:ss) | (ms) | (ms) | (mm:ss) | (ms) | (ms) | |
| 1 | 2:03 | 176,442 | 123,660 | 4:18 | 1,122,304 | 257,814 | 5:03 | 1,067,797 | 303,248 |
| 2 | 1:05 | 217,218 | 65,448 | 5:56 | 1,093,818 | 355,671 | 4:45 | 1,056,553 | 285,461 |
在大家都是影响448211行记录的情况
结果是没有压缩的表只花了1-2分钟完成整个过程,而PAGE和ROW压缩花了4-6分钟完成整个任务。差异之大让我惊讶。毕竟数据相同。那么去找出root cause,我需要借用两条查询来收集运行过程之中的数据,以及尽可能得出一个实际的执行计划来分析是否会因为压缩而造成执行计划的巨大变化。
--把运行语句的线程号带入in字句 SELECT status as stat,* FROM sys.sysprocesses where spid in (314,563,1090) --调用sys.dm_os_waiting_tasks来告诉我们究竟运行过程在等待什么资源 SELECT dm_ws.wait_duration_ms, dm_ws.wait_type, dm_es.status, dm_ws.session_ID, dm_es.cpu_time, dm_es.memory_usage, dm_es.logical_reads, dm_es.total_elapsed_time, dm_es.program_name, DB_NAME(dm_r.database_id) DatabaseName, -- Optional columns dm_ws.blocking_session_id, dm_r.wait_resource, dm_es.login_name, dm_r.command, dm_r.last_wait_type FROM sys.dm_os_waiting_tasks dm_ws INNER JOIN sys.dm_exec_requests dm_r ON dm_ws.session_id = dm_r.session_id INNER JOIN sys.dm_exec_sessions dm_es ON dm_es.session_id = dm_r.session_id WHERE dm_es.is_user_process = 1 and dm_ws.session_id in (314,563,1090) ORDER BY wait_duration_ms DESC
整个过程我所看到的就是大部分的线程等待状态类型是CXPACKET,其次是SOS_SCHEDULER_YIELD,再则是PAGEIOLATCH_SH。并行线程最多的时候是35-40条线程。
执行计划上看大家都差不多,图形执行计划显示97%的开销花在了Clustered Index Merge操作符上

那这样看似乎执行计划上给不了太多有用的信息或者问题本身并不出在执行计划上。
我把思路转向了前面收集的数据,设想某种资源的等待。我怀疑的重点在CPU资源上,因为几张表的区别在于是否压缩了数据页。而压缩技术实际上可以理解为用CPU消耗换取IO和内存的压力。
从sys.sysprocesses系统视图上看,页压缩的表对应的MERGE语句开始的时候开启的43条线程在跑,其中可以看到有接近10条线程处于runnable而且上一个等待状态是SOS_SCHEDULER_YIELD,那么这种情况下可能很多线程就处于CXPACKET的等待状态了。我查了一下服务器的MAX DOP是8。假设现在整个执行计划某一步操作SQL SERVER给了它8条线程,那么如果当中某条线程是前面处于runnable的其中一条,也就意味着剩下的7条线程可能有些都是在等待它完成整个任务。因为它上一个等待状态是SOS_SCHEDULER_YIELD,说明它刚把原本分配给它的scheduler让了出来给队列中靠前且处于runnable状态的SQL SERVER thread/worker。这个时候它重新回到了等待队列里面SUSPENDED状态,等待被移到runnable队列中,这短时间内所有其他的并行线程如果它们都完成它们的事情就必须耐心等待了。这点可以很明显地从sys.sysprocesses系统视图的waittime列看出来。
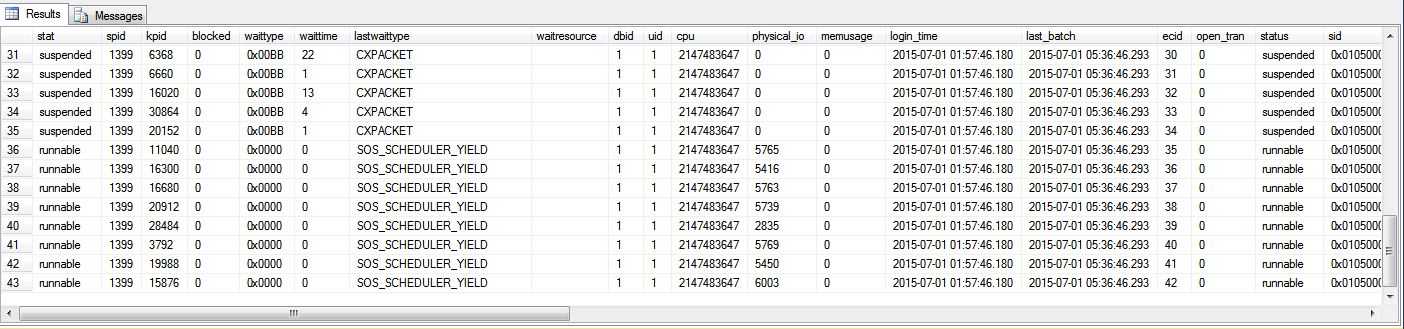
那从另外一张视图sys.dm_os_waiting_tasks中可以看出,其实很多线程都出在CXPACKET的等待状态。
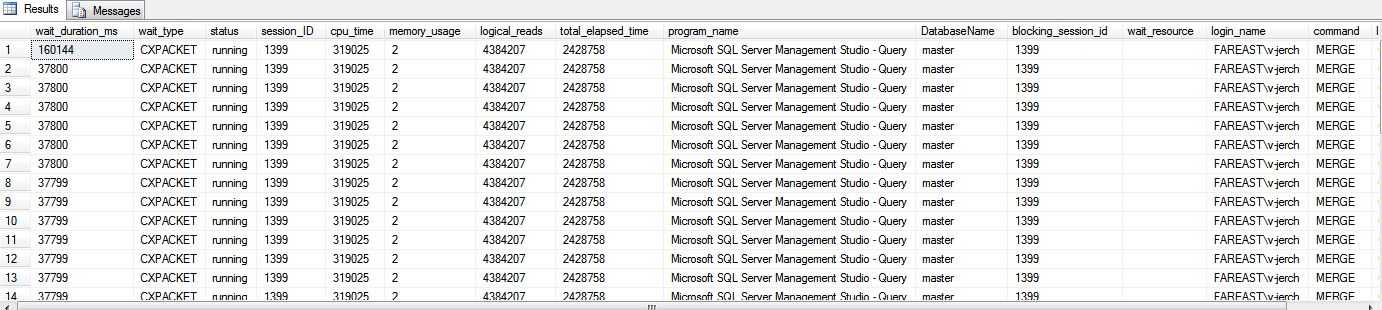
CXPACKET本身不是问题。不过像这个例子,我还是心生了这样的想法,回不回是MAX DOP设置低了呢?
那么我通过前几天自己写的一篇文章的办法去查找当前SQL SERVER的等待时间和类型的统计信息:http://www.cnblogs.com/jenrrychen/p/4610231.html
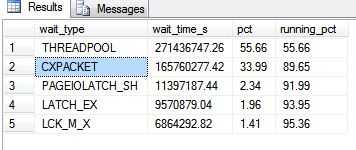
结果发现CXPACKET和SOS_SCHEDULER_YIELD排在了2、3位,当然因为这个环境是测试环境,可能数据不是那么的可靠。那么我去到Pre-Production环境下查了下。它们俩排在了前两位。CXPACKET占了70%的等待时间。
测试环境下的结果
Pre-Production环境下的结果
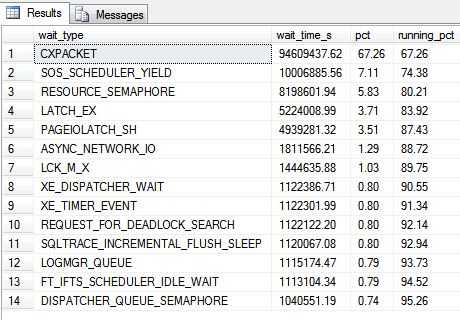
那么我第一想法就是如果我为这条MERGE语句加上OPTION(MAXDOP=12),会有怎样的变化呢?
结果不出我所料,无论是ROW COMPRESSION还是PAGE COMPRESSION,运行时间都从原来的4-6分钟缩短到了1分30秒左右。
这个数值是经过多次测试后得出来觉得比较合适的。测试过12、16、24、32,其实性能并没有因为说并行线程数越大而越好。比较稳定。
因此决定通过测试服务器级别的MAXDOP从8增加到12看整个Dataware House平台的性能变化,观察workload的完成情况来决定是否应用到PRODUCTION。
参考:
https://support.microsoft.com/en-us/kb/2806535
https://technet.microsoft.com/en-us/library/cc879317(v=sql.105).aspx
标签:
原文地址:http://www.cnblogs.com/jenrrychen/p/4614482.html