标签:
iptables ebtables arptables
iptables ebtables arptables这些用户层的工具会调用setsockopt/getsockopt来和内核通信

nf_sockopts是在iptables进行初始化时通过nf_register_sockopt()函数生成的一个struct nf_sockopt_ops结构
对于ipv4来说,在net/ipv4/netfilter/ip_tables.c中定义了一个ipt_sockopts变量(struct nf_sockopt_ops),其中的set操作指定为do_ipt_set_ctl(),因此,当nf_sockopt()调用对应的set操作时,控制将转入net/ipv4/netfilter/ip_tables.c::do_ipt_set_ctl()中。
对于IPT_SO_SET_REPLACE命令,do_ipt_set_ctl()调用do_replace()来处理,该函数将用户层传入的struct ipt_replace和struct ipt_entry组织到filter(根据struct ipt_replace::name项)表的hook_entry[NF_IP_FORWARD]所指向的区域,如果是添加规则,结果将是filter表的private(struct ipt_table_info)项的hook_entry[NF_IP_FORWARD]和underflow[NF_IP_FORWARD]的差值扩大(用于容纳该规则),private->number加1。
内核版本:3.18.14
结构体struct nf_sockopt_ops
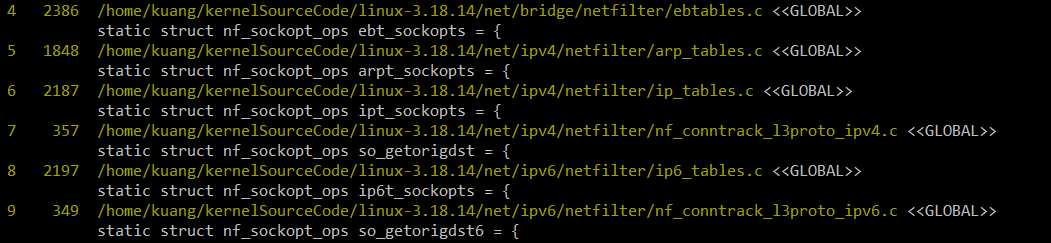
把nf_sockopt_ops注册到全局的链表中(以ipt_sockopts为例)
static int __init ip_tables_init(void) { int ret; ret = register_pernet_subsys(&ip_tables_net_ops); if (ret < 0) goto err1; /* No one else will be downing sem now, so we won‘t sleep */ ret = xt_register_targets(ipt_builtin_tg, ARRAY_SIZE(ipt_builtin_tg)); if (ret < 0) goto err2; ret = xt_register_matches(ipt_builtin_mt, ARRAY_SIZE(ipt_builtin_mt)); if (ret < 0) goto err4; /* Register setsockopt */ ret = nf_register_sockopt(&ipt_sockopts); if (ret < 0) goto err5; pr_info("(C) 2000-2006 Netfilter Core Team\n"); return 0; err5: xt_unregister_matches(ipt_builtin_mt, ARRAY_SIZE(ipt_builtin_mt)); err4: xt_unregister_targets(ipt_builtin_tg, ARRAY_SIZE(ipt_builtin_tg)); err2: unregister_pernet_subsys(&ip_tables_net_ops); err1: return ret; }
struct ipt_sockopts定义:
static struct nf_sockopt_ops ipt_sockopts = { .pf = PF_INET, .set_optmin = IPT_BASE_CTL, .set_optmax = IPT_SO_SET_MAX+1, .set = do_ipt_set_ctl, #ifdef CONFIG_COMPAT .compat_set = compat_do_ipt_set_ctl, #endif .get_optmin = IPT_BASE_CTL, .get_optmax = IPT_SO_GET_MAX+1, .get = do_ipt_get_ctl, #ifdef CONFIG_COMPAT .compat_get = compat_do_ipt_get_ctl, #endif .owner = THIS_MODULE, };
对于IPT_SO_SET_REPLACE命令,do_ipt_set_ctl()调用do_replace()来处理,该函数将用户层传入的struct ipt_replace和struct ipt_entry组织到filter(根据struct ipt_replace::name项)表的hook_entry[NF_IP_FORWARD]所指向的区域,如果是添加规则,结果将是filter表的private(struct ipt_table_info)项的hook_entry[NF_IP_FORWARD]和underflow[NF_IP_FORWARD]的差值扩大(用于容纳该规则),private->number加1。
在内核文件net/ipv4/netfilter/iptable_filter.c中:
static int __net_init iptable_filter_net_init(struct net *net) { struct ipt_replace *repl; repl = ipt_alloc_initial_table(&packet_filter); if (repl == NULL) return -ENOMEM; /* Entry 1 is the FORWARD hook */ ((struct ipt_standard *)repl->entries)[1].target.verdict = forward ? -NF_ACCEPT - 1 : -NF_DROP - 1; net->ipv4.iptable_filter = ipt_register_table(net, &packet_filter, repl); kfree(repl); return PTR_ERR_OR_ZERO(net->ipv4.iptable_filter); } ... static struct pernet_operations iptable_filter_net_ops = { .init = iptable_filter_net_init, .exit = iptable_filter_net_exit, }; static int __init iptable_filter_init(void) { int ret; ret = register_pernet_subsys(&iptable_filter_net_ops); if (ret < 0) return ret; /* Register hooks */ filter_ops = xt_hook_link(&packet_filter, iptable_filter_hook); if (IS_ERR(filter_ops)) { ret = PTR_ERR(filter_ops); unregister_pernet_subsys(&iptable_filter_net_ops); } return ret; }
调用ipt_register_table注册了一个struct xt_table,那我们介绍一下struct xtable
/* Furniture shopping... */ struct xt_table { struct list_head list; /* What hooks you will enter on */ unsigned int valid_hooks; /* Man behind the curtain... */ struct xt_table_info *private; /* Set this to THIS_MODULE if you are a module, otherwise NULL */ struct module *me; u_int8_t af; /* address/protocol family */ int priority; /* hook order */ /* A unique name... */ const char name[XT_TABLE_MAXNAMELEN]; };
再看窗帘后面的男人: strcut xt_table_info
/* The table itself */ struct xt_table_info { /* Size per table */ unsigned int size; /* Number of entries: FIXME. --RR */ unsigned int number; /* Initial number of entries. Needed for module usage count */ unsigned int initial_entries; /* Entry points and underflows */ unsigned int hook_entry[NF_INET_NUMHOOKS]; unsigned int underflow[NF_INET_NUMHOOKS]; /* * Number of user chains. Since tables cannot have loops, at most * @stacksize jumps (number of user chains) can possibly be made. */ unsigned int stacksize; unsigned int __percpu *stackptr; void ***jumpstack; /* ipt_entry tables: one per CPU */ /* Note : this field MUST be the last one, see XT_TABLE_INFO_SZ */ void *entries[1]; };
刚刚说啥来着:setsockopt最后把用户配置的规则加在xt_table_info的hook_entry中...
回到上面出现的 xt_hook_link 函数
先看 packet_filter 的定义和 iptable_filter_hook 的定义
#define FILTER_VALID_HOOKS ((1 << NF_INET_LOCAL_IN) | \ (1 << NF_INET_FORWARD) | (1 << NF_INET_LOCAL_OUT)) static const struct xt_table packet_filter = { .name = "filter", .valid_hooks = FILTER_VALID_HOOKS, .me = THIS_MODULE, .af = NFPROTO_IPV4, .priority = NF_IP_PRI_FILTER, }; static unsigned int iptable_filter_hook(const struct nf_hook_ops *ops, struct sk_buff *skb, const struct net_device *in, const struct net_device *out, int (*okfn)(struct sk_buff *)) { const struct net *net; if (ops->hooknum == NF_INET_LOCAL_OUT && (skb->len < sizeof(struct iphdr) || ip_hdrlen(skb) < sizeof(struct iphdr))) /* root is playing with raw sockets. */ return NF_ACCEPT; net = dev_net((in != NULL) ? in : out); return ipt_do_table(skb, ops->hooknum, in, out, net->ipv4.iptable_filter); }
再看xt_hook_link函数的实现
/** * xt_hook_link - set up hooks for a new table * @table: table with metadata needed to set up hooks * @fn: Hook function * * This function will take care of creating and registering the necessary * Netfilter hooks for XT tables. */ struct nf_hook_ops *xt_hook_link(const struct xt_table *table, nf_hookfn *fn) { unsigned int hook_mask = table->valid_hooks; uint8_t i, num_hooks = hweight32(hook_mask); uint8_t hooknum; struct nf_hook_ops *ops; int ret; ops = kmalloc(sizeof(*ops) * num_hooks, GFP_KERNEL); if (ops == NULL) return ERR_PTR(-ENOMEM); for (i = 0, hooknum = 0; i < num_hooks && hook_mask != 0; hook_mask >>= 1, ++hooknum) { if (!(hook_mask & 1)) continue; ops[i].hook = fn; ops[i].owner = table->me; ops[i].pf = table->af; ops[i].hooknum = hooknum; ops[i].priority = table->priority; ++i; } ret = nf_register_hooks(ops, num_hooks); if (ret < 0) { kfree(ops); return ERR_PTR(ret); } return ops; }
是的,在这里调用了nf_register_hooks,注册了一堆hook,请关注这个filter表的NFPROTO_IPV4协议族中,注册点为:FILTER_VALID_HOOKS
也就是说在 FILTER_VALID_HOOKS 包含的三个HOOK点上都注册了同样的一个hook函数 ip_filter_hook
这个iptable_filter_hook最终调用 ipt_do_table
至于skb的处理怎么进入到这些hook函数,有很多高手写的很清楚,这里给个链接:
来看这个ipt_do_table
net/ipv4/netfilter/ip_tables.c文件中:
带着这个重点去看这个函数:struct xt_table结构体中有一个躲在窗帘后的男人
/* Returns one of the generic firewall policies, like NF_ACCEPT. */ unsigned int ipt_do_table(struct sk_buff *skb, unsigned int hook, const struct net_device *in, const struct net_device *out, struct xt_table *table) { static const char nulldevname[IFNAMSIZ] __attribute__((aligned(sizeof(long)))); const struct iphdr *ip; /* Initializing verdict to NF_DROP keeps gcc happy. */ unsigned int verdict = NF_DROP; const char *indev, *outdev; const void *table_base; struct ipt_entry *e, **jumpstack; unsigned int *stackptr, origptr, cpu; const struct xt_table_info *private; struct xt_action_param acpar; unsigned int addend; /* Initialization */ ip = ip_hdr(skb); indev = in ? in->name : nulldevname; outdev = out ? out->name : nulldevname; /* We handle fragments by dealing with the first fragment as * if it was a normal packet. All other fragments are treated * normally, except that they will NEVER match rules that ask * things we don‘t know, ie. tcp syn flag or ports). If the * rule is also a fragment-specific rule, non-fragments won‘t * match it. */ acpar.fragoff = ntohs(ip->frag_off) & IP_OFFSET; acpar.thoff = ip_hdrlen(skb); acpar.hotdrop = false; acpar.in = in; acpar.out = out; acpar.family = NFPROTO_IPV4; acpar.hooknum = hook; IP_NF_ASSERT(table->valid_hooks & (1 << hook)); local_bh_disable(); addend = xt_write_recseq_begin(); private = table->private; cpu = smp_processor_id(); /* * Ensure we load private-> members after we‘ve fetched the base * pointer. */ smp_read_barrier_depends(); table_base = private->entries[cpu]; jumpstack = (struct ipt_entry **)private->jumpstack[cpu]; stackptr = per_cpu_ptr(private->stackptr, cpu); origptr = *stackptr; e = get_entry(table_base, private->hook_entry[hook]); pr_debug("Entering %s(hook %u); sp at %u (UF %p)\n", table->name, hook, origptr, get_entry(table_base, private->underflow[hook])); do { const struct xt_entry_target *t; const struct xt_entry_match *ematch; IP_NF_ASSERT(e); if (!ip_packet_match(ip, indev, outdev, &e->ip, acpar.fragoff)) { no_match: e = ipt_next_entry(e); continue; } xt_ematch_foreach(ematch, e) { acpar.match = ematch->u.kernel.match; acpar.matchinfo = ematch->data; if (!acpar.match->match(skb, &acpar)) goto no_match; } ADD_COUNTER(e->counters, skb->len, 1); t = ipt_get_target(e); IP_NF_ASSERT(t->u.kernel.target); #if IS_ENABLED(CONFIG_NETFILTER_XT_TARGET_TRACE) /* The packet is traced: log it */ if (unlikely(skb->nf_trace)) trace_packet(skb, hook, in, out, table->name, private, e); #endif /* Standard target? */ if (!t->u.kernel.target->target) { int v; v = ((struct xt_standard_target *)t)->verdict; if (v < 0) { /* Pop from stack? */ if (v != XT_RETURN) { verdict = (unsigned int)(-v) - 1; break; } if (*stackptr <= origptr) { e = get_entry(table_base, private->underflow[hook]); pr_debug("Underflow (this is normal) " "to %p\n", e); } else { e = jumpstack[--*stackptr]; pr_debug("Pulled %p out from pos %u\n", e, *stackptr); e = ipt_next_entry(e); } continue; } if (table_base + v != ipt_next_entry(e) && !(e->ip.flags & IPT_F_GOTO)) { if (*stackptr >= private->stacksize) { verdict = NF_DROP; break; } jumpstack[(*stackptr)++] = e; pr_debug("Pushed %p into pos %u\n", e, *stackptr - 1); } e = get_entry(table_base, v); continue; } acpar.target = t->u.kernel.target; acpar.targinfo = t->data; verdict = t->u.kernel.target->target(skb, &acpar); /* Target might have changed stuff. */ ip = ip_hdr(skb); if (verdict == XT_CONTINUE) e = ipt_next_entry(e); else /* Verdict */ break; } while (!acpar.hotdrop); pr_debug("Exiting %s; resetting sp from %u to %u\n", __func__, *stackptr, origptr); *stackptr = origptr; xt_write_recseq_end(addend); local_bh_enable(); #ifdef DEBUG_ALLOW_ALL return NF_ACCEPT; #else if (acpar.hotdrop) return NF_DROP; else return verdict; #endif }
这里只是给出了大概的工作原理,细节都没有研究到,后续更新...
标签:
原文地址:http://www.cnblogs.com/xiaokuang/p/4642885.html