标签:
转载自http://blog.csdn.net/kobejayandy/article/details/8775255
读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
为什么要分库、分表、读写分?
单表的数据量限制,当单表数据量到一定条数之后数据库性能会显著下降。数据多了之后,对数据库的读、写就会很多。分库减少单台数据库的压力。接触过几个分库分表的系统,都是通过主键进行散列分裤分表的。这类数据比较特殊,主键就是唯一的获取该条信息的主要途径。比如:京东的订单、财付通的交易记录等。。。该类数据的用法,就是通过订单号、交易号来查询该笔订单、交易。
还有一类数据,比如用户信息,每个用户都有系统内部的一个userid,与userid对应的还有用户看到的登录名。那么如果分库分表的时候单纯通过userid进行散列分库,那么根据登录名来获取用户的信息,就无法知道该用户处于哪个数据库中。
或许有朋友会说,我们可以维护一个email----userid的映射关系,根据email先查询到userid,在根据userid的分库分表规则到对应库的对应表来获取用户的记录信息。这么做是可以的,但是这个映射关系的条数本身也是个瓶颈,原则上是没有减少单表内数据的条数,算是一个单点。并且要维护这个映射关系和用户信息的一致性(修改登录名、多登录名等其他特殊需求),最大一个原因,其实用户信息是一个读大于写的库,web2.0都是以用户为中心,所有信息都和用户信息相关联,所以对用户信息拆分还是有一定局限性的。
对于这类读大于写并且数据量增加不是很明显的数据库,推荐采用读写分离+缓存的模式,试想一下一个用户注册、修改用户信息、记录用户登录时间、记录用户登录IP、修改登录密码,这些是写操作。但是以上这些操作次数都是很小的,所以整个数据库的写压力是很小的。唯一一个比较大的就是记录用户登录时间、记录用户登录IP这类信息,只要把这些经常变动的信息排除在外,那么写操作可以忽略不计。所以读写分离首要解决的就是经常变化的数据的拆分,比如:用户登录时间、记录用户登录IP。这类信息可以单独独立出来,记录在持久化类的缓存中(可靠性要求并不高,登陆时间、IP丢了就丢了,下次来了就又来了)
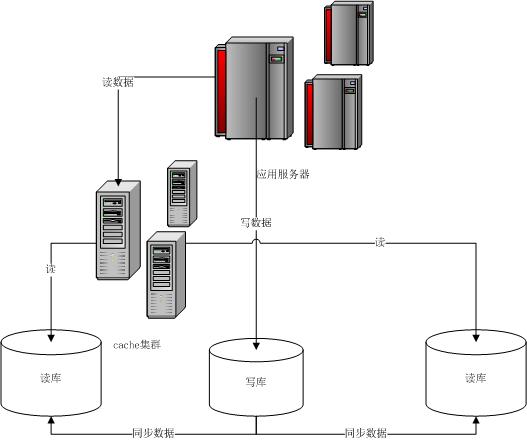
以oracle为例,主库负责写数据、读数据。读库仅负责读数据。每次有写库操作,同步更新cache,每次读取先读cache在读DB。写库就一个,读库可以有多个,采用dataguard来负责主库和多个读库的数据同步。
标签:
原文地址:http://www.cnblogs.com/scott19820130/p/4617498.html