标签:
继续上文,接着进行介绍
2.2编辑hadoop-env.sh
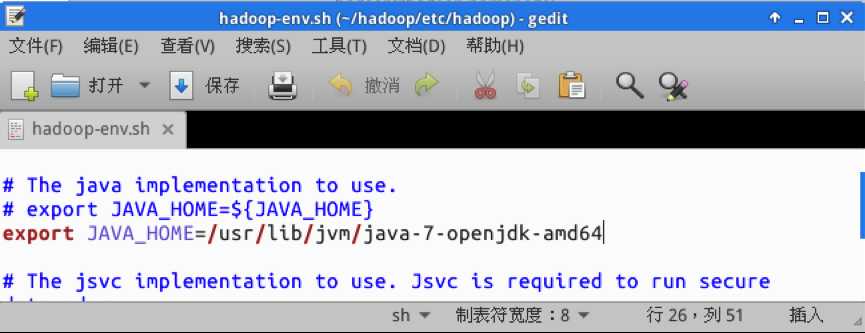
由于Hadoop是基于java编写的,所以需要在hadoop-env.sh里设置JDK路径。首先打开/etc/hadoop/hadoop-env.sh文件。
找到JAVA_HOME变量,将其修改为
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
如下图所示:
2.3配置core-site.xml
core-site.xml配置集群的全局参数,主要定义了系统级别的参数,如HDFS URL、Hadoop的临时目录等信息。
在终端中输入sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
打开core-site.xml。打开后在<configuration></configuration>之间增加如下图所示内容,然后保存。
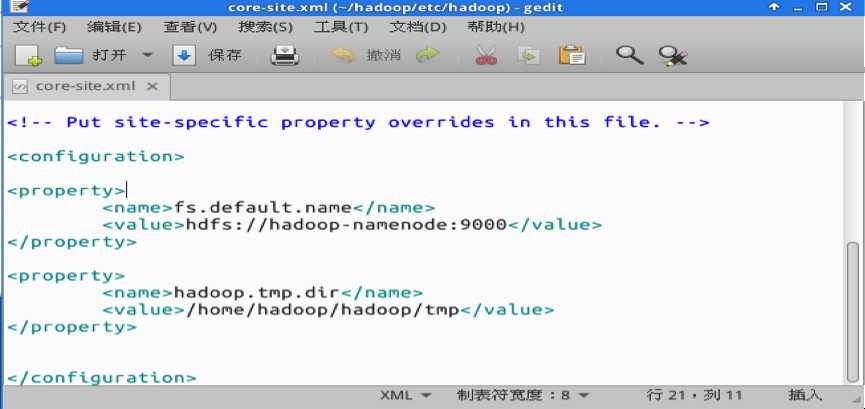
fs.default.name 设置的是NameNode RPC交互端口默认值为8020端口,这里我们将其设为9000端口。hadoop.tmp.dir为临时目录设定,设定在/home/hadoop/hadoop/tmp目录下。其他的配置没有进行设定,采用其默认配置。
2.4配置yarn-site.xml文件
yarn-site.xml配置集群资源管理系统的参数,包括ResourceManager,NodeManager 的通信端口,web 监控端口等内容。
在终端中输入sudo gedit /home/hadoop/hadoop/etc/hadoop/yarn-site.xml
打开yarn-site.xml。打开后在<configuration></configuration>之间增加配置,如下图所示:
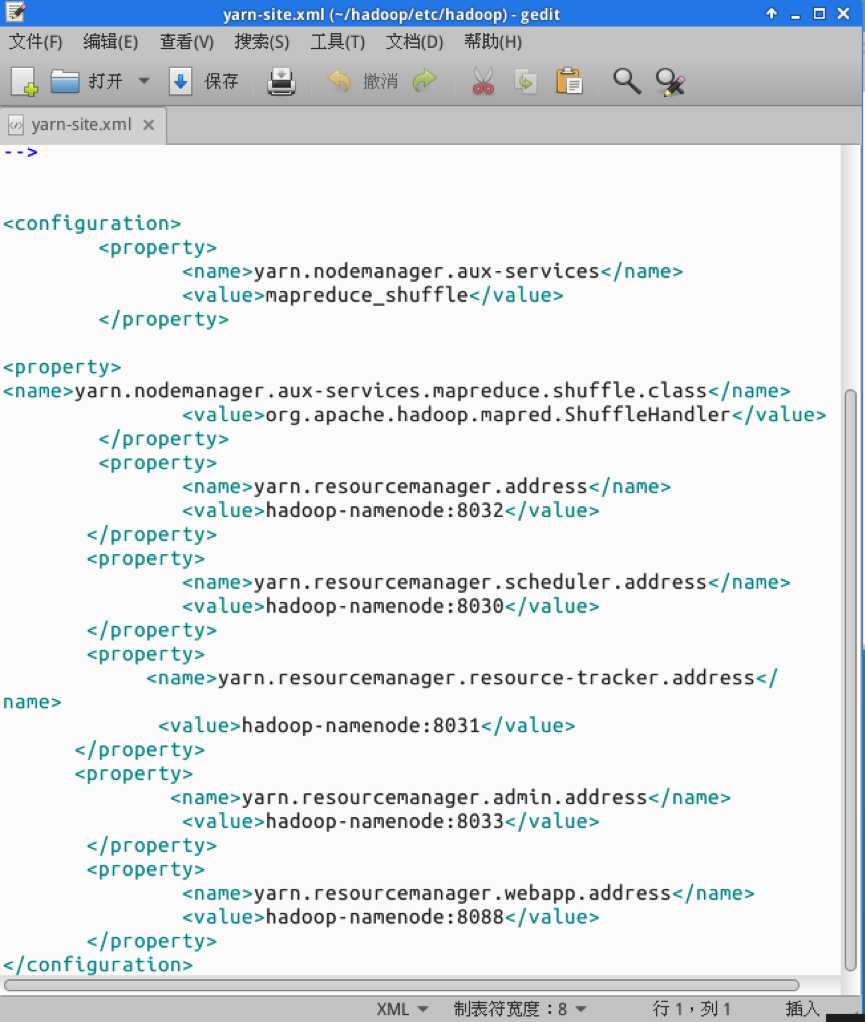
配置yarn.nodemanager.aux-services可以自定义一些服务内容,本集群中设置为mapreduce-shuffle,这样就可以实现mapreduce的shuffle功能
2.5配置mapred-site.xml文件
marpred-site.xml用于配置mapreduce参数,包含JobHistory Server和应用程序参数两部分。默认情况下,/usr/local/hadoop/etc/hadoop/文件夹下只有mapred.xml.template文件。
在终端中输入命令cp etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml
复制该文件,并命名为mapred.xml,该文件用于指定Map/Reduce使用的框架。
然后在终端中输入:
sudo gedit /home/hadoop/hadoop/etc/hadoop/mapred-site.xml
打开mapred-site.xml。打开后在<configuration></configuration>之间增加配置,如下图所示:
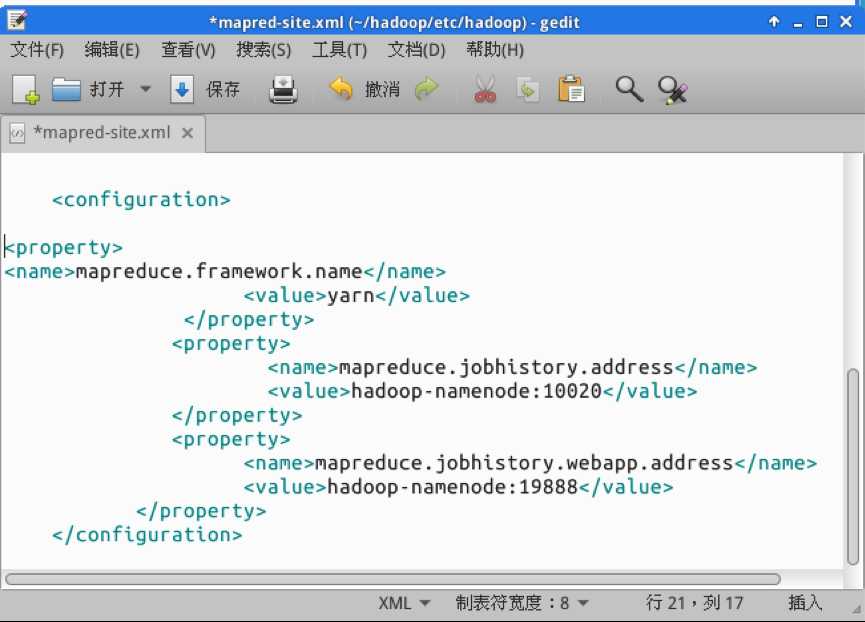
mapreduce.framework.name 设置的是Map/Reduce框架类型,默认值为local。本集群安装的是第二代Hadoop系统,采用的Map/Reduce编程框架是yarn,所以设置值为yarn。mapreduce.jobhistory.address定义历史服务器的地址和端口,可以通过历史服务器查看已经运行完的Map/Reduce作业记录。mapreduce.jobhistory.webapp.address用于设定历史服务器的web应用访问的地址和端口。
2.6配置hdfs-site.xml文件
hdfs-site.xml中设置的主要是NameNode和DataNode的存储位置,备份文件副本的个数和文件的读取权限等信息。
在终端中输入sudo gedit /home/hadoop/hadoop/etc/hadoop/hdfs-site.xml
打开hdfs-site.xml文件。打开之后进行配置,配置内容如下图所示:
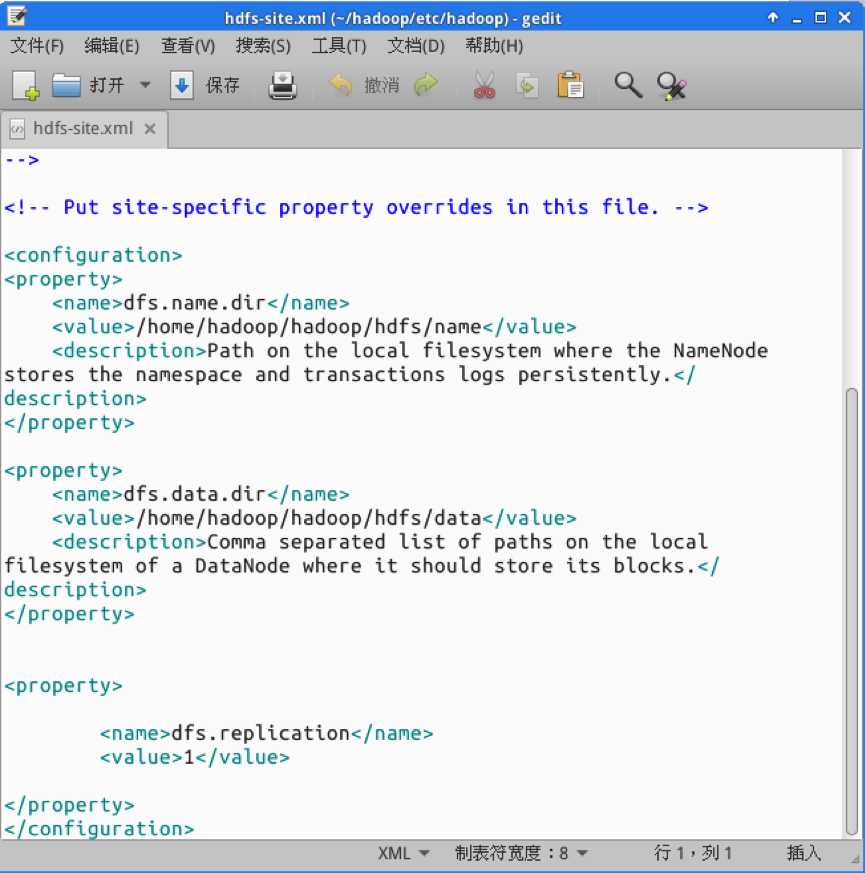
dfs.name.dir配置的是DFS(分布式文件系统)的NameNode在本节点的文件系统中的位置。而dfs.data.dir配置的是DataNode在本节点的文件系统中的位置。
dfs.replication配置的是数据块的备份数量,最高为3.
2.7Master/Salves设置
在NameNode节点的/home/hadoop/hadoop/etc/hadoop路径下创建两个文本文件,分别命名为masters和slaves。在masters文件下输入hadoop-namenode,hadoop-namenode表示的是192.168.1.110这个IP地址,与之前设置静态IP时对应,在slaves下输入hadoop-datanode1和hadoop-datanode2,作用是Datanode的IP地址。设置完成后,点击保存保存,并将这两个文件复制到其他服务器节点的相同路径下。
三、启动Hadoop
3.1格式化HDFS
启动Hadoop之前要先在NameNode节点上格式化NameNode。在终端中输入命令:hadoop namenode –format即可
3.2启动Hadoop
格式完成之后打开/home/hadoop/hadoop/sbin/start-all.sh文件就可运行Hadoop平台了。
登录http://192.168.1.110:50070即可查看节点信息。
登录http://192.168.1.110:8088可以查看任务信息
Ubuntu中搭建Hadoop2.5.2完全分布式系统(二)
标签:
原文地址:http://www.cnblogs.com/tjucs/p/4629544.html