标签:

1 var express = require(‘express‘); 2 var app = express(); 3 4 app.get(‘/‘, function(req, res) { 5 res.send(‘hello express‘); 6 }); 7 8 app.listen(3000, function() { 9 console.log(‘listening on 3000‘); 10 });
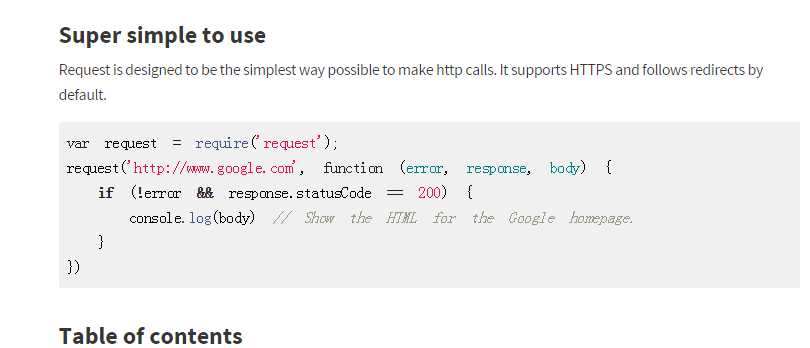
1 var express = require(‘express‘); 2 var app = express(); 3 var request = require(‘request‘); 4 5 app.get(‘/‘, function(req, res) { 6 request(‘http://www.cnblogs.com/galenyip‘, function (error, response, body) { 7 if (!error && response.statusCode == 200) { 8 console.log(body);// Show the HTML for the Google homepage. 9 res.send(‘hello express‘); 10 } 11 }); 12 }); 13 14 app.listen(3000, function() { 15 console.log(‘listening on 3000‘); 16 });
地址修改成我的博客地址吧。来爬爬我这个博客
OK,刷新我们的页面。等一会,会看到终端打印出了html相关信息。
接着,
我们用上 cheerio
在app.js中 我们就入 var cherrio = require(‘cherrio‘);
1 var express = require(‘express‘); 2 var app = express(); 3 var request = require(‘request‘); 4 var cheerio = require(‘cheerio‘); 5 6 app.get(‘/‘, function(req, res) { 7 request(‘http://www.cnblogs.com/galenyip‘, function (error, response, body) { 8 if (!error && response.statusCode == 200) { 9 $ = cheerio.load(body); //拿到body,作为选择器 10 } 11 }); 12 }); 13 14 app.listen(3000, function() { 15 console.log(‘listening on 3000‘); 16 });
同时,我们可以看到 cheerio.load(body)就是我们拿到的页面,把它作为总的选择器。
之后的,我们就可以像操作jq一样操作这个页面了。
具体的api可以到官网:
https://www.npmjs.com/package/cheerio
它的api跟jq很像,那这个就不做介绍了
其实,我们的整个爬虫就差不多了。
剩下的就是看客们根据自己的需要,去抓取页面的dom,筛选等等等等。。。。
好了。
大体就这么多了。
有不懂的,或者纰漏的,大家可以在评论里面交流拍砖。
标签:
原文地址:http://www.cnblogs.com/galenyip/p/4624312.html