标签:
我们在线上巡检中发现,一个实例的pg_xlog目录,增长到4G,很是疑惑。刚开始怀疑是日志归档过慢,日志堆积在pg_xlog目录下面,未被清除导致。于是检查归档目录下的文件,内容如下。但发现新近完成写入的日志文件都被归档成功了(即在pg_xlog/archive_status里面,有对应的xxx.done文件)。
ls -lrt pg_xlog ... -rw------- 1 xxxx xxxx 16777216 Jun 14 18:39 0000000100000035000000DE -rw------- 1 xxxx xxxx 16777216 Jun 14 18:39 0000000100000035000000DF drwx------ 2 xxxx xxxx 73728 Jun 14 18:39 archive_status -rw------- 1 xxxx xxxx 16777216 Jun 14 18:39 0000000100000035000000E0 ls -lrt pg_xlog/archive_status ... -rw------- 1 xxxx xxxx 0 Jun 14 18:39 0000000100000035000000DE.done -rw------- 1 xxxx xxxx 0 Jun 14 18:39 0000000100000035000000DF.done -rw------- 1 xxxx xxxx 0 Jun 14 18:39 0000000100000035000000E0.done
仔细观察,奇怪的是,pg_xlog里面还有一些日志文件,其文件名对应了还没产生的日志号!如下所示,当前正在被写入的日志号为100000035000000E0左右,却出现了名为1000000360000000C的日志文件名,更蹊跷的是,其修改时间还在很早以前,就是说不是新近创建或修改过的,如下面的文件修改或创建时间是在当前时间的一个小时之前:
ls -lrt pg_xlog .... -rw------- 1 xxxx xxxx 16777216 Jun 14 17:37 00000001000000360000000C -rw------- 1 xxxx xxxx 16777216 Jun 14 17:37 000000010000003600000014 ....
这是怎么回事呢?难道是“幽灵日志”?下面我们要搞清楚两个问题:1)为什么会出现”幽灵日志“?2)PG正常情况下日志空间大小是多少?
要回答上述问题,需要先摸清PG的日志创建、保持和清理机制。与此直接相关的模块有:日志写入(WAL writer)进程和日志归档(archiver)进程。其实检查点(checkpointer)进程和日志发送进程(WAL sender)也与此有关。
WAL writer负责异步把WAL日志刷入磁盘;与此同时,其他普通后台进程,也可能会同步的将WAL日志刷入磁盘,我们先从分析它们入手。从代码里面不难看出,它们将日志写入新的日志文件时,有如下函数调用:
XLogWrite -> XLogFileInit ->BasicOpenFile
BasicOpenFile负责打开一个新的日志文件,如果文件不存在,则新建文件。而其代码注释里面提到“Try to use existent file (checkpoint maker may have created it already)”,即打开的文件可能已经被checkpointer进程创建。
于是我们将目光转向checkpointer。其主要函数CheckpointerMain的逻辑如下:
重点内容都在CreateCheckPoint函数中,其逻辑如下:
可以看到,在这里出现日志删除、预分配等逻辑。也就是说PG的日志文件可能是在做检查点操作时预分配的!预分配的文件名使用了“未来”的目前还不存在的日志号,这就解释了我们之前遇到的“幽灵日志”情况,也回答了我们的第一个问题。
当然,需要说明的是,日志的保留和删除还和是否被archiver进程归档成功有关。
继续看第二个问题。前面提到的日志空间暴增让我们如临大敌,那么PG日志到底最多会占用多少空间?我们遇到的涨到3G情况正常吗?
从日志清理逻辑(重点是KeepLogSeg和RemoveOldXlogFiles函数)的分析,我们得到下面的结论:
2*checkpoint\_segments + 1。checkpoint_segments为一个可配置的参数,控制了两个检查点间产生的日志文件数量。另外,为讨论方便,下面我们先做如下假设:
设某次检查点操作完成时的时间点为A,则此时做日志预分配的情形如下图所示:
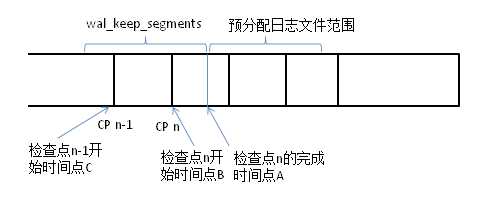
候选被回收的文件是在时间点C之前的、并且大于wal_keep_segments个文件间隔的文件;这些文件将重命名为预分配文件,文件号为从A对应的日志开始递增,直到达到2*checkpoint_segments + 1个文件为止。
做检查点操作过程中,是不断产生新日志文件的,而且两次检查点之间的日志文件数为一个稳定的值,即checkpoint_segments。因此,在时间点B到A之间产生的日志数约为
checkpoint_segments * checkpoint_completion_target
待A时间点预分配完日志文件,并删除其他不需要的日志后,新产生的日志将使用预分配空间,日志空间不会增大,日志空间大小达到一个稳定状态。而此时日志的空间至少为:保留的日志空间 + 预分配空间 + 正在被写入的那个文件,即为:
max(wal_keep_segments, checkpoint_segments + checkpoint_segments*checkpoint_completion_target) + 2 * checkpoint_segments + 1 + 1
这就是在日志大小达到稳定状态时,所能达到的最大值。所谓“稳定状态”是指,一旦达到这个状态,优先使用预分配空间,一般不会增大;即使日志文件继续增加,也会被删除(如果archiver和wal sender都正常工作的话)。而日志大小也不会明显减少,因为处于预分配状态的日志数量、前一次检查点到当前时间点的日志量都没有大的变化。
回到我们的问题,PG的日志空间占用的正常值,可以用上面的公式计算出来。如果wal_keep_segments为80,checkpoint_segments为64,checkpoint_completion_target为0.9,那么根据公式计算结果为4.02G。即日志空间增加到4G也是正常的。并且可以通过减小checkpoint_segements的值,减少日志空间占用。
通过上面分析得出的公式,我们在处理日志时遇到的一些问题就迎刃而解了,例如:
Q: 增加wal_keep_segments会增大日志空间吗?
A: 如果增加wal_keep_segments后,其值仍小于(checkpoint_segments + checkpoint_segments * checkpoint_completion_target),则增加wal_keep_segments并不会增大日志占用空间。
Q: checkpoint_segments与日志空间大小有什么关系?
A: 在wal_keep_segments较小时,checkpoint_segments对日志空间占用有至关重要的影响。日志空间大小基本上可以用4倍checkpoint_segments来估算出来。但当wal_keep_segments较大时,比如是checkpoint_segments的10倍,则checkpoint_segments对日志空间大小的影响相对就小很多了。
上面的分析中,我们做了两点假设。一个是系统中有足够多的旧日志可供回收,这种情况会出现吗(提示:archiver进程或replication slot对日志删除的影响)?另一个是,检查点操作会及时完成,那么如果检查点操作未及时完成,会出现什么情况?会导致日志空间占用比我们的公式更大吗?
参考:
http://mysql.taobao.org/monthly/2015/06/08/
注:
1、XLOGfileslop:预分配wal文件数量,为:2*checkpoint_segments + 1
2、最后的两个思考题,还未想出答案,想出最写篇博客。
标签:
原文地址:http://www.cnblogs.com/xiaotengyi/p/4641879.html