标签:
数据结构是相互之间存在一种或多种特定关系的数据元素的集合
数据结构事实上就是一门研究非数值计算的程序设计问题的操作对象,以及它们之间的关系和操作等相关问题的学科。
数据是描述客观事件的符号,是计算机中可以操作的对象,是能被计算机识别,并输入能计算机处理的符号集合,也就是说数据必须具备两个前提:
数据元素是组成数据的、有一定意义的基本单位,在计算机中通常作为整体处理,也被称为记录
数据项:一个数据元素可以由若干个数据项组成
数据项是数据不可分割的最小单位
数据对象:是性质相同的数据元素的集合,是数据的子集

不同数据元素之间不是独立的,而是存在特定的关系,我们将这些关系称为结构
数据结构:是相互之间存在一种或多种特定关系的数据元素的集合
逻辑结构:是指数据对象中数据元素之间的相互关系。
物理结构:是指数据的逻辑结构在计算机中的存储结构。

数据类型:是指一组性质相同的值的集合及定义在此集合上的一些操作的总称。
抽象是指抽取出事物具有的普遍性的本质。(抽取的意义在于数据类型的数学抽象特性)
抽象数据类型(Abstract Data Type ADT):是指一个数据模型及定义在该模型上的一组操作。
抽象数据类型体现了程序设计中问题分解、抽象和信息隐藏的特征。

算法:是解决特定问题求解步骤的描述,在计算机中表现为指令的有限序列,并且每条指令表示一个或多个操作。
程序在计算机运行的时间取决于以下因素:
也就是说一个程序的运行时间依赖于算法的好坏和问题的输入规模,最终在分析程序的运行时间时,最重要的是把程序看成是独立于程序设计语言的算法或一系列的步骤

在判断一个算法的效率时,函数中的常数和其他次要项常常可以忽略,而更应该关注主项的阶数

如何分析一个算法的时间复杂度呢?方法就是:

单纯的分支结构(不包含在循环结构中),其时间复杂度都是O(1)
分析算法的复杂度,关键是要分析循环结构的运行情况
int i; for (i = 0; i < n; i++)//时间复杂度为O(n) { }
int count = 1; while (count<n)//由于count乘2之后,就距离n更近了一步,也就是2的x次方等于2 x=log2的n //所以时间复杂度为O(logn) { count = count * 2; }
int i, j; for (i = 0; i < n; i++)//时间复杂度为O(n的平方) { for (j = 0; j < n; j++) { /*这里面的代码为时间复杂度为O(1)的程序步骤序列*/ } }
void fuc(int cout)//这个函数的时间复杂度为O(n) { for (int j = 0; j < n; j++) { /*这里面的代码为时间复杂度为O(1)的程序步骤序列*/ } } n++;//执行次数为1 fuc(n);//执行次数为n for (i = 0; i < n; i++) { fuc(i);//整个的执行次数为n2 } for (i = 0; i < n; i++) { for (j = 0; j < n; j++)//当i=0,内循环执行n 当i=1内循环执行n-1次... //所以总的执行次数为n+(n-1)+(n-2)+....+1=(n+1)n/2 { /*这里面的代码为时间复杂度为O(1)的程序步骤序列*/ } }
上述代码总的执行次数为1+n+n的平方+n(n+1)/2=3/2n的平方+3/2n+1所以最终的时间复杂度为O(n的平方)
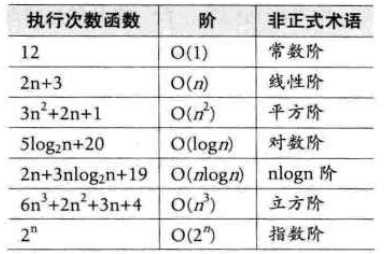

最坏情况运行时间是一种保证,也就是说运行时间不会比最坏情况下运行更长了。
平均运行时间是所有情况中最有意义的,因为它是期望的运行时间

标签:
原文地址:http://www.cnblogs.com/liyunhua/p/4621958.html