标签:
首先,新建一个winform项目,我在想,如果想要实现打开网页功能的话,应该会有一个控件什么之类的吧?查了工具栏,真的有一个名叫 WebBrowser的家伙,应该就是这货没错了。在网上查了它的资料更加坚定了我的判断,二话不说,拖进Form里。接着,就是要显示一个网页了,要怎 么实现呢?继续查看WebBrowser都有啥属性和方法:
|
方法
|
说明
|
| GoBack | 相当于IE的“后退”按钮,使你在当前历史列表中后退一项 |
| GoForward | 相当于IE的“前进”按钮,使你在当前历史列表中前进一项 |
| GoHome | 相当于IE的“主页”按钮,连接用户默认的主页 |
| GoSearch | 相当于IE的“搜索”按钮,连接用户默认的搜索页面 |
| Navigate | 连接到指定的URL |
| Refresh | 刷新当前页面 |
| Refresh2 | 同上,只是可以指定刷新级别,所指定的刷新级别的值来自RefreshConstants枚举表, 该表定义在ExDisp.h中,可以指定的不同值如下: REFRESH_NORMAL 执行简单的刷新,不将HTTP pragma: no-cache头发送给服务器 REFRESH_IFEXPIRED 只有在网页过期后才进行简单的刷新 REFRESH_CONTINUE 仅作内部使用。在MSDN里写着DO NOT USE! 请勿使用 REFRESH_COMPLETELY 将包含pragma: no-cache头的请求发送到服务器 |
| Stop | 相当于IE的“停止”按钮,停止当前页面及其内容的载入 |
|
属性
|
说明
|
| Application | 如果该对象有效,则返回掌管WebBrowser控件的应用程序实现的自动化对象(IDispatch)。如果在宿主对象中自动化对象无效,这个程序将返回WebBrowser 控件的自动化对象 |
| Parent | 返回WebBrowser控件的父自动化对象,通常是一个容器,例如是宿主或IE窗口 |
| Container | 返回WebBrowser控件容器的自动化对象。通常该值与Parent属性返回的值相同 |
| Document | 为活动的文档返回自动化对象。如果HTML当前正被显示在WebBrowser中,则 Document属性提供对DHTML Object Model的访问途径 |
| TopLevelContainer | 返回一个Boolean值,表明IE是否是WebBrowser控件顶层容器,是就返回true |
| Type | 返回已被WebBrowser控件加载的对象的类型。例如:如果加载.doc文件,就会返 回Microsoft Word Document |
| Left | 返回或设置WebBrowser控件窗口的内部左边与容器窗口左边的距离 |
| Top | 返回或设置WebBrowser控件窗口的内部左边与容器窗口顶边的距离 |
| Width | 返回或设置WebBrowser窗口的宽度,以像素为单位 |
| Height | 返回或设置WebBrowser窗口的高度,以像素为单位 |
| LocationName | 返回一个字符串,该字符串包含着WebBrowser当前显示的资源的名称,如果资源 是网页就是网页的标题;如果是文件或文件夹,就是文件或文件夹的名称 |
| LocationURL | 返回WebBrowser当前正在显示的资源的URL |
| Busy | 返回一个Boolean值,说明WebBrowser当前是否正在加载URL,如果返回true 就可以使用stop方法来撤销正在执行的访问操作 |
| 事件 | 说明 |
|---|---|
| BeforeNavigate2 | 导航发生前激发,刷新时不激发 |
| CommandStateChange | 当命令的激活状态改变时激发。它表明何时激活或关闭Back和Forward 菜单项或按钮 |
| DocumentComplete | 当整个文档完成是激发,刷新页面不激发 |
| DownloadBegin | 当某项下载操作已经开始后激发,刷新也可激发此事件 |
| DownloadComplete | 当某项下载操作已经完成后激发,刷新也可激发此事件 |
| NavigateComplete2 | 导航完成后激发,刷新时不激发 |
| NewWindow2 | 在创建新窗口以前激发 |
| OnFullScreen | 当FullScreen属性改变时激发。该事件采用VARIENT_BOOL的一个输 入参数来指示IE是全屏显示方式(VARIENT_TRUE)还是普通显示方式(VARIENT_FALSE) |
| OnMenuBar | 改变MenuBar的属性时激发,标示参数是VARIENT_BOOL类型的。 VARIANT_TRUE是可见,VARIANT_ FALSE是隐藏 |
| OnQuit | 无论是用户关闭浏览器还是开发者调用Quit方法,当IE退出时就会激发 |
| OnStatusBar | 与OnMenuBar调用方法相同,标示状态栏是否可见。 |
| OnToolBar | 调用方法同上,标示工具栏是否可见。 |
| OnVisible | 控制窗口的可见或隐藏,也使用一个VARIENT_BOOL类型的参数 |
| StatusTextChange | 如果要改变状态栏中的文字,这个事件就会被激发,但它并不理会程序是否有状态栏 |
| TitleChange |
Title有效或改变时激发 |
看了以上信息后,Navigate这个方法最靠谱,所以在Form1_Load中加入了一句代码:
webBrowser1.Navigate("http://www.baidu.com/");
运行后百度的页面出来了,搞定!原来如此简单!
这么一句就搞定了,我开始不满足于现状,我想查看一下生成baidu的网页源代码,有一个属性是:DocumentText,我想应该是这个,于是我在Form1_Load加了这么一句:
this.textBox1.Text = webBrowser1.DocumentText;
运行后,发现textbox里啥都没显示,调试发现webBrowser1.DocumentText居然是空值,难道是我 DocumentText不是显示页面内容的属性?不对,我再加入webBrowser1.Document来调试,发现居然是个null值,一定是哪里 弄错了!
我仔细检查了一下,原来是我看事件不仔细,webBrowser1.DocumentText这个必须放在webBrowser1_DocumentCompleted事件中,等页面加载完成后,才能获取到网页的值,再试一下,果然成功了!
private void webBrowser1_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
this.textBox1.Text = webBrowser1.DocumentText;
}
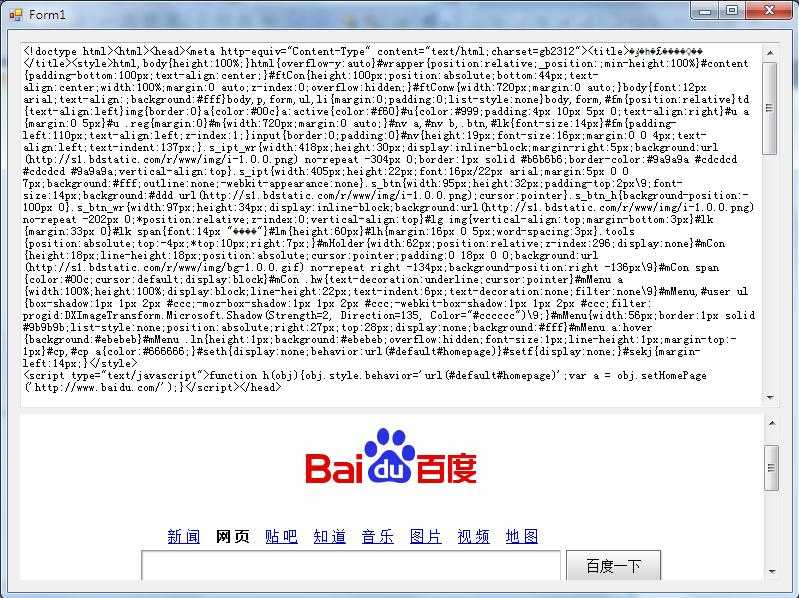
不过……为什么会有乱码啊?!
不行,我要把乱码去掉,默认是utf-8的页面,我只要把它转换成gb2312即可,所以就不能直接webBrowser1.DocumentText,我打算采用StreamReader来转换好一些:
StreamReader getReader = new StreamReader(this.webBrowser1.DocumentStream, Encoding.GetEncoding("gb2312"));
this.textBox1.Text = getReader.ReadToEnd();
OK,两句就搞定!注意哦,我这里用的是this.webBrowser1.DocumentStream
我又突发奇想,如果我只想要获取网页中的图片地址该怎么办咧?大概的思路就是从生成的网页源代码里找到img标签,并从src里取出来呗,于是有了以下代码:

StreamReader getReader = new StreamReader(this.webBrowser1.DocumentStream, Encoding.GetEncoding("gb2312"));
ArrayList list = new ArrayList();
string strRegex = "<img (.|\n)+?>";
Regex regex = new Regex(strRegex, RegexOptions.IgnoreCase);
MatchCollection match = regex.Matches(getReader.ReadToEnd());
int startp, endp;
for (int i = 0; i < match.Count; i++)
{
bool flag = false;
string Img = match[i].ToString();
startp = Img.ToLower().IndexOf("src=\"");
if (startp != -1)
{
startp = startp + 5;
endp = Img.ToLower().IndexOf("\"", startp + 1);
Img = Img.Substring(startp, endp - startp);
foreach (string str in list)
{
if (Img == "str" || Img == "/" || Img == "")
{
flag = true;
break;
}
}
if (!flag)
{
this.textBox1.Text += Img.ToString() + "\r\n";
}
}
}
输出以下结果:
http://www.baidu.com/img/shouye_b5486898c692066bd2cbaeda86d74448.gif http://www.baidu.com/cache/global/img/gs.gif
虽然是成功取出了图片地址,但是感觉总是写这么多代码,有点不妥,这样一种取图片的功能,我想应该是很多人都会有这种需求,应该有啥控件或插件之类的吧?再网上搜了一下,果然让我找到了一个比较好用的——HtmlAgilityPack
把HtmlAgilityPack.dll引入项目后,只要编写如下代码就能实现如上的功能:
string strImg = "";
HtmlAgilityPack.HtmlDocument doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml(getReader.ReadToEnd());
foreach (var img in doc.DocumentNode.SelectNodes("//img"))
{
strImg += img.Attributes["src"].Value.ToString() + "\r\n";
} this.textBox1.Text = strImg;
太强大了,我想HtmlAgilityPack这货的能力应该不仅仅如此,比如还可以用它来去脚本,去样式,和去注释等:
foreach (var script in doc.DocumentNode.Descendants("script").ToArray())
{
script.Remove();
}
foreach (var style in doc.DocumentNode.Descendants("style").ToArray())
{
style.Remove();
}
foreach (var comment in doc.DocumentNode.SelectNodes("//comment()").ToArray())
{
comment.Remove();
}
就是如此简单,写更少的代码,做更多的事!
标签:
原文地址:http://www.cnblogs.com/275147378abc/p/4617295.html