This article introduces the networking part of Elasticsearch. We look at the network topology of an Elasticsearch cluster, which connections are established between which nodes and how the different Java clients works. Finally, we look a bit closer on the communication channels between two nodes.
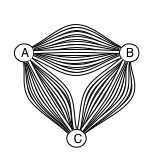
Elasticsearch nodes in a cluster form what is known as a full mesh topology, which means that each Elasticsearch node maintains a connection to each of the other nodes.
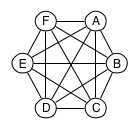
In order to simplify the code base, the connections are used as one-way connections, so the connection topology actually ends up looking like this:
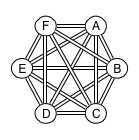
When a node starts up, it reads a list of seed nodes from its configuration using unicast, and sends multicastmessages looking for other nodes in the same cluster.
As the node discovers more instances in the same cluster, it connects to them one by one, asks them for information about all the nodes they know and then attempts to connect to them all and officially join the cluster. In this way, previously running instances assist in quickly getting fresh instances up to speed on the current nodes in a cluster.
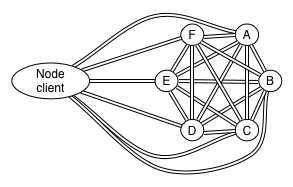
Even “client” Elasticsearch nodes (i.e nodes configured with node.client: true or build with NodeBuilder.client(true)) connect to the cluster this way.
This implies that the client node becomes a full participant in the full mesh network. In other words, once it starts joining the cluster, all the existing nodes in the cluster will connect back to the instance. This means that both the client and server firewalls and publish hosts must be properly configured in order to allow this. Additionally, whenever a node client joins, leaves or experiences networking issues, it causes extra work for all the other nodes in the cluster, such as opening / closing network connections and updating the cluster state with the information about the node.
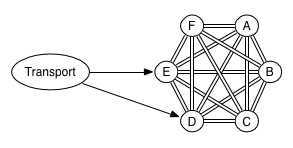
On the other hand, “transport” clients work differently.
When a Transport client connects to one or more instances in a cluster, the instances do not connect back, nor is the existence of the transport client part of the cluster state. This means that a joining / leaving transport client causes minimum extra work for the other nodes in the cluster.
What do we mean when we talk about the connection to a Node in Elasticsearch? In the sections above, we refrained from being specific about it and only used the term as a logical connection that allows communication between two nodes. Let’s go into more detail.
Usually, when we talk about connections in the context of networks, we refer to TCP-connections, which provide a reliable line of communication between two nodes.
Elasticsearch uses (by default) TCP for communication between nodes, but in order to prevent important traffic such as fault-detection and cluster state changes from being affected by far less important, slower moving traffic such as query/indexing requests, it creates multiple TCP connections between each node. For each of these connections, Elasticsearch uses the term channel, which encapsulates the serialization / deserialization of messages over a particular connection.
In earlier Elasticsearch versions there used to be three different classes of channels: low, med and high. After a while, ping was added, and a recent change renamed these channels such that they are more descriptive about their intention. At of the time of writing, the following channel classes exist:
recovery: 2 channels for the recovery of indexesbulk: 3 channels for low priority bulk based operations such as bulk indexing. Previously called low.reg: 6 channels for medium priority regular operations such as queries. Previous called med.state: 1 channel dedicated to state based operations such as changes to the cluster state. Previously called high.ping: 1 channel dedicated to pings between the instances for fault detection.The default number of channels in each of these class are configured with the configuration prefix of transport.connections_per_node.
Elasticsearch has support for TCP keepalive which is not explicitly set by default. This prevents unused or idle channels from being closed, which would otherwise cascade into a complete disconnect-reconnect cycle as explained above.
A consequence of the above is that adding a new instance to an existing cluster causes it to establish 13 connections to each node, and each node establishes 13 connections back to the new instance.
If one of the 13 channels to a particular node is closed due to intermittent network errors for example, all the other channels to the same node are closed and the connections to the node is reconnected. This is done in order to maintain some internal invariants and to ensure the internal consistency of the communication between the nodes.
The fact that all the channels between two nodes in a cluster are linked makes it extra vulnerable to network issues, and this is one of the reasons why people are discouraged from trying to create a cluster between data centers that are far apart (and thus adding more sources of failure).
In this article we’ve shown the basic network topology of an Elasticsearch cluster and introduced the concept of channels that are used for communication between nodes. In a later article we’ll take a closer look at what goes on inside each of these channels.
Elasticsearch Internals: Networking Introduction An Overview of the Network Topology,布布扣,bubuko.com
Elasticsearch Internals: Networking Introduction An Overview of the Network Topology
原文地址:http://www.cnblogs.com/huangfox/p/3824699.html