标签:collection object java
1.集合的概念
集合:是Java API提供的一些类的实例,用于动态存储多个对象
JDK所提供的集合API位于Java.util包下。
2.集合框架图(都在util包下)
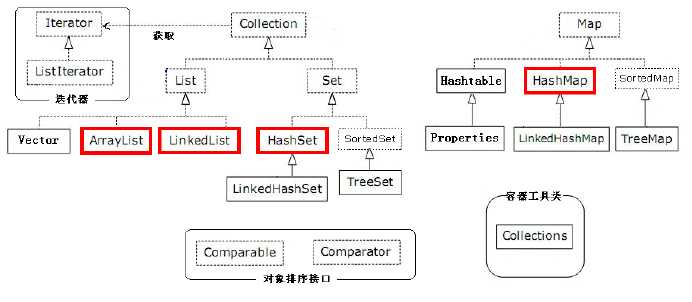
2.1 Collection下的常用方法
1.添加: add(e) ; addAll(Collection);
2.删除: remove(e); removeAll(collection); clear();
3.判断: contains(e); isEmpty();
4.获取: iterator(); size ();
5.获取交集:al1.retainAll(al2); al1只剩下与al2相同的元素
6.集合变数组:toArray();
注意:集合中存储的都是对象的引用(地址)
3.集合中泛型的使用
JDK1.4以前:
装入集合中的数据都会被当作是Object对象来存放,从而失去了自己的实际类型
从集合中取出元素时,需要进行强制类型转换。效率低,容易产生错误。
JDK5.0之后,可以用泛型解决这个问题
在定义一个集合的时候就指定该集合存储对象的数据类型。
如: Collection <String > coll=new ArrayList <String > ();
从集合中取出元素时,无需转型了。如: String str=it.next();
4.集合中泛型的优点
优点:a.简化集合的使用。b.增强代码的可读性和稳定性
意义:用于保护存入集合中元素的数据类型。
5.Iterator接口(迭代器)
所有Collection接口下的类都有iterator( )方法用以返回一个实现了Iterator接口的对象。
Iterator it=coll.iterator( );
6.Iterator迭代器的工作原理
Iterator是专门迭代输出的接口。迭代输出是指将元素进判断,如果有内容则将内容取出。
Iterator对象称作迭代器,方便的对集合里的元素进行遍历。
Iterator接口中定义了如下方法:
Boolean hasNext(); //判断游标的右边是否有元素
Object next (); //返回游标右边的元素,并将游标移到下一个位置
void remove(); //删除游标左边的元素。
7.List接口
List接口是Collection接口的子接口
注意:该接口下的元素都是有序,并可以重复的。
List集合中的元素都对应一个整数型的序号来记录该元素在集合中的位置,通过序号来存储集合中的元素。
List下的常用类:ArrayList ,LinkedList, Vector(不常用)。
8.List接口常用方法
List接口比Collection接口中新增的几个实用方法:
Object get (int index) ;//返回列表中的某个元素
Object add(int index ,Object element);//在某个位置插入某个元素
Object set(int index,Object element);//替换指定位置的元素
Object remove(int index); //删除某个位置的元素
ListIterator listIterator ();// 返回列表迭代器
9.ArrayList
ArrayList是使用数组结构实现的List集合
优点:通过索引快速获取对象。
缺点:删除或插入元素的速度慢,因为采用数组结构,后面的元素要一起移动。
10.LinkedList
LinkedList是采用双向链表实现的集合,允许null元素,优缺点刚好与ArrayList相反
优点:插入或删除速度快,适合实现栈(Stack)和队列(Queue)
缺点:获取较慢。
11.栈(Stack)和队列(Queue)
栈(Stack)的存储特点:LIFO,后进先出
队列(Queue)的存储特点:FIFO,先进先出。
12.Vector向量
大多数操作与ArrayList相同,区别是它是线程同步的
13.Set
a.Set接口:无序,元素不能重复。所以最多有一个null元素。
b.Set集合类:HashSet:散列表存放。TreeSet:有序存放。
注意:如果添加"相同"的元素,则无法添加(add)进去。这里的"相同"是通过equals()方法判断,
所以必须重写equals()和hashCode()方法,且equals判断的因素应该与hashCode的返回值因素一致。
14.HashSet的存储原理
根据每个对象的哈希值(hashCode()方法获取),按照一定的算法算出它的存储索引,把对象放在
一个叫散列表的相应位置(表元)中。
如果对应的位置没有元素,则存放,如果有元素,则该对象与对应位置的所有对象比较(equal
()),以查看该对象是否存在:还不存在则就存放,存在了就直接使用。
取对象时:
根据它的哈希值算出它的存储索引,在散列表上的表元(相应位置)上进行少量的比较操作就可找到
15.HashSet集合的特点及使用技巧
HashSet不保存元素的加入顺序。
HashSet对存,取,删对象都有很高的效率。
HashSet根据元素的哈希码进行存放,取出时也根据哈希码快速找到。
注意:对于存放到HashSet集合的对象的对应类,必须重写equals()和hashCode()方法以实现对象相等
注意:如果添加"相同"的元素,则无法添加(add)进去。
16.TreeSet的存储原理
TreeSet是采用红黑树结构对加入的元素进行排序存放的,即存放TreeSet中的元素必须是可"排序"的
注意:如果添加"相同"的元素,则无法添加(add)进去。
17.Comparable接口
所有可"排序"的类都可以通过java.lang.Comparable接口来实现。该接口中的唯一方法:
public int compareTo(Object obj) ;
返回0, 表示 this==obj
返回正数,表示 this>obj
返回负数,表示 this<obj
可"排序"的类通过Comparable接口的compareTo方法确定该类对象的排序方式。
局限性:实现该接口的类只能按照compareTo()定义的唯一方法进行排序。
如果同一类对象想要多种排序方式,应该为该类定义不同的比较器来实现。
TreeSet有一个构造方法允许给定构造器进行排序。
arraylist和linkedlist
ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
这一点要看实际情况的。若只对单条数据插入或删除,ArrayList的速度反而优于LinkedList。但若是批量随机的插入删除数 据,LinkedList的速度大大优于ArrayList. 因为ArrayList每插入一条数据,要移动插入点及之后的所有数据。
总结:
注意:TreeSet的唯一性与HashSet的唯一性不同:
HashSet根据equal方法和hashCode方法确定唯一性的。
TreeSet的唯一性是根据排序元素确定,在compare方法里某个排序元素“return 0”表示这两对象相同,则后添加进去的对象无法add
TreeSet有两种排序方式,一种是实现comparable接口,一种是添加已实现的比较器(compartor),
如果TreeSet两种方式都具备,则以比较器优先。
标签:collection object java
原文地址:http://beyondbycyx.blog.51cto.com/10507743/1673438