标签:
集合也叫作容器类。它的功能相当于一个容器。
Java的集合(容器),它是用来”装对象的“。

Set集合
Set集合几乎等同于Collection集合。它们的行为几乎一致。
遍历Set的两种方式:
1.用迭代器
2.用foreach循环
HashSet
HashSet的存储机制:
1、当有元素加进来的时,HashSet会调用该对象的hashCode()方法,得到一个int值。
2、根据hashCode的()返回的int值,计算出它在HashSet中的存储位置(底层实际采用数组存储元素的索引,计算得到在数组中的索引值)
3、如果加入的位置为空,则直接加入,如果该位置已经有元素,则此处会形成链表。
取元素时与此类似。
1、当要去一个元素时,HashSet会调用该对象的hashCode()方法,得到一个int值。
2、根据hashCode的()返回的int值,计算出它在HashSet的【底层数组】中的存储位置(数组中的索引)。
3、如果该位置恰好是要找的元素,直接取出即可,如如果该位置由链表,则要通过”挨个“搜索链表中的元素。
HashSet的构造方法:HashSet(int initialCapacity, float loadFactor)
initialCapacity:控制底层数组的长度,默认为16
loadFactor:负载因子,HashSet判断是否【底层数组快满】时的依据。当判断认为数组快满时,系统会自动创建一个长度为原来2倍的数组,并且将原来数组的元素复制到新数组,原来的数组成为了垃圾。专业术语叫做”rehash(重hash)“。
loadFactor的默认大小为0.75。
loadFactor越小,越消耗内存,loadFactor越大,性能越低。
hashSet怎样判断两个对象是否相等:
1、两个对象的hashCode()返回值相同
2、两个对象的equals()方法比较返回值为true
这就要求我们自定义类的hashCode()和equals()方法是一致的,要求重写equals()所用的关键属性与计算hashCode()的关键属性一致。
HashSet的子类:LinkedHashSet
它与HashSet的存储机制相同。
但LinkedHashSet额外维护一个链表,用来记录元素的添加顺序。
TreeSet
特征:保证Set里的元素是”有大小排序“的。
TreeSet————它是标准的红黑树
树—>二叉树—>排序二叉树—>平衡二叉树—>红黑树。
TreeSet的存储机制:
底层由一棵”红黑树“存放所有的数据。存取性能与检索性能也比较好。
在HashSet没有出现大量的链表的情况下,HashSet的性能要比TreeSet性能好。
TreeSet要求对象必须是可以排序的:
1、自然排序。要求所有的集合元素实现Comparable接口。
集合元素实现了Comparable接口后,集合元素自身就可以排序。
2、定制排序。要求创建TreeSet对象的时候传入一个Comparator对象。
Comparator对象负责对集合元素进行排序,集合元素无需实现Comparable接口。
TreeSet怎样才算两个对象时相等?
1、只有两个对象通过compareTo()方法比较的返回值为0,TreeSet才认为两个对象相等。
List集合
List集合封装了线性表的数据结构。
它提供大量的”根据索引“来存、取元素的方法。
由于List根据索引来存、取元素,因此它多了一个遍历元素的方法。
ArrayList与Vector的存储机制:
它们的底层是基于数组的,它们对元素的存储完全是基于数组的。 —— 因此性能非常快。
ArrayList与Vector的区别:
1、Vector是JDK1.0就有的集合,从JDK1.2以后SUN公司重新设计了ArrayList来代替Vector。
2、Vector是线程安全的,ArrayList是线程不安全的。但ArrayList的性能要比Vector的好。
即使在多线程的环境下,可以使用Collections的方法把ArrayList变成线程安全的。
LinkedList
既是线性表,又是队列,还是栈。(栈和队列是受限的线性表)。
LinkedList的底层是基于链表实现的。通常认为它的性能比不上ArrayList。
ArrayList:由于根据底层数组的索引存取元素的,所以性能非常快。
当插入、删除元素时,后面所有的元素都要跟上”整体搬家“。
LinkedList:由于底层采用链表来存储元素,要根据遍历来存取元素,所以性能较低。
当插入、删除元素时,后面所有的元素无需”整体搬家“,因此性能非常好。
Map集合
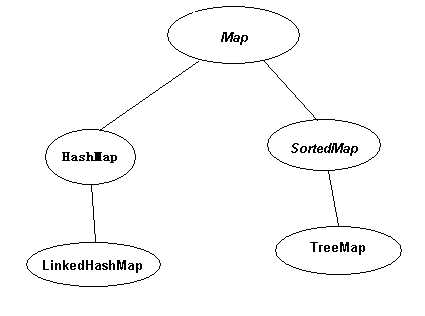
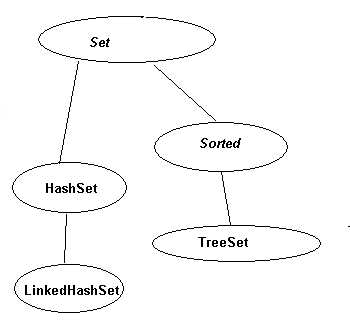
对比以上两图,发现二者的结构非常相识,Map与Set一一对应。实质上Set底层的实现就是通过Map子类的方法,可以通过查看Set相关的API文档验证。当Map的value值为null,只考虑key的时候,Map就变为了Set。
HashSet底层是由HashMap实现,HashMap通过“hash”算法控制数据在集合中的存储,类似于“一个萝卜一个坑”。
TreeSet底层是由TreeMap实现,TreeMap就是真正的红黑树。
注:对于Map而言,value只是它的附属物,几乎没有什么要求,因此Map主要是对key由要求。
HashMap
HashMap会通过key的hashCode()方法的返回值来计算其存、取位置。
HashMap怎样才算两个key重复呢?
1、通过equals()方法比较的返回值为true
2、两个key的hashCode()返回值相同
TreeMap
底层的红黑树只对key进行排序
TreeMap要求key必须是可以排序的:
1、自然排序。要求所有的key实现Comparable接口。
2、定制排序。要求创建TreeMap对象的时候传入一个Comparator接口的对象。
TreeMap怎样才算两个key相等?
1、通过compareTo()方法比较的返回值为0,这就表明两个元素相等。

HashMap与HashTable的区别:
1、HashTable是从JDK1.0就有的,尽量少用。
2、HashTable不允许null作为key、value。但HashMap允许。
3、HashTable是线程安全的(实现的不好)
HashMap是线程不安全的。HashMap的性能好。
除此以为HashMap与HashTable几乎是相同的。
标签:
原文地址:http://www.cnblogs.com/changyaohua/p/4649299.html