标签:
分类器提升精确度主要就是通过组合,综合多个分类器结果,对最终结果进行分类。
组合方法主要有三种:装袋(bagging),提升(boosting)和随即森林。
装袋和提升方法的步骤:
1,基于学习数据集产生若干训练集
2,使用训练集产生若干分类器
3,每个分类器进行预测,通过简单选举(装袋)或复杂选举(提升),判定最终结果。
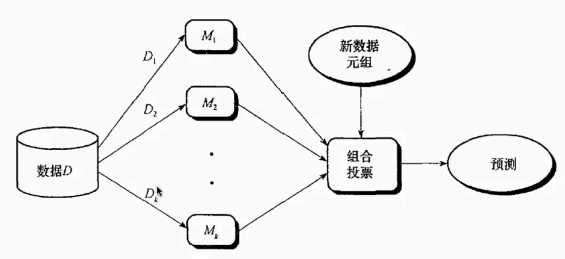
如上图所示,对数据集D,取得D1~Dk个子集,然后用M1~Mk个不同分类器进行分类训练,然后用测试集(新元组)得到预测结果,
最后对这k个结果使用少数服从多数原则判定。如用99种分类方法得到55个结果是1,44个结果是0,则判定最终结果为1。
在提升(boosting)算法中,可以看成是装袋的改进,即可以理解为加权投票。这里具体介绍adaptive boosting算法

该算法基本和袋装一致,就是新引入一个权重的概念,首先,在(1)初始化中,权重1/d,即每个元组(Di)权重一致,在地(9)~(11)步中,
对权重进行不断刷新,这里我们可以发现,被正确分类的元组的权重是一直乘以一个小于1的数,即被正确分类的元组,在被选为训练集Di的可能性降低,
分类器会关注“难以分类”的数据。我们是基于一个“某种分类器可能对某种特定的数据分类效果好”的信念上。
补充:元组概念:元组就是最小数据单位,比如人是一个元组,有身高,体重等属性。
在对数据进行训练后,就是用组合分类器。

这里我们看到,有出现一个权重,分类器的投票的权重,这个权重是依照分类器的准确率(错误率越低,权重越高)。
接下来是介绍决策树的提升算法:随机森林。
随机森林实际非常直观,就是用上文提到的随机装袋方法,对每个Di构建决策数,这里用CART算法建树(只需要计算Gini指数),不剪枝。
然后对让森林里所有的树进行投票即可。
附上R语言的随机森林事例:
//如果没有安装randomForest包,要先install.packages("randomForest")
library(randomForest)
model.forest = randomForest(Species~.,data=iris)
pre.forest=predict(model.forest,iris)
table(pre.forest,iris$Species)

正确率高达100%
而用单一的决策树
library(rpart) model.tree=rpart(Species~.,data=iris,method = "class") pre.tree=predict(model.tree,data=iris,type="class") table(pre.tree,iris$Species)

发现有一部分数据会被判错。
ps:组合分类器的算法摘自韩佳炜《数据挖掘概念与技术》。
标签:
原文地址:http://www.cnblogs.com/panpansky/p/4625239.html