标签:
登录mysql服务器:mysql -h localhost -u root -p
查看有那些数据库:show databases;
创建数据库:create database 数据库名称;
删除数据库:drop database 数据库名称;
查看数据库引擎: show engines;
Engine 引擎名称 support 是否支持这个引擎
Comment对引擎的评论 transactions是否支持事件处理
Xa表示分布交易处理的xa规规范
存储引擎包括:myisam memory innodb(默认的引擎) archive mrg_myisam
查看是否支持存储引擎:show variables like ‘have%‘;
DISABLED表示支持但没有开启
查询默认引擎:show variables like ‘have_compress‘;
查看数据的创建语句:
Show create database 表名;
Use 数据库名; 选择数据库名
查看有那些表:show tables [表名]
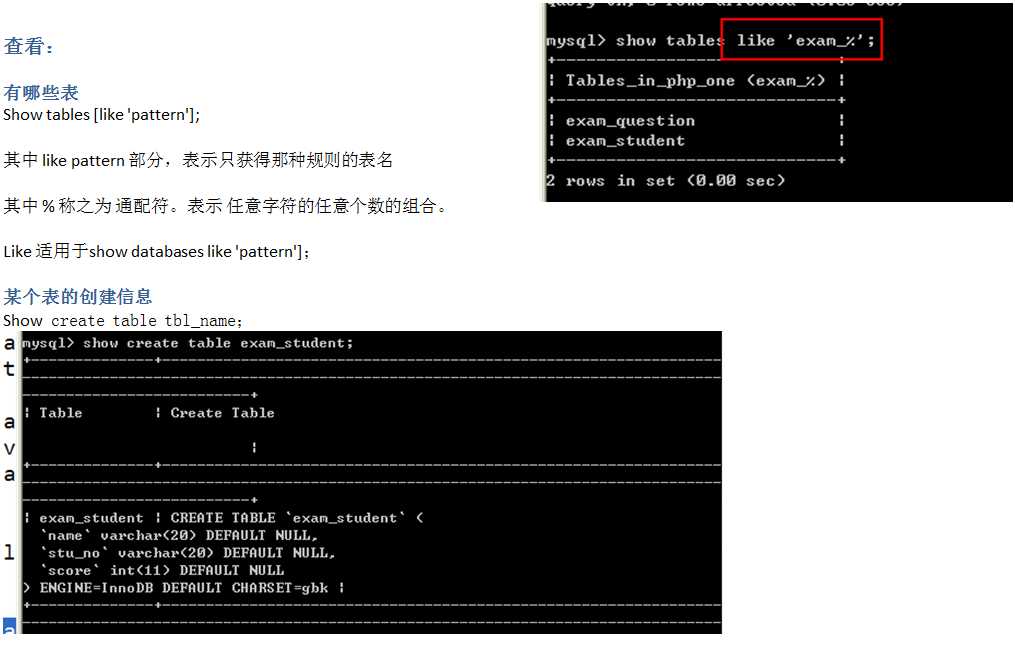
可以使用\ G 作为语句结束符。
查看表结构(描述表结构):
Describe tbl_name;
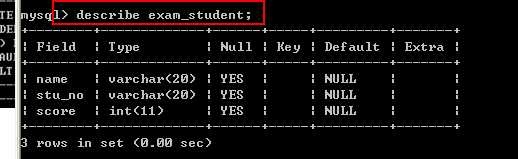
简写 是 desc tbl_name;

删除表:
drop table [if exists] tbl_name;
创建表语法
Create table 表名(属性名1 数据类型[完整性约束条件]....);
注意:在创建数据库表时,要先选择数据库名,如果没有选择,就出现语法错误
1:设置表的主键(<唯一>标识该表的每条信息)
1:单表段主键
语法:属性名 数据类型 primary key
例子:create table example1(stu_id int primary key,
stu_name varchar(20),
stu_sex boolean);
2:多字段主键
语法:属性名 数据类型 primary key(属性名1,属性名2,。。。。属性名n)
例子:
create table exampel2(stu_id int,
course_id int,
grade float,
sex boolean,
primary key(stu_id,sex,grade));
设置表外键
说明:当字典n是一个表a的属性,且依赖表b的主键,那么b是父表,a是子表,n是表a的外键
原则:必须依赖于数据库中已存在父表的主键:外键可以为空
作用:建立该表与其父表的关联关系,父表中信息发现变化时,子表中也会发现变化
语法如下:
Constraint 外键别名 foreign key(属性名1.1,属性名1.2,,,,,属性1.n)
References 表名(属性2.1,属性2.2,...属性2.n)
例子:
create table example3(id int primary key,
stu_id int,
course_id int,
constraint c_fk foreign key(stu_id)
references exampel2(stu_id));
注意:子表的外键关联必须是父表的主键,而且数据类型必须一致
设置表的非空约束(该字段不能为空,当插入新数据时,如果数据为空,系统出现错误)
语法:属性名 数据类型 not null
create table example4(id int not null primary key,
name varchar(20) not null,
stu_id int,
constraint d_fk foreign key(stu_id)
references example1(stu_id));
设置表的唯一性约束(该字段的值不能重复出现,是指在创建表时,为表的某些特殊字段unique约束字段),特点是保证该字段不能重复出现
语法:属性名 数据类型 unique
例子:create table example5(id int primary key,
stu_id int unique,
name varchar(20) not null);
设置表的属性值自动增加
语法 属性名 数据类型 auto_increment
例子:create table example6(id int primary key auto_increment,
stu_id int unique,
name varchar(20) not null);
设置表的属性默认值
语法:性名 数据类型 default 默认值
例子:
create table example7(id int primary key auto_increment,
stu_id int unique,
name varchar(20) not null,
year1 char(20) default ‘1990‘,
math float default 0
);
查看表结构
语法:describe 表名;
例子:describe example7;
+--------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| stu_id | int(11) | YES | UNI | NULL | |
| name | varchar(20) | NO | | NULL | |
| year1 | char(20) | YES | | 1990 | |
| math | float | YES | | 0 | |
+--------+-------------+------+-----+---------+----------------+
查看表的详细结构
语法:show create table 表名;
例子:show create table example7;
修改表
语法:alter table 旧表名 rename [to] 新表名;
例子: alter table example7 rename new1;
修改字段的数据类型
语法:alter table 表名 modify 属性名 数据类型;
例子:alter table new1 modify id tinyint;
修改字段名
语法:alter table 表名 change 旧属性名 新属性名 新数据类型;
例子:alter table new1 change id id1 int;
只修改字段名
alter table new1 change id1 id int;
修改字段名和字段数据类型
alter table new1 change id id1 int(3);
增加字段
语法: alter table 表名 add 属性名1 数据类型[完整性约束条件] [first| after 属性名2]
增加完整性约束条件
alter table new1 add phone varchar(20);
增加有完整性约束条件的字段
alter table new1 add age int(3) not null;
表的第一个位置增加字段
alter table new1 add number int(5) first;
表的指定位置之后增加字段
alter table new1 add yearnum1 varchar(5) not null after phone;
删除字段
语法:Alter table 表名 drop 属性名;
例子:alter table new1 drop id1;
修改字段的排列位置
语法:alter table 表名 modify 属性名1 数据类型 first|after 属性名2;
例子:alter table new1 modify name varchar(20) after stu_id;
alter table new1 modify name varchar(20) first;
更改表存储引擎
语法:alter table 表名 engine=存储引擎名;
例子:alter table new1 engine=innodb default charset=utf8;
查看引擎:show create table new1 \g;
删除表的外键约束
语法:alter table 表名 drop foreign key 外键别名
例子:alter table example3 drop foreign key c_fk;
删除表
语法:drop table 表名;
例子:drop table example5;
..索引
创建在表上的,是对数据库中一行或者多行的值进行排序,可以提高速度
2种存储方式
B树型(innodb myisam存储) 和哈希索引(memory存储引擎)
优点:提高检索速度,对于有依赖关系牟子表和父表之间的联合查询时,可以提升速度 ,使用分组和排序子句进行数据查询 时,减少查询和排序时间
缺点:创建和维护需要沾消耗时间。随着数据的增加而增加。每一个索引占一定的物理空间
分类
普通索引:不附加任何条件,在创建任何数据类型中,其值是否是唯一和非空由字段本身的完整性约束条件决定的,建立此索引就可以查询了
唯一性索引(unique):在创建索引时,限制条件了,而且是唯一的,其中主键就是唯一索引的一种
全文索引(fulltext):在char,varchar,text时才能创建,查询量大时,它可以提升速度,(myisam支持全文索引),默认情况下, 是不区分大小写的,但索引的列使用了二进制排序后,可以执行区分大小写的全文索引
单列索引:在表中单个字段上创建索引,它只能根据该字段进行索引,可以是普通索引,也可以是唯一性索引,还可以是全文索引,只要保证该索引只对应一个字段即可
多列索引:在表的多个字段上创建一个索引,对应多个字段,可以通过这几个字段进行查询,但是只有查询条件中使用了这些字段中第一个字段时,才会被索引
空间索引(spatial):建立在空间数据类型,可以提升系统获取空间数据效率,包括(geometry point linestring polygon)
目前只有myisam存储引擎支持该 空间索引,且索引字段不能为空,
索引的设计原则
1:选择唯一性索引:因为唯一性的值是唯一的,可以快速的通过该索引确定到某条记录
2:为经常需要的排序,分组和联合操作的字段建立索引
<order by group by distinct 和union等操作字段>,排序操作会浪费时间
3:为常用作为查询条件的字段建立索引
如果某个字体常用用来做查询条件,那么该字段的查询速度会影响整个表的查询速度,因此为这样的字段建立索引,可以提高整个表的查询速度
4:限制索引的数目
索引数日不是越多越好,每个索引会占用磁盘空间,索引越多,需要的磁盘空间越多,修改表时,对索引重构和更新很麻烦,越多的索引,会使表变得浪费时间;
5:尽量使用数据量少的索引
如果索引值很长,那么查询速度会有影响
7:尽量使用前缀来索引
如果索引字段的值很长,最好使用值的前缀来索引
8:删除不再使用或者很少使用的索引
表中的数据被大量更新,或者数据使用方式被改变后,原有的一些索引可能不再需要,数据库管理员应当定期找出这些索引,将它们删除,从而减少对更新操作的影响
创建索引
语法:create table 表名(属性名 数据类型[完整性约束条件],
属性名 数据类型[uniqoe|fulltext|spatial] index|key [别名](属性名1[(长度)][asc|desc]));
Uniqoe是可选的,表示唯一索引,fulltext/spatial全文/空间索引(可选),index/key(可选)指定字段索引的,2者选择其中之王就可以,作用都是一样的,别名是可选的,asc|desc(可选),升序/降序
创建普通索引
不需要以下参数:unique,fulltext spatial参数
例子:
create table index1(id int(2),
name varchar(20),
sex boolean,
index(id));
查看该索引是否被引用
explain select*from index1 while id=1\g;
创建唯一性索引(unique参数)
例子:
create table index2(id int unique,
name varchar(20),
unique index index2_id(id asc));
创建全文索引(char varchar,text类型字段上面,现在只有myisam存储引擎支持全文索引)
例子:create table index3(id int unique,
info varchar(20),
unique index index2_info(info))engine=myisam;
创建单列索引(单个字段上创建索引)
例子:create table index4(id int,
sub varchar(20),
name varchar(30),
index index4_name(name));
Or
create table index4(id int,
sub varchar(20),
name varchar(30),
index index4_name(name(10)));
创建多列索引
例子:
create table index5(id int,
name1 varchar(20),
index index5_ni(name1,id));
指定条件索引查询: explain select*from index5 where name1=‘n‘\g
创建空间索引(spatial)
例子:create table index6(id int ,
space geometry not null,
spatial index index6_id(space))engine=myisam;
在已经存在的表上创建索引
语法:create [unique|fulltext|spatial] index 索引名 on 表名(属性名 [(长度)][asc|desc]);
Uniqoe是可选的,表示唯一索引,fulltext/spatial全文/空间索引(可选),index/key(可选)指定字段索引的,2者选择其中之王就可以,作用都是一样的,别名是可选的,asc|desc(可选),升序/降序
表名参数是指需要创建索引的表的名称,该表必须已经存在,如果未存在 ,就必须先创建
......创建普通索引
例子:
create index index7_id on exampel2(stu_id);
....创建唯一性索引
例子:create unique index index8_id on index8(course_id);#这行代码有问题,只是一个例子而已
...创建全文索引
例子:create fulltext index index9_info on index9(info)这行代码有问题,只是一个例子而已
...创建单列索引
例子:create index index10_addr on index10(address(4));这行代码有问题,只是一个例子而已
...创建多列索引
例子:create index index11_na on index11(name,address);这行代码有问题,只是一个例子而已
...创建空间索引
例子:create spatial index index12_line on index12(line);这行代码有问题,只是一个例子而已
使用alter table语句创建索引
语法;alter table 表名 add [unique|fulltext|spatial] index 索引名 (属性名 [(长度)][asc|desc]);
创建普通索引
例子:alter table obj add index index13_name(name(20))
创建唯一性索引
例子:alter table obj add unique index index14_id(count_id)
创建全文索引
例子:alter table obj add fulltext index index15_info(info)
创建单列索引
例子:alter table obj add index index16_a(a(4))
创建多列索引
例子:alter table obj add index index17_bn(bn,addres)
创建空间索引
例子:alter table obj add spatial index index18_abc(abc)
删除索引(指已经存在于表的索引删除掉)
语法:drop index 索引名 on 表名;
视图(一张或者多张的表导出的虚拟表)
概念:是从数据库中一个或者多个表中导出的表,还可以从已经存在的视图基础上定义,数据库中只存放了视图的定义,但没有存储视图中的数据,当原表中的数据发生变化时,视图中的数据也会发生变化。
作用:
1:操作简单化
所见及所得即所需。就是可以从视图中获取所需要的信息
2:增加数据安全性
通过视图,可以查询和修改指定的数据,指定以外的数据,用户根本不能接触,使用视图可以限制用户的操作限制,使用视图之后,可以简单方便 地将用户的权限限制到特定的行与列上,这样可以保证敏感的信息不会被没有权限的人看到,这样可以保证数据的安全性
3:提高表的逻辑性
视图可以对原有表结构变化带来影响
创建视图
语法:create [algorithm={undefined|merge|temptable}] view 视图名 [(属性清单)] as select 语句
[with [cascaed|local] check option];
参数说明:
Algorithm是可选参数,视图的算法选择,视图名参数表示要创建视图的名称,属性清单是可选参数,是指:视图中各个属性名词,默认情况下与select语句中查询的属性相同,select语句参数是一个完整的查询语句,表示表中查出某些满足条件的记录,将这些导入到视图中,with check option 是可选参数,表示更新视图要保证在该视图范围之内.
Algorithm包含了3个选项:undefined|merge|temptable,其中undefinde选项表示mysql将自动选择所要使用的算法
Merge表示将使用视图的语句与视图定义合并起来,使用视图定义的某一个部分取代对应部分,temptable表示将视图结果存入临时表,然后使用临时表执行语句
Cascaded可选参数,表示更新视图时满足所有相关视图和表的条件,是一个默认值,local表示更新视图,要满足该视图本身的定义条件即可.
说明
使用create view创建视图时,最好加上with check option参数,而且最好加上cascades这样从视图派生出来的新视图之后,更新新视图需要考虑其父视图约束条件,这样可以保证数据的安全性.
使用select语句查询创建视图的语句
如下:
Select select_view,create_view from mysql.,user where user=’root’;
Select_view表示用户是否具有select权限
Create_view表示用户是否具有 crate view权限
如果是y表示有权限
Mysql.user是mysql下面的数据库user表
用户名表示要查询那个用户是否拥有drop权限,该参数需要使用引号来使用
在单表上创建视图
例子:create view d_view as select*from p2;
Query OK, 0 rows affected (0.11 sec)表示创建成功,而且不会影响以前的表的数据,因为它是虚拟的,可以使用desc语句来查看表的结构,如下: desc d_view;
在指定表上创建一个名为d1_view视图
如下,例子: create view d1_view(id)
as select id from p2;
查看表结构: desc d1_view;
在多表上创建视图
2个或者2个以上的
在 (exampel2 和exampl2) 这2张表上创建虚拟视图
例子:
create algorithm=merge view
exr_view as select(exampel2.stu_id)from exampel2,exampl2 where exampl2.stu_id=exampel2.stu_id
with local check option;
查看视图
语法:describe/desc 视图表;
使用show table status语句查看视图基本信息
语法:show table status like ‘视图表’
使用show table view语句查看视图详细信息
语法: show create view 视图表;
在 views表中查看视图详细信息
语句如下:select *from information_schema.views;
修改视图
1:create or replace view
语法:create or replace
[algorithm={undefined|merge|temptable}] view 视图名 [(属性清单)] as select 语句
[with [cascaed|local] check option];
例子: create or replace algorithm=temptable
view exr_view( stu_id1) as select stu_id from exampl2;
Alter语句修改视图
语法:alter[algorithm={undefined|merge|temptable}] view 视图名 [(属性清单)] as select 语句
[with [cascaed|local] check option];
例子:alter algorithm=temptable
view exr_view( stu_id2) as select stu_id from exampl2;
更新视图
使用(insert update delete)来操作
先创建一个新view
然后使用(insert update delete)来操作
create view d1_view(id)
as select id from p2;
例子(undate):
Undate exr_view1 set id=’100’;
删除视图:
语法:drop view [if exists]视图名列表 [restrict|cascade]
if exists:表示是否存在,如果存在,就执行,反之,不执行
标签:
原文地址:http://www.cnblogs.com/mhxy13867806343/p/4223682.html