标签:
学习 Neutron 系列文章:
(2)Neutron OpenvSwitch + VLAN 虚拟网络
(3)Neutron OpenvSwitch + GRE/VxLAN 虚拟网络
(4)Neutron OVS OpenFlow 流表 和 L2 Population
(5)TBD
OVS bridge 有两种模式:“normal” 和 “flow”。“normal” 模式的 bridge 同普通的 Linux 桥,而 “flow” 模式的 bridge 是根据其流表(flow tables) 来进行转发的。Neutron 使用两种 OVS bridge:br-int 和 br-tun。其中,br-int 是一个 “normal” 模式的虚拟网桥,而 br-tun 是 “flow” 模式的,它比 br-int 复杂得多。
下面左图是 Open vSwitch 中流表的结构。右图这个流程图详细描述了数据包流通过一个 OpenFlow 交换机的过程。
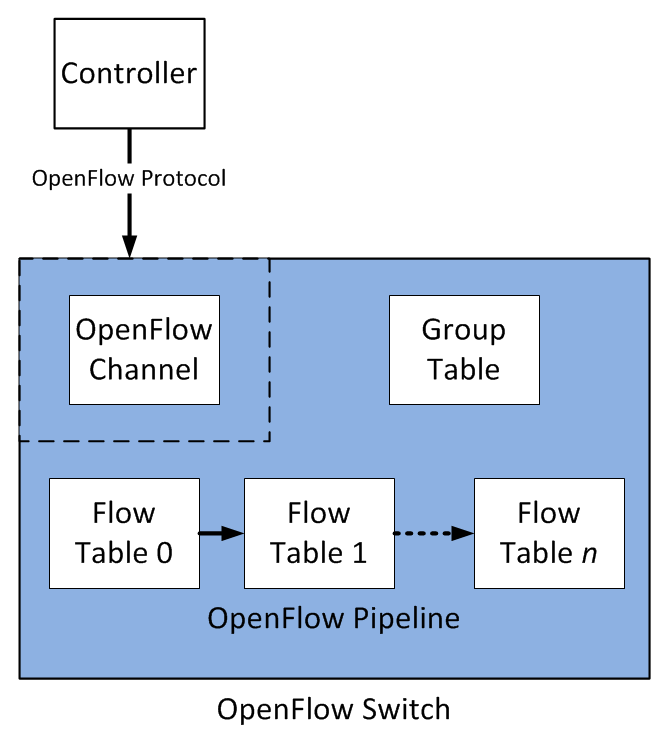

更详细的描述请参见这里。
Proxy ARP 就是通过一个主机(通常是Router)来作为指定的设备对另一个设备作出 ARP 的请求进行应答。
最主要的一个优点就是能够在不影响其他router的路由表的情况下在网络上添加一个新的router,这样使得子网的变化对主机是透明的。
proxy ARP应该使用在主机没有配置默认网关或没有任何路由策略的网络上
缺点:
1.增加了某一网段上 ARP 流量
2.主机需要更大的 ARP table 来处理IP地址到MAC地址的映射
3.安全问题,比如 ARP 欺骗(spoofing)
4.不会为不使用 ARP 来解析地址的网络工作
5.不能够概括和推广网络拓扑
来源:百度百科
OpenStack 中,Neutron 作为 OVS 的 Controller,向 OVS 发出管理 tunnel port 的指令,以及提供流表。
Neutron 定义了多种流表。以下面的配置(配置了 GRE 和 VXLAN 两种 tunnel types)为例:
1(patch-int): addr:a6:d4:dd:37:00:52 2(vxlan-0a000127): addr:36:ec:de:b4:b9:6b {in_key=flow, local_ip="10.0.1.31", out_key=flow, remote_ip="10.0.1.39"} 计算节点2 3(vxlan-0a000115): addr:4a:c8:21:3c:3f:f1 {in_key=flow, local_ip="10.0.1.31", out_key=flow, remote_ip="10.0.1.21"} 网络节点 4(gre-0a000115): addr:4a:8b:0f:9d:59:52 {in_key=flow, local_ip="10.0.1.31", out_key=flow, remote_ip="10.0.1.21"} 网络节点 5(gre-0a000127): addr:aa:58:6d:0a:f7:6a {in_key=flow, local_ip="10.0.1.31", out_key=flow, remote_ip="10.0.1.39"} 计算节点2
其中,10.0.1.31 是计算节点1, 10.0.1.21 是计算节点2, 10.0.1.39 是网络节点。
计算节点1 上 ML2 Agent 启动后的 br-tun 的 flows:
| 表号 | 用途 | 例子 |
| 0 |
table=0, priority=1,in_port=3 actions=resubmit(,4) //从网络节点来的,转 4,结果被丢弃 table=0, priority=1,in_port=4 actions=resubmit(,3) //从网络节点来的,转 3
table=0, priority=1,in_port=2 actions=resubmit(,4) //从计算节点来的,转 4,结果被丢弃 table=0, priority=1,in_port=1 actions=resubmit(,2) //从虚机来的,转 2 |
|
| DVR_PROCESS = 1 | handle packets coming from patch_int unicasts go to table UCAST_TO_TUN where remote addresses are learnt | 用于 DVR |
| PATCH_LV_TO_TUN = 2 |
table=2, priority=0,dl_dst=00:00:00:00:00:00/01:00:00:00:00:00 actions=resubmit(,20) //单播,转 20 |
|
| GRE_TUN_TO_LV = 3 |
table=3, priority=1,tun_id=0x4 actions=mod_vlan_vid:1,resubmit(,10) //将 tun_id 为 4 的,修改 vlan id 为1,转 10 处理 |
|
| VXLAN_TUN_TO_LV = 4 | table=4, priority=0 actions=drop //丢弃 | |
| DVR_NOT_LEARN = 9 | 用于 DVR | |
| LEARN_FROM_TUN = 10 | 学习table |
table=10,priority=1 actions=learn(table=20,hard_timeout=300,priority=1,NXM_OF_VLAN_TCI[0..11],NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],load:0->NXM_OF_VLAN_TCI[],load:NXM_NX_TUN_ID[]->NXM_NX_TUN_ID[],output:NXM_OF_IN_PORT[]),output:1 |
| UCAST_TO_TUN = 20 |
外出的单播会被 table 20 处理,table 2 |
//学习到的规则 table=20, priority=2,dl_vlan=1,dl_dst=fa:16:3e:7e:ab:cc actions=strip_vlan,set_tunnel:0x3e9,output:5 //如果vlan 为1,而且目的MAC地址等于 fa:16:3e:7e:ab:cc,设置 tunnel id,从端口 5 发出
table=20,priority=0 actions=resubmit(,22) //直接转 22 |
| ARP_RESPONDER = 21 | ARP table | 当使用 arp_responder 和 l2population 时候用到 |
| FLOOD_TO_TUN = 22 | Flood table |
table=22,dl_vlan=1 actions=strip_vlan,set_tunnel:0x4,output:5,output:4 //对于 dl_vlan 为1的,设置 tunnel id 为 4,从端口4 和 5 转出 |
来个图简单些:
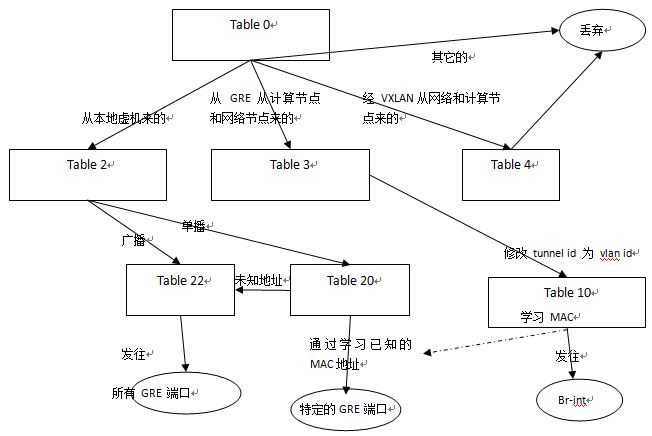
其中比较有意思的是:
(1)为什么从 VXLAN 过来的流量都被丢弃了,最后发出去也用的是 GRE 端口。看来同时有 GRE 和 VXLAN 隧道的话,OVS 只会选择 GRE。具体原因待查。
(2)MAC 地址学习:Table 10 会将学习到的规则(Local VLAN id + Dst MAC Addr => Port)放到 table 20。当表格20 发现一个单播地址是已知的时候,直接从一个特定的 GRE 端口发出;未知的话,视同组播地址从所有 GRE 端口发出。
学习规则:
table=20,hard_timeout=300,priority=1,NXM_OF_VLAN_TCI[0..11],NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[],load:0->NXM_OF_VLAN_TCI[],load:NXM_NX_TUN_ID[]->NXM_NX_TUN_ID[],output:NXM_OF_IN_PORT[]
这语法不是很好理解,这里 有详细解释。
NXM_OF_VLAN_TCI[0..11] :记录 vlan tag,所以学习结果中有 dl_vlan=1
NXM_OF_ETH_DST[]=NXM_OF_ETH_SRC[] :将 mac source address 记录,所以结果中有 dl_dst=fa:16:3e:7e:ab:cc
load:0->NXM_OF_VLAN_TCI[]:在发送出去的时候,vlan tag设为0,所以结果中有 actions=strip_vlan
load:NXM_NX_TUN_ID[]->NXM_NX_TUN_ID[] :发出去的时候,设置 tunnul id,所以结果中有set_tunnel:0x3e9
output:NXM_OF_IN_PORT[]:指定发送给哪个port,由于是从 port2 进来的,因而结果中有output:2。
学到的规则:
table=20, n_packets=1239, n_bytes=83620, idle_age=735, hard_age=65534, priority=2,dl_vlan=1,dl_dst=fa:16:3e:7e:ab:cc actions=strip_vlan,set_tunnel:0x3e9,output:2
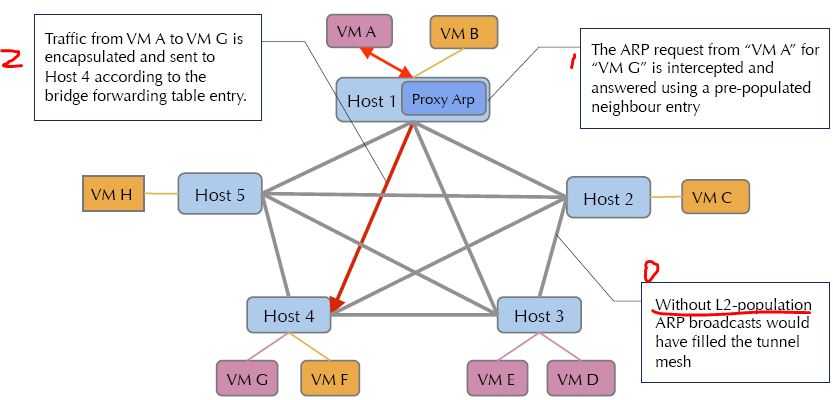
这里可以看到,通过 MAC 地址学习机制,Neutron 可以一定程度地优化网络流向,但是这种机制需要等待从别的节点的流量进来,只能算是一种被动的机制,效率不高。而且,这种机制只对单播帧有效,而对于多播和组播依然无效。其结果是网络成本依然很高。下图中,A 的广播包其实只对 3 和 4 有用,但是 2 和 5 也收到了。

arp_responder 的原理不复杂。Neutorn DB 中保存了所有的端口的 MAC 和 IP 地址数据。而 ARP 就是一个虚机要根据另一个虚机的 IP 地址查询它的 MAC。因此,只需要 Neutron server 通过 RPC 告诉每个计算节点上的 ML2 agent 所有活动端口的 MAC 和 IP,那么就可以将 br-tun 变成一个供本机适用的 ARP Proxy,这样本机上的虚机的 ARP 请求的响应就可以由 br-tun 在本地解决。Assaf Meller 有篇文章来阐述 ARP Responder。
使用 ARP Responder 需要满足两个条件:
(1)设置 arp_responder = true 来使用 OVS 的ARP 处理能力 。这需要 OVS 2.1 (运行 ovs-vswitchd --version 来查看 OVS 版本) 和 ML2 l2population 驱动的支持。当使用隧道方式的时候,OVS 可以处理一个 ARP 请求而不是使用广播机制。如果 OVS 版本不够的话,Neutorn 是无法设置 arp responder entry 的,你会在 openvswitch agent 日志中看到 “Stderr: ‘2015-07-11T04:57:32Z|00001|meta_flow|WARN|destination field arp_op is not writable\novs-ofctl: -:2: actions are invalid with specified match (OFPBAC_BAD_SET_ARGUMENT)\n‘”这样的错误,你也就不会在 ”ovs-ofctl dump-flows br-tun“ 命令的输出中看到相应的 ARP Responder 条目了。
(2)设置 l2_population = true。同时添加 mechanism_drivers = openvswitch,l2population。OVS 需要 Neutron 作为 SDN Controller 向其输入 ARP Table flows。
杀掉 neutron openvswitch, ovs-* 各种进程
#编译安装
去 http://openvswitch.org/download/ 下载最新版本的代码,解压,进入解压后的目录
安装依赖包,比如 gcc,make
uname -r
./configure --with-linux=/lib/modules/3.13.0-51-generic/build
make && make install
#查看安装的版本
root@compute2:/home/s1# ovs-vsctl --version
ovs-vsctl (Open vSwitch) 2.3.2
Compiled Jul 12 2015 09:09:42
DB Schema 7.6.2
#处理 db
rm /etc/openvswitch/conf.db (老的db要删除掉,否则会报错)
ovsdb-tool create /etc/openvswitch/conf.db vswitchd/vswitch.ovsschema
#启动 ovs
cp /usr/local/bin/ovs-* /usr/bin
ovsdb-server /etc/openvswitch/conf.db -vconsole:emer -vsyslog:err -vfile:info --remote=punix:/usr/local/var/run/openvswitch/db.sock --private-key=db:Open_vSwitch,SSL,private_key --certificate=db:Open_vSwitch,SSL,certificate --bootstrap-ca-cert=db:Open_vSwitch,SSL,ca_cert --no-chdir --log-file=/var/log/openvswitch/ovsdb-server.log --pidfile=/var/run/openvswitch/ovsdb-server.pid --detach --monitor
ovs-vswitchd unix:/usr/local/var/run/openvswitch/db.sock -vconsole:emer -vsyslog:err -vfile:info --mlockall --no-chdir --log-file=/var/log/openvswitch/ovs-vswitchd.log --pidfile=/var/run/openvswitch/ovs-vswitchd.pid --detach --monitor
#启动 neutron openvswitch agent,确保log 文件中 ovs-vsctl 和 ovs-ofctl 调用没有错误
#修改 /usr/share/openvswitch/scripts/ovs-lib 文件,保证机器重启后 OVS 正常运行
将 rundir=${OVS_RUNDIR-‘/var/run/openvswitch‘} 改为 rundir=${OVS_RUNDIR-‘/usr/local/var/run/openvswitch‘}
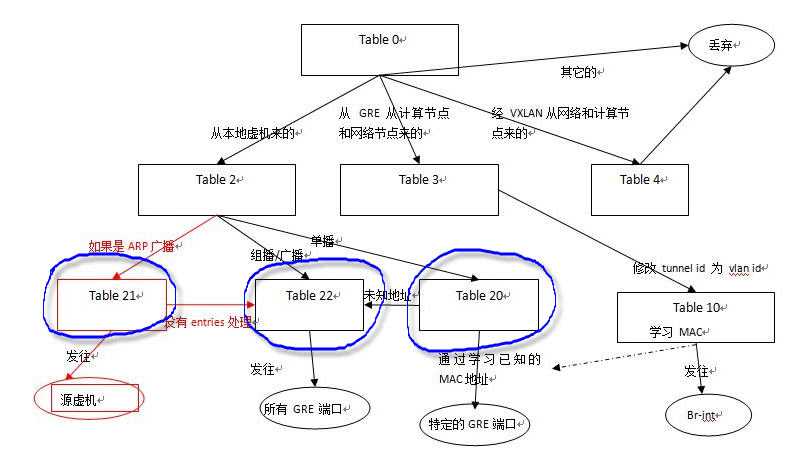
有了 arp_responder 以后,br-tun 的流表增加了几项和处理:
(1)table 2 中增加一条 flow,是的从本地虚机来的 ARP 广播帧转到table 21
# ARP broadcast-ed request go to the local ARP_RESPONDER table to be locally resolved
table=2, n_packets=0, n_bytes=0, idle_age=3, priority=1,arp,dl_dst=ff:ff:ff:ff:ff:ff actions=resubmit(,21)
(2)在 table 21 中增加一条 flow 将其发发往 table 22
# If none of the ARP entries correspond to the requested IP, the broadcast-ed packet is resubmitted to the flooding table
table=21, n_packets=0, n_bytes=0, idle_age=4, priority=0 actions=resubmit(,22)
如果下面第 (3)步增加的 flow rule 都处理不了这条 request,那么转到table 22 去 flood 到所有端口。
(3)由 L2 population 发来的 entry 来更新 table 21。
table 21 是在新的 l2pop 地址进来的时候更新的。比如说,compute C 上增加了新的虚机 VM3,然后计算节点 A 和 B 收到一条 l2pop 消息说 VM3 (IP 是***,MAC 是 ***) 在 Host C 上,在 network "Z“ 中。然后,Compute A 和 B 会在 table 21 中增加相应的 flows。
br.add_flow(table=21, priority=1, proto=‘arp‘, dl_vlan=local_vid, nw_dst= ip, actions=actions)
其中action为: (好晦涩,这是谁定义的奇葩语法。。幸好 这里 有详细解释)
ARP_RESPONDER_ACTIONS = (‘move:NXM_OF_ETH_SRC[]->NXM_OF_ETH_DST[],‘
‘mod_dl_src:%(mac)s,‘
‘load:0x2->NXM_OF_ARP_OP[],‘
‘move:NXM_NX_ARP_SHA[]->NXM_NX_ARP_THA[],‘
‘move:NXM_OF_ARP_SPA[]->NXM_OF_ARP_TPA[],‘
‘load:%(mac)#x->NXM_NX_ARP_SHA[],‘
‘load:%(ip)#x->NXM_OF_ARP_SPA[],‘
‘in_port‘)
(4)table 21 的处理过程
table 21 中的每一条 flow,会和进来的帧的数据做匹配(ARP 协议,network,虚机的 IP)。如果匹配成功,则构造一个 ARP 响应包,其中包括了 IP 和 MAC,从原来的 port 发回到虚机。如果没有吻合的,那么转发到 table 22 做泛洪。
增加的 flow tables 在红色部分:
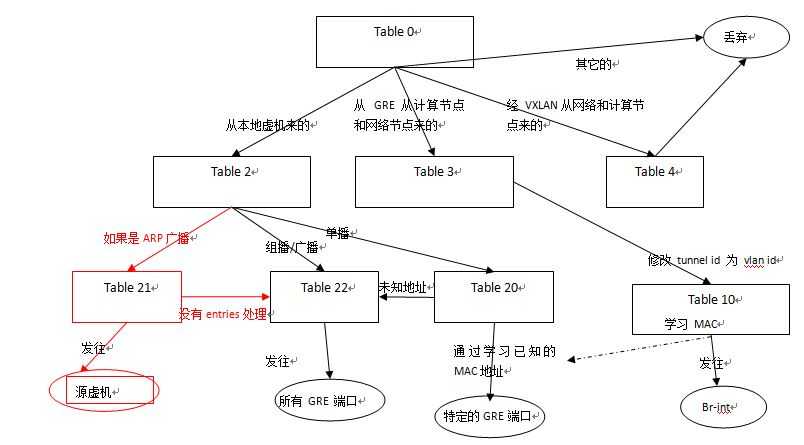
因此,通过使用 l2-pop mechanism driver 和 OVS 2.1, Neutorn 可以在本地回答虚机的 ARP 请求,从而避免了昂贵的 ARP 广播。这个功能给 GRE 和 VXLAN 的实现是在 Juno 版本中完成的。 这个 blueprint 似乎在支持VLAN 中的这个功能,但是看起来没有完成。
根据这篇文档,l2pop 目前支持 VXLAN with Linux bridge 和 GRE/VXLAN with OVS,其 blueprint 在这里。
l2pop 的原理也不复杂。Neutron 中保存每一个端口的状态,而端口保存了网络相关的数据。虚机启动过程中,其端口状态会从 down 到build 到 active。因此,在每次端口发生状态变化时,函数 update_port_postcommit 都将会被调用:
{‘status‘: ‘DOWN/BUILD/ACTIVE‘, ‘binding:host_id‘: u‘compute1‘, ‘allowed_address_pairs‘: [], ‘extra_dhcp_opts‘: [], ‘device_owner‘: u‘compute:nova‘, ‘binding:profile‘: {}, ‘fixed_ips‘: [{‘subnet_id‘: u‘4ec65731-35a5-4637-a59b-a9f2932099f1‘, ‘ip_address‘: u‘81.1.180.15‘}], ‘id‘: u‘1167e9ac-e10f-4cf5-bd09-6649eab38b32‘, ‘security_groups‘: [u‘f5377a66-803d-481b-b4c3-a6631e8ab456‘], ‘device_id‘: u‘30580ea7-c456-416b-a01e-0fe645edf5dc‘, ‘name‘: u‘‘, ‘admin_state_up‘: True, ‘network_id‘: u‘86c0d29b-4880-4739-bd68-eb3c392f5099‘, ‘tenant_id‘: u‘74c8ada23a3449f888d9e19b76d13aab‘, ‘binding:vif_details‘: {u‘port_filter‘: True, u‘ovs_hybrid_plug‘: True}, ‘binding:vnic_type‘: u‘normal‘, ‘binding:vif_type‘: u‘ovs‘, ‘mac_address‘: u‘fa:16:3e:4f:59:9d‘}
在某些状态变化下:
通过这种机制,每个节点上的如下数据得到了实时更新,从而避免了不必要的隧道连接和广播。
有和没有 l2pop 的效果:
1. def tunnel_sync(self) 函数除了上报自己的 local_ip 外不再自己见 tunnels,一切等 l2pop 的通知。
2. 在 compute1 上添加第一个虚机 81.1.180.8
neutron-server:
compute1:
compute 2 节点:因为它上面还没有运行虚机,所以不做操作。
3. 在 compute 2 上添加一个虚机 81.1.180.9
neutron server:
compute1:
compute2:
增加 ARP flow(新虚机的网关的 MAC -> IP) table=21, n_packets=0, n_bytes=0, idle_age=268, priority=1,arp,dl_vlan=2,arp_tpa=81.1.180.1 actions=move:NXM_OF_ETH_SRC[]->NXM_OF_ETH_DST[],mod_dl_src:fa:16:3e:87:40:f3,load:0x2->NXM_OF_ARP_OP[],move:NXM_NX_ARP_SHA[]->NXM_NX_ARP_THA[],move:NXM_OF_ARP_SPA[]->NXM_OF_ARP_TPA[],load:0xfa163e8740f3->NXM_NX_ARP_SHA[],load:0x5101b401->NXM_OF_ARP_SPA[],IN_PORT
3. 删除 compute1 上的一个vm(也是唯一的一个)
neutron server:
compute 1:
compute 2:
4. 在 compute1 上创建第一个不同网络的虚机
neutron server:
compute 1:建立和网络节点的 tunnel port;更新 Flood flows;添加 ARP flows
compute 2:没什么action,因为该节点上没有新建虚机的网络内的虚机
过程的大概说明:
应该说 l2pop 的原理和实现都很直接,但是在大规模部署环境中,这种通知机制(通知所有的 ML2 Agent 节点)可能会给 MQ 造成很大的负担。一旦 MQ 不能及时处理消息,虚机之间的网络将受到影响。下面是 l2pop 中通知机制代码:
def __init__(self, topic=topics.AGENT): super(L2populationAgentNotifyAPI, self).__init__( topic=topic, default_version=self.BASE_RPC_API_VERSION) self.topic_l2pop_update = topics.get_topic_name(topic, topics.L2POPULATION, topics.UPDATE) def _notification_fanout(self, context, method, fdb_entries): self.fanout_cast(context, self.make_msg(method, fdb_entries=fdb_entries), topic=self.topic_l2pop_update) def _notification_host(self, context, method, fdb_entries, host): self.cast(context, self.make_msg(method, fdb_entries=fdb_entries), topic=‘%s.%s‘ % (self.topic_l2pop_update, host)) def add_fdb_entries(self, context, fdb_entries, host=None): if fdb_entries: if host: self._notification_host(context, ‘add_fdb_entries‘,fdb_entries, host) #cast 给指定 host else: self._notification_fanout(context, ‘add_fdb_entries‘, fdb_entries) #fanout 给所有计算和网络节点
这段代码是说,l2pop 采用的 MQ topic 是 “L2POPULATION”,消息通知采用 fanout 或者 cast 机制。如果是 fanout 的话,消息将发到所有的 ML2 agent 节点。这样的话,其覆盖面就有些过于广泛了,就这个问题有人提了一个 ticket,官方答复是 work as design,要改的话只能是添加 new feature 了。
不知道这个数目有没有上限?数目很多的情况下会不会有性能问题?OVS 有没有处理能力上限?这些问题也许得在实际的生产环境中才能得到证实和答案。
标签:
原文地址:http://www.cnblogs.com/sammyliu/p/4633814.html