count组函数:(过滤掉空的字段)
select count(address),count(*) from b_user
max() avg() min(),sum()
select sum(age),max(age),min(age),avg(nvl(age,0)) from b_user
1 260 70 10 37.1428571428571
group by:如果前面定义了该字段名 则groupby必须也写上该字段
select name,pwd,sum(age) from b_user group by name,pwd
//如果取消group by name,age则报错,而且执行结果中如果有相同的则只取一条记录
select name,sum(age) from b_user group by name,age
不能在where语句中使用组函数,having则可以
having可以过滤分组结果
select name,sum(age) from b_user group by name,age having sum(age) >=50
select name,case when address is null then ‘无地址‘ else address end from b_user
case when语句
select name,case name
when ‘1‘ then age+10
else age+100
end 变后年龄
from bgt
select name,decode(name,‘1‘,age+10,‘2‘,age+100) 年龄 from bgt
select name,decode(name,‘1‘,age+10,age+100) 年龄 from bgt 去掉后表示其他的默认为age+100
多表查询:
等值连接
select * from inter_00201 a,inter_00202 b where a.ahd010401=b.ahd010401
不等值连接
select * from res_00201 a,res_00202 b where a.ahd050203 between 300.00 and 10000.00
外连接
左外连接
select * from res_00201 a,res_00202 b where a.intype=b.intype(+)
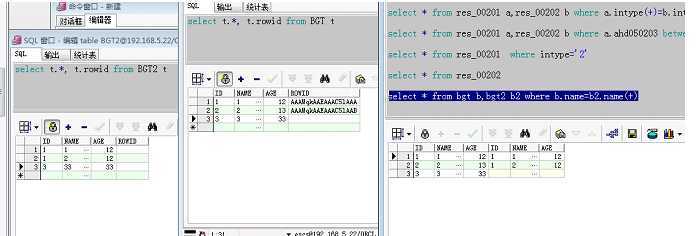
右外连接
select * from res_00201 a,res_00202 b where a.intype(+)=b.intype
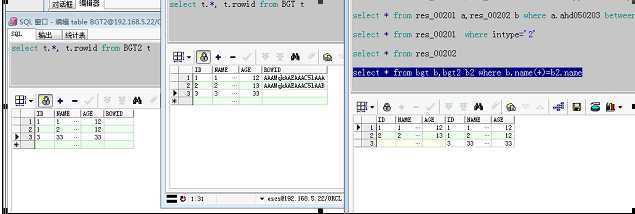
自连接(使用小表)
select * from inter_00201 a,inter_00202 b
层次查询
子查询:
子查询应该在括号里面
子查询相对于主查询往右缩进
在主查询的where from select having后面可以添加子查询
selct * from (select * from user where username=‘柳条‘)
该处子查询必须是单行子查询即是一条
select ename,(select job from emp where id=‘1000‘) from emp
在主查询的group by后边不可以放子查询
主查询和子查询可以不是同一张表,只有返回结果主查询可用即可.
select * from user where username=(select username from role where roleid=‘1012‘)
子查询中null值问题
如果存在null,且使用 not in subquery 则等同于<> all 返回未选定行
多行子查询操作符
in 等于列表中的任何一个
any 和子查询返回的任意一个值比较
select * from bgt where age< any (10,20,30,40)
任意小于10,20,30,40的符合条件的记录 即小于40的所有符合的记录.如果是大于则刚好相反,大于最小的
all 和子查询返回的所有值比较.
select * from bgt where age< all (20,30,40)
即所有小于20符合条件的记录.如果是大于则刚好相反
关于行号rownum
一旦生成就不变了
行号只能使用< <=不能使用> >=
select * from (select rownum r,age from (select rownum,age from bgt order by age desc) where rownum <=3 ) where r >=2
可以用此方式改变rownum,查询2--3条
select name,wm_concat(age) from bgt group by name可以进行分类拼接 比如等级为1的成员姓名
group by rollup()增强版的group by
select name,job,sum(sal) from emp group by rollup(name,job)
该sql相当于:
select name,job,sum(sal) from emp group by name,job
union
select name,to_char(null),sum(sal) from emp group by name
union
select to_char(null),to_char(null),sum(sal) from emp
集合运算符
并集 union/union all
交集 intersect
差集 minus
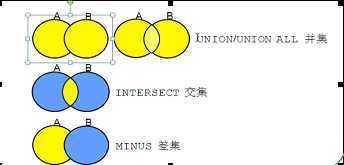
集合运算一般操作小表
set timing on 打开执行开关
set timing off 打开执行开关
set feedback off 关闭类型已选择14行.的提示
加载外部sql
@c:\sql.sql
特殊的插入(地址符):
insert into tablename(列1,列2,列3) values(&列1,&列2,&列3)
回车后会提示:
输入列1的值:..
输入列2的值:..
输入列3的值:..
select name,pwd,&unknown from user
输入unknown值:
result....
创建表结构的一种特殊方式:
create table user2 as select * from user where 1=2
如果表结构相同可以直接这样插入(没有会自动创建该表)
insert into user2 select * from user where username like ‘b%‘
输入列1的值:..
清空表
truncate table tablename(摧毁表再新建,释放空间,不会产生碎片,不可返回)
delete from tablename(逐个删除记录,可能产生碎片,且不会释放空间,可撤销操作)
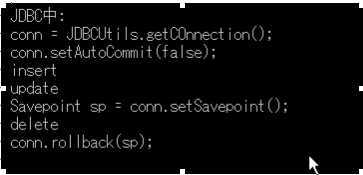
定义保存点:
savepoint 保存点名
rollback to savepoint 保存点名
在jdbc中设置保存点
oracle数据库的事务隔离级别
READ COMMITED,SERIALIZABLE两种以及自身的READ ONLY
而数据库提供的有四种:
READ UNCOMMITED(读未提交的数据)
READ COMMITED(读已提交的数据)
REPEATABLE READ (可重复读)
SERIALIZABLE(串行化)
oracle回收站功能
查看回收站:
show recyclebin
清空回收站:
purge recyclebin
彻底删除某张表:
drop table tablename purge
create table person(
pid number, pname varchar(20), gender varchar2(2) check (gender in(‘男‘,‘女‘)), age number check (age>0));
create table yueshu(
yid number constraint yushu_PK primary key,
yname varchar2(20) constraint yushu_Name not null,
email varchar2(30) constraint yushu_Email unique,
sal number constraint yushu_sal check(sal>10),
sex varchar2(2) constraint yushu_sex check(sex in(‘男‘,‘女‘)),
deptno number constraint yushu_deptno references dept(deptno) on delete cascade);
批注:deptno外键是dept表的主键deptno
表:基本的数据存储集合,由行和列组成。
视图:从表中抽出的逻辑上相关的数据集合。
select * from user_role_privs; 该语句可查出当前用户所有的权限
视图的优点:
限制数据访问,简化复杂查询,提供数据的相互独立,同样的数据,可以有不同的显示方式。
但视图不能提供性能
视图是一种虚表。
视图建立在已有表的基础上,视图赖以建立的这些表称为基表。
向视图提供数据内容的语句为select语句,可以将视图理解为存储起来的select语句。
视图向用户提供基表数据的另一种表现形式。
Create or replace view myView (列1,列2,列3,列4…) as select列1,列2,列3,列4…from tablename where 列1=10 with read only
加上with read only 表示只读
With check option 表示检测数据是否符合查询条件(比如insert视图时不能插入不符合条件的数据。)
Drop view viewname
序列:提供有规律的数值。
可供多个用户用来产生唯一数值的数据库对象。
自动提供唯一的数值,共享对象,主要用于提供主键值,将序列值装入内存可以提高访问效率。
create sequence mysequence increment by 1 start with 4 maxvalue 10 cache 3 cycle;
insert into table tablename values (mysequence.nextval,?,?,?,?)
alter sequence mysequence increment by 1 start with 4 maxvalue 10 cache 3 cycle;
drop sequence;
索引:提高查询的效率。
一种独立于表的模式对象,可以存储在与表不同的磁盘或者表空间中
索引被破坏或者损坏,不会对表产生影响,其影响的只是查询的速度。
索引一旦建立,oracle管理系统会对其进行自动维护,而且由oracle管理系统决定何时使用索引。用户不用在查询语句中指定使用哪个索引。
在删除一个表时,所有基于该表的索引会自动被删除。
通过指针加速oracle服务器的查询速度
通过快速定位数据的方法,减少磁盘I/O。
自动创建:定义primary key 或者unique等系统会自动在相应列上创建唯一性索引
手动创建:在其他列上创建非唯一性索引,已加速查询
Created index indexname on table (coloumn)
什么情况下创建索引:
列中数据值分布范围很广
列经常在where子句或连接条件中出现
表经常被访问而且数据量很大,访问数据大概占总量的2%~4%
什么情况下不合适创建索引
表很小
列不经常作为连接条件或出现在where子句中
查询数据大于2%~4%
表经常更新。
可以使用数据字典视图 USER_INDEXES 和 USER_IND_COLUMNS 查看索引的信息
Drop index indexname
同义词:给对象起别名。
使用同义词访问相同对象
方便访问其他用户的对象
缩短对象名称的长度
Create [public] synonym synonymname for object
Drop synonym name
Oracle组函数、多表查询、集合运算、数据库对象(序列、视图、约束、索引、同义词)等,布布扣,bubuko.com
Oracle组函数、多表查询、集合运算、数据库对象(序列、视图、约束、索引、同义词)等
原文地址:http://www.cnblogs.com/LT0314/p/3825904.html