标签:
转载http://www.cnblogs.com/mayswind/archive/2013/03/17/2962205.html
【题外话】
这是2010年参加比赛时候做的研究,当时为了实现对Word、Excel、PowerPoint文件文字内容的抽取研究了很久,由于Java有POI 库,可以轻松的抽取各种Office文档,而.NET虽然有移植的NPOI,但是只实现了最核心的Excel文件的读写,所以之后查了很多资料才实现了 Word和PowerPoint文件文字的抽取。之后忙于各种事情一直没时间整理,后来虽然想写成文章但由于时间太久也记不清很多细节,现在重新查找资料 并整理如下,希望对大家有用。
【系列索引】
获取Office二进制文档的DocumentSummaryInformation以及SummaryInformation
【文章索引】
10年的时候参加比赛要做一个文件检索的系统,要包含Word、PowerPoint等文件格式的全文检索。由于之前用过.NET并且考虑到这些是微软的 格式,可能使用.NET读取会更容易些,但没想到.NET这边查到的资料只有Interop的方式读取Office文件。后来接触了Java的POI,发 现.NET也有移植的NPOI,但是只移植了核心的Excel读写,并没有Word、PowerPoint等文件的读写,所以最后没有办法只能硬着头皮自 己去做Word和PowerPoint文件的解析。
那么Interop是什么?Interop的全称是“Interoperability”,即微软希望托管的.NET能与非托管的COM进行互相调用的一 种方式。通过Interop读写Office即调用安装在计算机上的Office软件来实现Office的读写,其优点显而易见,文件还是由Office 生成或读取的,所以与自己打开Office是没有任何区别的;但缺点也非常明显,即运行程序的计算机上必须安装有对应版本的Office软件,同时操作Office文件时实际上是打开了对应的Office组件,所以运行效率低、耗内存大并且还可能产生内存泄露的问题。关于Interop方式读写Office文件的例子网上有很多,有兴趣的可以自行查阅,这里就不再多讲了。
那么,有没有方式不借助Office软件实现Office文件的读写呢?答案肯定是肯定的,就像Java中的POI及.NET中的NPOI实现的那样,即 通过程序自己读写文件来实现Office文件的读写。不过由于Office文件结构非常复杂,这里只提供文件摘要信息和文件文本内容的解析。不过即使如 此,对于全文检索什么的还是足够的。
前几年,微软开放了一些私有格式的规范,使得所有人都可以对其文件进行解析,而不需要支付任何费用,这也使得我们编写解析文件的程序成为可能,相关链接在 文章最后可以找到。对于一个Microsoft Office文件,其实质是一个Windows复合二进制文件(Windows Compound Binary File),文件的头Header是固定的512字节,Header 记录文件最重要的参数。Header之后可以分为不同的Sector,Sector的种类有FAT、Mini-FAT(属于Mini-Sector)、 Directory、DIF、Stroage等五种。为了方便称呼,我们规定每个Sector都有一个SectorID,Header后的Sector为第一个Sector,其SectorID为0。
我们先来说Header,一个Header的部分截图及包含的信息如下,比较重要的用粗体表示。

那么我们可以写如下的代码将Header中重要的内容解析出来。
 View
Code
View
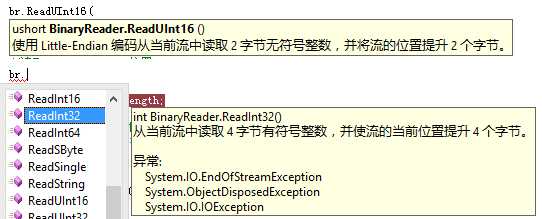
Code说个比较有意思的,.NET中的BinaryReader有很多读取的方法,比如ReadUInt16、ReadInt32之类的,只有 ReadUInt16的Summary写着“使用 Little-Endian 编码...”(见下图),其实不仅仅是ReadUInt16,所有ReadIntX、ReadUIntX、ReadSingle、ReadDouble都 是使用Little-Endian编码方式从流中读的,大家可以放心使用,而不需要一个字节一个字节的读再反转数组,我在10年的时候就走过弯路。解释在 MSDN各个方法中的备注里:http://msdn.microsoft.com/zh-cn/library/vstudio/system.io.binaryreader_methods.aspx
复合文档中其实存放着很多内容,这么多内容需要有个目录,那么Directory就是这个目录。从Header中我们可以读取出Directory开始的 SectorID,我们可以Seek到这个位置(0x200 + sectorSize * dirStartSectorID)。Directory中每个DirectoryEntry固定为128字节,其主要结构如下:
显然,Directory其实是一个树形的结构,我们只要从第一个Entry(Root Entry)开始递归搜索就可以了。
为了方便开发,我们创建一个DirectoryEntry的类
View
Code然后我们递归搜索就可以了
View
Code
【四、DocumentSummaryInformation和SummaryInformation】
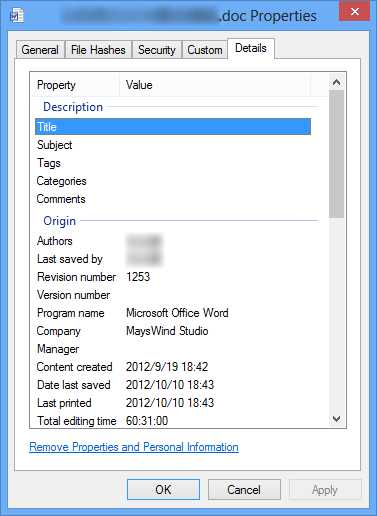
Office文档包含很多摘要信息,比如标题、作者、编辑时间等等,如下图。
摘要信息又分为两类,一类是DocumentSummaryInformation,另一类是SummaryInformation,分别包含不同种类的 摘要信息。通过上述的代码应该能获取到Root Entry下有一个叫“\005DocumentSummaryInformation”的Entry和一个叫“ \005SummaryInformation”的Entry。
对于DocumentSummaryInformation,其结构如下
对于每个属性组,其结构如下:
常见的属性编号有以下这些:
View
Code对于每个属性,其结构如下:
为了方便开发,我们创建一个DocumentSummary的类。比较有意思的是,不论DocumentSummaryInformation还是 SummaryInformation,第一个属性都是记录该组内容的代码页编码,可以通过Encoding.GetEncoding()获取对应的编码 然后用GetString把对应的字符串解析出来:
View
Code然后我们进行读取就可以了:
View
Code而SummaryInformation与DocumentSummaryInformation相比读取方式是一样的,只不过属性组的16位标识为 0xE0 0x85 0x9F 0xF2 0xF9 0x4F 0x68 0x10 0xAB 0x91 0x08 0x00 0x2B 0x27 0xB3 0xD9。
常见的SummaryInformation属性的属性编号如下:
View
Code其他代码由于与DocumentSummaryInformation相近就不再单独给出了。
附,本文所有代码下载:http://files.cnblogs.com/mayswind/DotMaysWind.OfficeReader_1.rar
1、Microsoft Open Specifications:http://www.microsoft.com/openspecifications/en/us/programs/osp/default.aspx
2、用PHP读取MS Word(.doc)中的文字:https://imethan.com/post-2009-10-06-17-59.html
3、Office檔案格式:http://www.programmer-club.com.tw/ShowSameTitleN/general/2681.html
4、LAOLA file system:http://stuff.mit.edu/afs/athena/astaff/project/mimeutils/share/laola/guide.html
获取Word二进制文档(.doc)的文字内容(包括正文、页眉、页脚、批注等等)
【题外话】
上篇文章很荣幸被NPOI的大神回复了,同时也纠正了我一个问题,就是NPOI其实是有doc文件的解析,只不过一直没有跟随正式版发布过,要获取这部分代码,可以移步CodePlex(http://npoi.codeplex.com/),访问在SourceCode中的NPOI.ScratchPad中即可看到。给大家造成的不便在此表示抱歉。
【文章索引】
我们接着第一篇的代码继续,不知大家有没有查看过Directory获取到的内容,比如 上次的文档摘要SummaryInformation和DocumentSummaryInformation,除此之外还有专门存储文档内容的 DirectoryEntry,比如Word的为“WordDocument”和“1Table”,PowerPoint的为“PowerPoint Document”,Excel的为“Workbook”。
我们先从WordDocument说起。不知大家发现了没有,其实不论是哪个Word文 件,WordDocument这个DirectoryEntry的SectorID总是0,也就是说,WordDocument其实就是Header之后 的第一个Sector。对于WordDocument,其最重要的应该是其中包含的FIB(File Information Block)了,FIB位于WordDocument的开头,其包含着Word文件非常重要的参数,诸如文件的加密方式、文字的编码等等。
对于一个FIB,官方文档中说是可变长的,其中FIB中最开头的为固定32字节长的FibBase:

那FibBase之后呢?其实FIB包含很多的内容,从FibBase开始按顺序分别是:
看完FIB结构后我们先来看下nFib与文件版本对应的情况:
由于FIB中内容实在太多了,之后的部分就不再介绍了,不过为了读取文档的内容我们还应该看看如下的内容(当然也不一定都用到)。
以上这些信息我们可以编写如下代码获取:
View Code
Table Stream其实就是1Table或者0Table的总称,具体文字存在那个Table中还要根据FIB中的信息。由于复合文件是以一个个Sector形 式存储的,所以我们首先需要获取文字存储在哪些个Sector中。实际上,文本的存储是由Piece Element(暂且这么叫吧)控制着,包括是否启用Unicode、每块的位置等等,这些内容都存放于Table Stream中的Piece Table中,Piece Table相对Table Stream的偏移量可以从FIB中获取到。
关于Piece Element,官方是这么描述的:

看上去这么多,其实我们需要的仅是fc中定义的是否使用Unicode存储文本(fc中 第31位为0则为Unicode,为1则为Ansi),以及文本相对于WordDocument的偏移量(fc中低位30位),我们首先对Piece Element定义一个类,可以看出,一个Piece Element的大小实际为2 + 4 + 2 = 8字节:
View Code
然后我们来看Piece Table,其结构为:
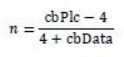
Piece Table信息我们可以编写如下代码获取:
View Code
上头我们可以获取到Word中文本的开始和结束位置,其实一个Word文档中,文字是按如下顺序存储的:
所以,我们可以根据FibRgLw97中获取的每一部分的字数以及Piece Table中起始的位置来获取每一部分的文字。
比如正文内容的位置为[0, ccpText],页脚的位置为[ccpText + 1, ccpText + 1 + ccpFtn]……
所以我们编写如下代码获取:
View Code不过需要注意的是,由于Word文档中的换行为“\r”(CR),而Windows中的换行符为“\r\n”(CR+LF),所以获取文字后需要将“\r”替换为“\r\n”,否则换行将无法正常显示,除此之外,还有其他的一些特殊字符也需要替换或处理。
附,本文所有代码下载:http://files.cnblogs.com/mayswind/DotMaysWind.OfficeReader_2.rar
1、Microsoft Open Specifications:http://www.microsoft.com/openspecifications/en/us/programs/osp/default.aspx
2、用PHP读取MS Word(.doc)中的文字:https://imethan.com/post-2009-10-06-17-59.html
3、Office檔案格式:http://www.programmer-club.com.tw/ShowSameTitleN/general/2681.html
4、LAOLA file system:http://stuff.mit.edu/afs/athena/astaff/project/mimeutils/share/laola/guide.html
详细介绍Office二进制文档中的存储结构,以及获取PowerPoint二进制文档(.ppt)的文字内容
【题外话】
我突然发现现在做Office文档的解析要比2010年的时候容易得多,因为文档从2010年开始更新了好多好多次,读起来也越来越容易。写前两篇文章的 时候参考的好多还是微软的旧文档(2010年的),写这篇的时候重下了所有的文档,发现每个文档都好读得多,整理得也更系统,感觉微软真的是用心在做这个 开放的事。当然,这些文档大部分也是2010年的时候才开始发布出来的,仔细想想当年还是很幸运的。
【文章索引】
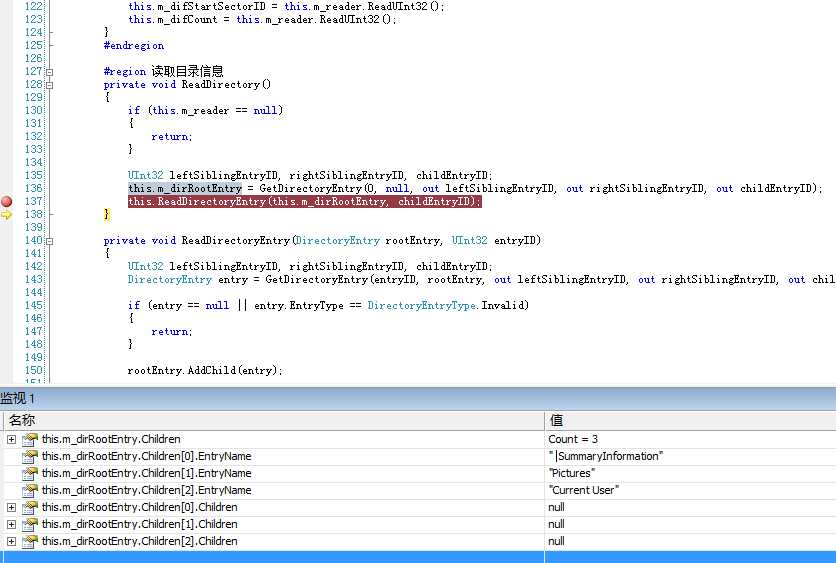
在刚开始做解析的时候,大都是从Word文档(.doc)入手,而doc文档没有太多复 杂的东西,所以按照流程都可以轻松做到,也不会出现什么差错。但是做PowerPoint解析的时候就会遇到很多问题,比如如果按第一节讲的进行解析 Directory的话会发现,很多PowerPoint文档是没有DocumentSummaryInformation的,这还不是关键,关键是,还 有一部分甚至连PowerPoint Document都没有,见下图。
其实这种问题不光解析PowerPoint的时候会遇到,解析Excel的时候同样会遇到,那么这到底是什么问题呢?其实我们在读取Directory时,认为Directory所在的Sector是按EntryID从小到大排列的,但实际上DirectoryEntry并不一定是这样的,并且有的Entry所在的Sector有可能在RootEntry之前。
不知大家是否还记得FAT和DIFAT这两个结构,虽然从第一篇就读取了诸如开始的位置和个数,但是一直没有使用,那么本篇先详细介绍一下这俩结构。
首先来看下微软的文档是如何描述这俩结构的:
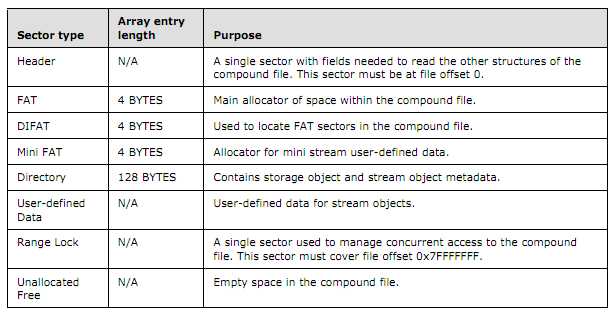
我们可以看到,FAT、DIFAT其实是4字节的结构,那他们有什么作用呢?我们知 道,Windows复合文档是以Sector为单位存储的文档,但是Sector的顺序并不一定是存储的前后顺序,所以我们需要有一个记录着所有 Sector顺序的结构,那么这个就是FAT表。
那么FAT表里存储的是什么呢?FAT表其实本身也是一个Sector,只不过这个 Sector存储的是其他Sector的ID,即每个FAT表存储了128个SectorID,并且这个顺序就是Sector的实际顺序。所以,获取了所 有的FAT表,然后再获取所有的SectorID,其实就获取了所有Sector的顺序。当然,我们其实只需要存储所有FAT表的SectorID就行, 然后根据根据SectorID在FAT表中查找下一个SectorID就可。
还记得第一篇读取文件头Header么?在文件头的最后有109块指向FAT表的 SectorID,经过计算,如果这109个FAT表全部填满,那么一共可以包括109 * 128个SectorID,也就是除了文件头一共有109 * 128 * 512字节,所以整个文件最多是512 + 109 * 128 * 512 = 7143936 Byte = 6976.5 KB = 6.81 MB。如果文件再大怎么办?这时候就有了DIFAT,DIFAT是记录剩余FAT表的SectorID的,也就是相当于Header中109个FAT表的 SectorID的扩充。所以,我们可以通过文件头Header和DIFAT获取所有FAT表的SectorID,然后通过这些FAT表的 SectorID再获取所有的Sector的顺序。
首先我们获取文件头中前109个FAT表的SectorID:
View Code需要说明的是,这里并没有判断FAT的数量是否大于109块,因为如果FAT为空,则标识为FreeSector,即0xFFFFFFFF,所以读取到FreeSector时表明之后不再有FAT,即可以退出读取。所有常见的标识见下。
protected const UInt32 MaxRegSector = 0xFFFFFFFA;protected const UInt32 DifSector = 0xFFFFFFFC;protected const UInt32 FatSector = 0xFFFFFFFD;protected const UInt32 EndOfChain = 0xFFFFFFFE;protected const UInt32 FreeSector = 0xFFFFFFFF;
如果FAT的数量大于109,我们还需要通过读取DIFAT来获取剩余FAT的位置,需要说明的是,每个DIFAT只存储127个FAT,而最后4字节则为下一个DIFAT的SectorID,所以我们可以通过此遍历所有的FAT。
View Code文章到这,大家应该能明白接下来做什么了吧?之前由于“理所当然”地认为Sector的顺序就是存储的顺序,所以导致很多DirectoryEntry无法读取出来。所以现在我们应该首先获取DirectoryEntry所占Sector的真实顺序。
View Code然后获取每个DirectoryEntry偏移的方法也应该改为:
View Code这样所有的DirectoryEntry就都能获取到了。
【二、奇怪的DocumentSummary和Summary】
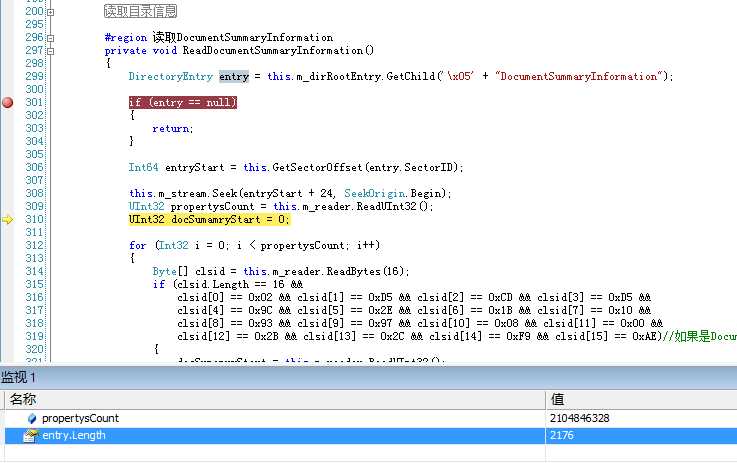
在能真正获取所有的DirectoryEntry之后,不知道大家发现了没有,很多文档 的DocumentSummary和Summary却还是无法获取到的,一般说来就是得到SectorID后Seek到指定位置后读到的数据跟预期的有太 大的不同。不过有个很有意思的事就是,这些无法读取的DocumentSummary和Summary的长度都是小于4096的,如下图。
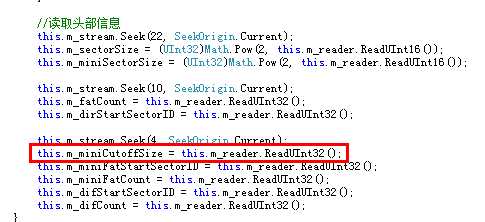
那么问题出在哪里呢?还记得不记得我们第一篇到读取的什么结构现在还没用到?没错,就是 MiniFAT。可能您想到了,DirectoryEntry中记录的SectorID不一定就是FAT的SectorID,还有可能是Mini- SectorID,这也就导致了实际上读取的内容与预期的不同。在Windows复合文件中有这样一个规定,就是凡是小于4096字节的内容,都要放置于 Mini-Sector中,当然这个4096这个数也是存在于文件头Header中,我们可以在如下图的位置读取它,不过这个数是固定4096的。
如同FAT一样,Mini-Sector的信息也是存放在Mini-FAT表中的,但是 Sector是从文件头Header之后开始的,那么Mini-Sector是从哪里开始的呢?官方文档是这样说的,Mini-Sector所占的第一个 Sector位置即Root Entry指向的SectorID,Mini-Sector总共的长度即Root Entry所记录的长度。我们可以通过刚才的FAT表获取所有Mini-Sector所占的Sector的顺序。
View Code光有了Mini-Sector所占的Sector的顺序还不够,我们还需要知道Mini-Sector是怎样的顺序。这一点与FAT基本相同,固不在此赘述。
View Code然后我们去写一个新的GetEntryOffset去满足不同的DirectoryEntry。
View Code现在再试试,是不是所有的Office文档的DocumentSummary和Summary都能读取到了呢?
跟Word不一样的是,WordDocument永远是Header后的第一个 Sector,但是PowerPoint Document就不一定咯,不过PowerPoint不像Word那样,要想读取文字,还需要先读取WordDocument中的FIB以及 TableStream中的数据才能读取文本,所有PowerPoint幻灯片的数据都存储在PowerPoint Document中。
简要说,PowerPoint中存储的内容是以Record为基础的,Record又包 括Container Record和Atom Record两种,从名字其实就可以看出,前者是容器,后者是容器中的内容,那么其实PowerPoint Document中存储的其实也就是树形结构。
对于每一个Record,其结构如下:
接下来常见的recType的类型:
由于PowerPoint支持上百种Record,这里只列举可能用到的一些Record,其他的就不一一列举了,详细内容可以参考微软文档“[MS-PPT].pdf”的2.13.24节。
为了更好地了解Record和PowerPoint Document,我们创建一个Record类
View Code然后我们遍历所有节点读取Record的树形结构
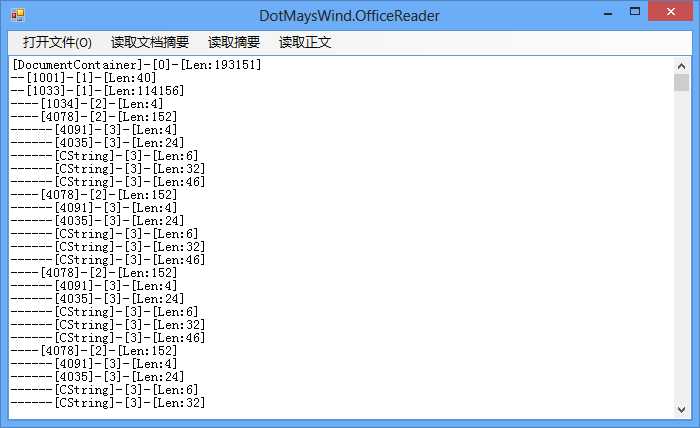
View Code结果类似于如下图所示
其实如果要读取PowerPoint中所有的文本,那么只需要读取所有的 TextCharsAtom、TextBytesAtom和CString就可以,需要说明的是,TextBytesAtom是以Ansi单字节进行存储 的,而另外两个则是以Unicode形式存储的。上节我们已经读取过Word,那么接下来就不费劲了吧。
我们其实只要把读取到Atom时跳过内容的那句话“this.m_stream.Seek(record.RecordLength, SeekOrigin.Current);”替换为如下代码就可以了。
View Code不过如果这样读取的话,也会把母版页及其他内容读取进来,比如下图:
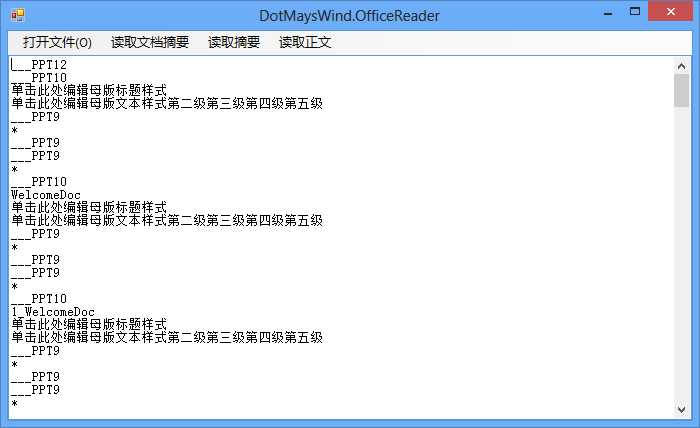
所以我们可以通过判断文字父Record的类型来决定是否读取这段文字。通常存放文字的 Record有“ListWithTextContainer和HeadersFootersContainer”,我们仅需要判断文字Record的父 Record是否是这俩就可以的。不过有一点,在用PowerPoint 2013存储的ppt文件,如果只判断这俩是读取不到内容的,还需要判断Type值为0xF00D的Record,不过这个RecordType在目前最 新的文档中并没有说明。
这里把完整的代码贴出来:
View Code最后附上这三篇文章全部的代码下载地址:http://files.cnblogs.com/mayswind/DotMaysWind.OfficeReader_3.rar
p.s.程序有多处偷小懒的情况,木哈哈。
1、Microsoft Open Specifications:http://www.microsoft.com/openspecifications/en/us/programs/osp/default.aspx
2、用PHP读取MS Word(.doc)中的文字:https://imethan.com/post-2009-10-06-17-59.html
3、Office檔案格式:http://www.programmer-club.com.tw/ShowSameTitleN/general/2681.html
4、LAOLA file system:http://stuff.mit.edu/afs/athena/astaff/project/mimeutils/share/laola/guide.html
介绍Office Open XML文档(.docx、.pptx)如何进行解析以及解析Office文件常见开源类库
【题外话】
这是这个系列的最后一篇文章了,为了不让自己觉得少点什么,顺便让自己感觉完美一些,就再把OOXML说一下吧。不过说实话,OOXML真的太容易 解析了,而且这方面的文档包括成熟的开源类库也特别特别特别的多,所以我就稍微说一下,文章中引用了不少的链接,感兴趣的话可以深入了解下。
【文章索引】
先来看一段微软官方对Office Open XML的说明(详细见http://office.microsoft.com/zh-cn/support/HA010205815.aspx?CTT=3):
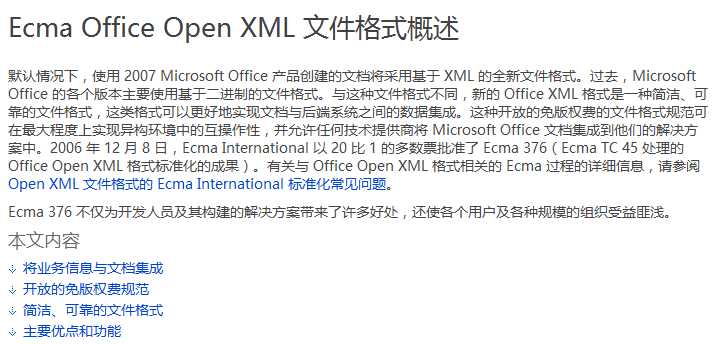
可以看到,与Windows 复合文档不同的是,OOXML生来就是开放的,而且由于基于zip+xml的格式,使得读取变得更容易,如果仅是为了抽取文字,我们甚至不需要读取文档的任何参数!
如果您之前不了解OOXML的话,我们可以把手头docx、pptx以及xlsx文件的扩展名改为zip,然后用压缩软件打开看看。
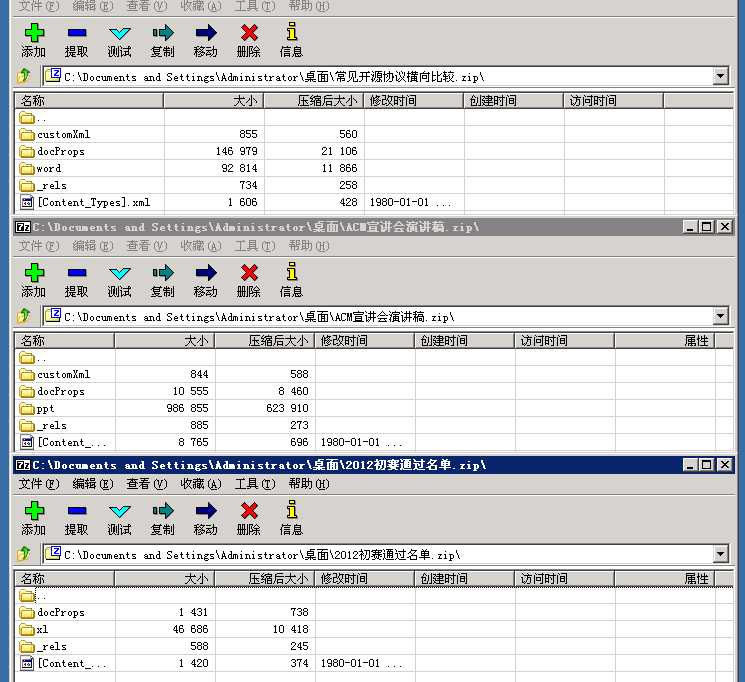
打开的这三个文件分别是docx、pptx和xlsx,我们可以看到,目录结构清晰可见,所以我们只需要使用读取zip的类库读取zip文件,然后 再解析xml文件即可。对于使用.NET Framework 3.0及以上的,可以直接使用.NET自带的Package类(System.IO.Packaging,在WindowsBase.dll中)进行解 压,个人感觉如果只是读取zip流中的文件流或内容,WindowsBase中的Package还是很好用的。如果用于.NET CF或者2.0甚至以下的CLR可以使用SharpZipLib(支持CLR 1.1、2.0、4.0,官方网站http://www.icsharpcode.net/),也可以使用DotNetZip(支持CLR 2.0,官方网站http://dotnetzip.codeplex.com/),个人感觉后者的License更友好些。
比如我们使用自带的Package打开OOXML文件:
View Code
OOXML文件的文档属性其实存在于docProps目录下,比较重要的有三个文件
我们只需要遍历XML文件中所有的子节点就可以读出所有的属性,为了好看,这里还用的Windows复合文件中的名称:
View Code
Word文件(.docx)主要的内容基本都存在于word目录下,比较重要的有以下的内容
这里我们只读取Word文档的正文内容,由于OOXML文档在存储文字时也是嵌套结构存储的,比如对于Word而 言,<w:p></w:p>之间存储的是段落,段落中会嵌套着<w:t></w:t>,而这个存储的是 文字。除此之外<w:tab/>是Tab符号,<w:br w:type="page"/>是分页符等等,所以我们需要写一个方法递归处理这些标签:
View Code
然后我们从根标签开始读取就可以了
View Code
PowerPoint文件(.pptx)主要的内容都存在于ppt目录下,而幻灯片的信息则又在slides子目录下,这里边幻灯片按照slide + 页序号 +.xml的名称进行存储,我们挨个顺序读取就可以。不过需要注意的是,由于字符串比较的问题,如 “slide10.xml”<"slide2.xml",所以如果你按顺序读取的话可能会出现页码错乱的情况,所以我们可以先进行排序然后再挨个页 面从根标签读取就可以了。
View Code
附,本系列全部代码下载:https://github.com/mayswind/SimpleOfficeReader
【五、常见Office文档(Word、PowerPoint、Excel)文件的开源类库】
1、NPOI:http://npoi.codeplex.com
这个没的说,.NET上最好的,没有之一,Office文档类库,提供完整的Excel读取与编辑操作,目前支持二进制(.xls)文件和 OOXML(.xlsx)两种格式。如果用过Apache的Java类库POI的话,NPOI提供几乎一样的类库。实际上,对于ASP.NET,需要编辑 的Office文档大多都是Excel文件,或者也可以使用Excel文件代替,所以使用NPOI几乎已经能满足所有需要。目前已经支持docx文件,而 doc的支持则在NPOI.ScratchPad中,大家可以去Source Code中下载自己编译。如果不需要OOXML的话,类库仅有1.5MB,并且支持.NET CLR 2.0和4.0。
2、Open XML SDK 2.0 for Microsoft Office:http://msdn.microsoft.com/en-us/library/bb448854(office.14).aspx
微软提供的Open XML SDK,支持读写任意OOXML文档,其同时提供了一个工具,可以打开Office文档然后直接生成使用该类库生成该文档的程序代码。只不过类库确实大了些,有5MB之多,并且需要.NET Framework 3.5的支持。
3、Office Binary Translator to Open XML:http://b2xtranslator.sourceforge.net/
这是我最近才知道的一个类库,其实很早很早以前就有了,其可以将Windows复合文档(.doc、.ppt、.xls)转换为对应的OOXML格 式(.docx、.pptx、.xlsx),当然你也可以获取文件中存储的内容。不知道为什么,这个网站被墙了。如果你想研究Windows复合文档的 话,我比较推荐这个类库,因为NPOI实在是太完美的一个类库,要想走一遍文件读取的流程实在是太复杂,但是如果用这个类库单步的话还是很容易懂的。这个 类库将每种文件的支持(以及支持的模块等)都拆分到了不同的项目中,支持每种文件仅需要几百KB,而且是基于.NET CLR 2.0的。
4、EPPlus:http://epplus.codeplex.com
在2010年NPOI还不支持OOXML的时候,个人感觉EPPlus是最好的.xlsx文件处理的类库,其仅有几百KB,非常轻量,对于zip文 件的读取,这个类库没有选择SharpZipLib或者DotNetZip,老版本需要.NET Framework 3.0就行,刚看了下新版本得需要.NET Framework 3.5才可以。
5、ExcelDataReader:http://exceldatareader.codeplex.com
也是一个非常轻量并且好用的库,同时支持读取.xls和.xlsx,当年在使用EPPlus之前使用的这个类库,记不得是因为什么问题替换成了 EPPlus,也不知道这个问题现在解决了没有。这个类库的好处是仅需要.NET CLR 2.0,并且支持.NET CF,只不过现在已经不需要开发Windows Mobile的应用了。
1、OpenXMLDeveloper.org:http://openxmldeveloper.org
2、如何:从 Office Open XML 文档检索段落:http://msdn.microsoft.com/zh-cn/library/bb669175.aspx
3、如何操作 Office Open XML 格式文档:http://www.microsoft.com/china/msdn/library/office/office/howManipulateOfficexml.mspx
4、如何实现...(打开 XML SDK):http://msdn.microsoft.com/zh-cn/library/bb491088.aspx
【后记】
终于到了最后一篇,这个系列就到这结束了,感谢大家的捧场,我也终于实现了两年前的心愿。说实话,我确实没想到第一篇会有那么多的访问和推荐,因为 需要解析Office文档的毕竟是少数的。写这四篇文章也希望起到抛砖引玉的作用,起码可以对Office文档有个最基础的了解,而之后如果想深入了解下 去也会容易得多,这也是我要把这些内容写出来的原因。
【补遗】
在写完这四篇文章后,我偶然发现微软关于这方面竟然有中文文档,泪奔了,为什么之前我没有找到。所以在此附上几篇常用的链接。
1、了解 Office 二进制文件格式:http://msdn.microsoft.com/zh-cn/library/gg615407(v=office.14).aspx
2、了解 Word MS-DOC 二进制文件格式:http://msdn.microsoft.com/zh-CN/library/gg615596
3、了解 PowerPoint MS-PPT 二进制文件格式:http://msdn.microsoft.com/zh-CN/library/gg615594
4、了解采用 Office 二进制文件格式的图形:http://msdn.microsoft.com/zh-CN/library/gg985447
5、在二进制 PowerPoint MS-PPT 文件中查找图形:http://msdn.microsoft.com/zh-CN/library/hh244173
Office文件的奥秘——.NET平台下不借助Office实现Word、Powerpoint等文件的解析
标签:
原文地址:http://www.cnblogs.com/joean/p/4631526.html