标签:
Http 协议
重要性:
1. 无论以后用 WebService 还是用 rest 作大型架构,都离不开。
WebService = Http 协议 + XML
Rest = HTTP 协议 + Json
各种 API , 一般也是用 http + XML/json 来实现
2. 以及 Ajax 的学习
什么是协议 ( 就是客户端问服务器答)
计算机中的协议和现实中的协议是一样的,一式双份/多份. 双方/多方都遵从共同的一个规范, 这个规范就可以称为协议。计算机之所以能全世界互通,协议是功不可没,如果没有协议,计算机各说各话,谁都听不懂.
Ftp, http, smtp, pop, tcp/ip 协议的
Http 协议的工作流程
客户端 服务器(Apache/Nginx/..../iis)
0: 原始状态,客户端和服务器之间没有关系
连接: 就是网络上的虚拟电路,像 QQ, 是和服务器一直连接
1: 建立连接,客户端发送请求,服务器沿着连接返回响应信息
2: 客户端收到响应(html 代码)
3: 断开连接
HTTP 请求信息和响应信息的格式
GET 请求
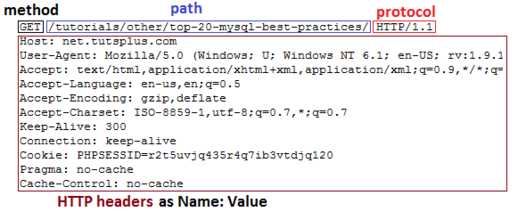
请求:
1. 请求行
请求方法: GET/POST/HEAD/PUT/DELETE/TRACE/OPTIONS
HEAD 和 GET 基本一致,只是不返回内容,比如只是确认一个内容比如照片是否存在,不需要返回的时候,或只是检测服务器的状态
WEB SERVER 未必允许或者支持这些方法,不支持的话会返回 405: Method is not allowed
PUT 是用于往服务器上放资源
TRACE: 是你用了代理上网,你想看看代理有没有修改/篡改你的HTTP请求,可以用TRACE测试
OPTIONS: 用于查看服务器允许了那些方法
请求路径: 也就是请求的资源,URL 的一部分
所用协议: 也就是请求所有的协议版本,基本都是 HTTP/1.1
2. 请求头信息: 如: Host: localhost。 头信息和主体信息之前必须有一个空行,即使没有主体信息。
头信息是非常丰富的,而且丰富的头信息也是学习重点
3. 请求主体信息 (可有可无)
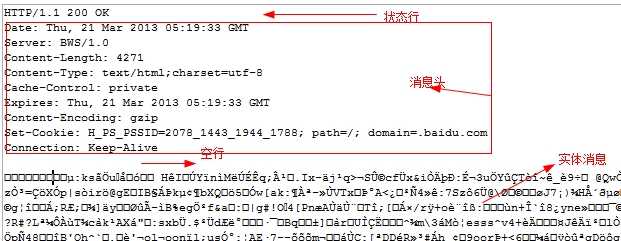
响应
1. 响应行
协议版本
状态码: 用来反映服务器的响应结果,常见的
200 OK,服务器成功返回页面
301/2, 永久/临时重定向
304 Not Modified - 未修改,就是说取的是本地缓存。(原理是在服务器的响应头信息中,有Last-Modified 和 E-Tag, 用来标志服务端的文件是否修改,则再次请求的时候,客户端的请求头中会有 If-Modifed-since 和 If-None-Match 信息,来判断是否需要重新请求
307 - 重定向中保护原有的请求数据,Get 没有必要用, POST 会用到
404 NOT FOUND, 403 FORBIDDEN, 503 服务器内部错误
状态文字:是用来描述状态码的,便于观察
|
状态码 |
定义 |
|
1xx 报告 |
接收到请求,继续进程,留作日后拓展 |
|
2xx 成功 |
操作成功接收,被理解,并被接受 |
|
3xx 重定向 |
为了完成请求,必须采取进一步措施 |
|
4xx 客户端出错 |
请求的语法有错误或不能完全被满足 |
|
5xx 服务器出错 |
服务器无法完成明显有效的请求 |
2. 响应头信息 (格式为Key: value)
content-length: 接下来主体的长度
3. 响应主体 (可能有)
例:
HTTP/1.1 200 OK
content-type: text/html
content-length: 5
hello
Q:HTTP 协议一定要浏览器发送么
A:
POST 请求
1. 在使用 POST 发送请求是,头信息中必须要加上 content-length 信息
2. 同时需要告诉服务器 content-type: application/x-www-form-urlencoded
常见的type 见附录
text/xml
application/json
multipart/form-data
application/x-www-form-urlencoded
要求能模拟下载,注册,登陆
HTTP协议是超文本传送协议(HyperText Transfer Protocol)的缩写,它是万维网(World Wide Web,www,也简称为Web)的基础。HTTP协议设计之初就是为了实现Web的想法。HTTP协议位于TCP/IP协议栈的应用层。
我们在浏览器的地址栏里输入的网站地址叫做URL(UniformResourceLocator,统一资源定位符)。就像每家每户都有一个门牌地址一样,每个网页也都有一个Internet地址。当你在浏览器的地址框中输入一个URL或是单击一个超级链接时,URL就确定了要浏览的地址。浏览器通过超文本传输协议(HTTP),将Web服务器上站点的网页代码提取出来,并呈现出客户端需要的网页。
HTTP协议使用的默认端口是80,同时也支持自定义端口。
HTTP协议到现在为止总共经历了3个版本的演化,第一个HTTP协议诞生于1989年3月。当时Berners-Lee向 CERN(Conseil Europeen pour la Recherche Nucleaire,欧洲核能研究所)提交了一篇名为《信息管理的一个提议》的文章。文章中提出了www网络的构想,不过仅仅在很多方面都只关注了概念,而没涉及到细节。
第一个HTTP协议的版本是HTTP 0.9,它的组成极其简单,因为它只允许客户端发送GET这一种请求,它不包含协议头,每个请求只有一句话,例如:
GET /index.html
由于没有协议头,造成了HTTP 0.9协议只支持一种内容,即纯文本。不过网页仍然支持用HTML语言格式化,同时无法插入图片。所以HTTP 0.9能够支持的应用实在太有限了。一次HTTP 0.9的传输首先要建立一个由客户端到Web服务器的TCP连接,由客户端发起一个请求,然后由Web服务器返回页面内容,然后连接会关闭。如果请求的页面不存在,也不会返回任何错误码。
HTTP 0.9的缺点是显著的,但至少实现了第一代的Web。
HTTP协议的第二个版本是HTTP 1.0,直到HTTP 1.0成为最重要的面向事务的应用层协议。该协议对每一次请求/响应,同样是建立并关闭一次连接。其特点是简单、易于管理,所以它符合了大家的需要,得到了广泛的应用。
并且HTTP 1.0最显著的变化之一是开始支持客户端通过POST方法向Web服务器提交数据。从此客户端与Web服务器之间不再只能单向地获取数据,而可以实现交互,因此CGI(Common Gate Interface,通用网关接口)开始流行起来,Web上开始出现留言板、论坛等丰富的应用。
HTTP 1.0还有个显著的变化是通过HTTP协议头可以支持各种媒体类型。从此Web上不再仅仅是纯文本的页面,比如图像通过<img>的HTML标记开始出现。
除了以上几个新特性,HTTP 1.0支持长连接(但默认还是使用短连接),缓存机制,以及身份认证。
虽说HTTP协议的设计是向前兼容的,但目前很多浏览器和Web服务器都强制要求HTTP协议版本至少是1.0。
HTTP协议的第三个版本是HTTP 1.1,它就是目前使用最广泛的协议版本。这个版本的HTTP协议已经稳定了,跟HTTP 1.0相比,它新增了很多引人注目的新特性,比如Host协议头,一个HTTP请求的头中可以包含一句例如:
Host: vimer.cn
从此一个Web服务器可以支持挂载多个域名了,无需每个域名都使用独立IP,每个网站可以使用虚拟主机。
另一个HTTP 1.1的新特性是支持部分内容请求/响应,这意味着当客户端请求的数据量很大时,可以分多次发起请求,每次请求只要求获取整块数据的一部分。Web服务器也可以分多次响应,每次只返回整块数据的一部分。这使得流媒体得以实现。
从HTTP 1.1开始,客户端默认与Web 服务器建立长连接,这种连接适合Web上数据量较大的丰富应用,使得资源消耗更少。
QzHTTP就是一个支持HTTP 1.1协议的Web Server。
2.HTTP协议内容介绍
HTTP协议通过URI(Uniform Resource Identifiers,统一资源定位符)来访问资源。根据RFC 1808的官方定义,一个完整URI的组成如下:
http://myname:mypass@www.vimer.cn:80/mydir/myfile.html?myvar=myvalue#myfrag
URI字段
表 2.1
|
URI部分 |
意义 |
|
http |
协议名称 |
|
myname |
用户名(可选) |
|
mypass |
密码(可选) |
|
主机网络地址 |
|
|
80 |
端口号(可选) |
|
/mydir/myfile.html |
资源路径 |
|
myvar=myvalue |
查询字符串(可选) |
|
myfrag |
锚点(可选) |
可见协议名称用“://”结束,用户名和密码以“:”分隔,以“@”结束,端口号与主机网络地址以“:”分隔,资源路径与查询字符串以“?”分隔,锚点以#开头。
并且,只有协议名称、主机网络地址和资源路径是必须包含在URI里的。
一个更常见的例子如下:
在这里面,http是协议,www.vimer.cn是主机网络地址,注意末尾的/就是资源路径,这是必须的。当我们平时使用Web浏览器访问时,只需要输入www.vimer.cn就可以访问,这是由于Web浏览器替我们自动补齐了前面的http://和最后的/,Web浏览器发起请求时使用的URI还是完整的,Web浏览器并不强制用户输入格式规范的URI。
HTTP协议的交互主要由请求和响应组成,请求是指客户端发起向Web服务器请求资源的消息,而响应是Web服务器根据客户端的请求回送给客户端的资源消息。
发出的请求信息(Request Message)包括以下几部分:
l 请求行,例如GET /images/logo.gif HTTP/1.1,表示从/images 目录下请求logo.gif 这个文件。
l (请求)头,例如Accept-Language: en
l 空行
l 可选的消息体
请求行和标题必须以<CR><LF> 作为结尾(也就是,回车然后换行)。空行内必须只有<CR><LF>而无其他空格。在HTTP/1.1 协议中,所有的请求头,除Host外,都是可选的。
请求方法(Request Method)
HTTP/1.1协议中共定义了八种方法(有时也叫“动作”)来表明Request-URI指定的资源的不同操作方式:
l OPTIONS
返回服务器针对特定资源所支持的HTTP请求方法。也可以利用向Web服务器发送’*’的请求来测试服务器的功能性。
l HEAD
向服务器索要与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以在不必传输整个响应内容的情况下,就可以获取包含在响应消息头中的元信息。
l GET
向特定的资源发出请求。注意:GET方法不应当被用于产生“副作用”的操作中,例如在Web 应用程序中。其中一个原因是GET可能会被网络蜘蛛等随意访问。
l POST
向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
l PUT
向指定资源位置上传其最新内容。
l DELETE
删除指定资源。
l TRACE
回显服务器收到的请求。
l CONNECT
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。
方法名称是区分大小写的。当某个请求所针对的资源不支持对应的请求方法的时候,服务器应当返回状态码405(Method Not Allowed);当服务器不认识或者不支持对应的请求方法的时候,应当返回状态码501(Not Implemented)。
HTTP服务器至少应该实现GET和HEAD方法,其他方法都是可选的,可选方法中还有一个重要的方法是POST。当然,所有的方法支持的实现都应当符合下述的方法各自的语义定义。此外,除了上述方法,特定的HTTP服务器还能够扩展自定义的方法。
一个GET请求的示例如图2.3所示:

图2.3 HTTP请求
GET 代表方法名,后面的/代表资源路径,HTTP/1.1表示协议版本。下面都是协议头部分,常见的头字段如表2.2所示。
HTTP协议头字段
表2.2
|
头字段 |
定义 |
|
Accept |
客户端可以处理的媒体类型(MIME-Type),按优先级排序;在一个以逗号为分隔的列表中,可以定义多种类型和使用通配符 |
|
Accept-Language |
客户端支持的自然语言列表 |
|
Accept-Encoding |
客户端支持的编码列表 |
|
User-Agent |
客户端环境类型 |
|
Host |
服务器端的主机地址 |
|
Connection |
连接类型,默认为Keep-Alive |
HTTP协议是Web内容的容器。一个示例HTTP响应如图2.4所示:

图2.4 HTTP响应
每个响应由HTTP协议头和Web内容构成。Web服务器收到一个请求,就会立刻解释请求中所用到的方法,并开始处理应答。服务器的响应消息也包含头字段形式的协议头。响应的格式在RFC2616中定义如下:
Status-Line*
(( general-header)| response-header | entity-header)CRLF)
CRLF
[ message-body ]
响应消息的第一行是状态行(Stauts-Line),由协议版本以及数字状态码和相关的文本短语组成,各部分间用空格符隔开,除了最后的回车或换行外,中间不允许有回车换行。
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
状态码是试图理解和满足请求的三位数字的整数码, 原因短语(Reason-Phrase)是为了给出的关于状态码的文本描述。状态码用于控制条件,而原因短语(Reason-Phrase)是让用户便于阅读。客户端不需要检查和显示原因短语。
状态码的第一位数字定义响应类型。后两位数字没有任何分类角色。第一位数字有五种值,如表2.3所示。
HTTP响应状态码
表 2.3
|
状态码 |
定义 |
|
1xx 报告 |
接收到请求,继续进程 |
|
2xx 成功 |
步骤成功接收,被理解,并被接受 |
|
3xx 重定向 |
为了完成请求,必须采取进一步措施 |
|
4xx 客户端出错 |
请求包括错的顺序或不能完成 |
|
5xx 服务器出错 |
服务器无法完成显然有效的请求 |
下面列举了为HTTP/1.1定义的状态码值,和对应的原因短语(Reason-Phrase)的例子。
l 客户端错误
“100″ : Continue 继续
“101″ : witching Protocols 交换协议
l 成功
“200″ : OK
“201″ : Created 已创建
“202″ : Accepted 接收
“203″ : Non-Authoritative Information 非认证信息
“204″ : No Content 无内容
“205″ : Reset Content 重置内容
“206″ : Partial Content 部分内容
l 重定向
“300″ : Multiple Choices 多路选择
“301″ : Moved Permanently 永久转移
“302″ : Found 暂时转移
“303″ : See Other 参见其它
“304″ : Not Modified 未修改
“305″ : Use Proxy 使用代理
“307″ : Temporary Redirect
l 客户方错误
“400″ : Bad Request 错误请求
“401″ : Unauthorized 未认证
“402″ : Payment Required 需要付费
“403″ : Forbidden 禁止
“404″ : Not Found 未找到
“405″ : Method Not Allowed 方法不允许
“406″ : Not Acceptable 不接受
“407″ : Proxy Authentication Required 需要代理认证
“408″ : Request Time-out 请求超时
“409″ : Conflict 冲突
“410″ : Gone 失败
“411″ : Length Required 需要长度
“412″ : Precondition Failed 条件失败
“413″ : Request Entity Too Large 请求实体太大
“414″ : Request-URI Too Large 请求URI太长
“415″ : Unsupported Media Type 不支持媒体类型
“416″ : Requested range not satisfiable
“417″ : Expectation Failed
l 服务器错误
“500″ : Internal Server Error 服务器内部错误
“501″ : Not Implemented 未实现
“502″ : Bad Gateway 网关失败
“503″ : Service Unavailable
“504″ : Gateway Time-out 网关超时
“505″ : HTTP Version not supported HTTP版本不支持
HTTP状态码是可扩展的。HTTP应用程序不需要理解所有已注册状态码的含义,尽管那样的理解显而易见是很合算的。但是,应用程序必须了解由第一位数字指定的状态码的类型,任何未被识别的响应应被看作是该类型的x00状态,有一个例外就是未被识别的响应不能缓存。例如,如果客户端收到一个未被识别的状态码431,则可以安全的假定请求有错,并且它会对待此响应就像它接收了一个状态码是400的响应。在这种情况下,用户代理(user agent)应当把实体和响应一起提交给用户,因为实体很可能包括人可读的关于解释不正常状态的信息。报文最后是实体信息,即客户请求得到的HTTP服务器上的资源内容
这应该是最常见的 POST 提交数据的方式了。浏览器的原生 form 表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded 方式提交数据。请求类似于下面这样(无关的请求头在本文中都省略掉了):
POST http://www.example.com HTTP/1.1
Content-Type: application/x-www-form-urlencoded;charset=utf-8
title=test&sub%5B%5D=1&sub%5B%5D=2&sub%5B%5D=3
首先,Content-Type 被指定为 application/x-www-form-urlencoded;其次,提交的数据按照 key1=val1&key2=val2 的方式进行编码,key 和 val 都进行了 URL 转码。大部分服务端语言都对这种方式有很好的支持。例如 PHP 中,$_POST[‘title‘] 可以获取到 title 的值,$_POST[‘sub‘] 可以得到 sub 数组。
很多时候,我们用 Ajax 提交数据时,也是使用这种方式。例如 JQuery 和 QWrap 的 Ajax,Content-Type 默认值都是「application/x-www-form-urlencoded;charset=utf-8」。
multipart/form-data
这又是一个常见的 POST 数据提交的方式。我们使用表单上传文件时,必须让 form 的 enctyped 等于这个值。直接来看一个请求示例:
POST http://www.example.com HTTP/1.1
Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryrGKCBY7qhFd3TrwA
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="text"
title
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="file"; filename="chrome.png"
Content-Type: image/png
PNG ... content of chrome.png ...
------WebKitFormBoundaryrGKCBY7qhFd3TrwA--
这个例子稍微复杂点。首先生成了一个 boundary 用于分割不同的字段,为了避免与正文内容重复,boundary 很长很复杂。然后 Content-Type 里指明了数据是以 mutipart/form-data 来编码,本次请求的 boundary 是什么内容。消息主体里按照字段个数又分为多个结构类似的部分,每部分都是以 --boundary 开始,紧接着内容描述信息,然后是回车,最后是字段具体内容(文本或二进制)。如果传输的是文件,还要包含文件名和文件类型信息。消息主体最后以 --boundary-- 标示结束。关于 mutipart/form-data 的详细定义,请前往 rfc1867 查看。
这种方式一般用来上传文件,各大服务端语言对它也有着良好的支持。
上面提到的这两种 POST 数据的方式,都是浏览器原生支持的,而且现阶段原生 form 表单也只支持这两种方式。但是随着越来越多的 Web 站点,尤其是 WebApp,全部使用 Ajax 进行数据交互之后,我们完全可以定义新的数据提交方式,给开发带来更多便利。
application/json
application/json 这个 Content-Type 作为响应头大家肯定不陌生。实际上,现在越来越多的人把它作为请求头,用来告诉服务端消息主体是序列化后的 JSON 字符串。由于 JSON 规范的流行,除了低版本 IE 之外的各大浏览器都原生支持 JSON.stringify,服务端语言也都有处理 JSON 的函数,使用 JSON 不会遇上什么麻烦。
JSON 格式支持比键值对复杂得多的结构化数据,这一点也很有用。记得我几年前做一个项目时,需要提交的数据层次非常深,我就是把数据 JSON 序列化之后来提交的。不过当时我是把 JSON 字符串作为 val,仍然放在键值对里,以 x-www-form-urlencoded 方式提交。
Google 的 AngularJS 中的 Ajax 功能,默认就是提交 JSON 字符串。例如下面这段代码:
var data = {‘title‘:‘test‘, ‘sub‘ : [1,2,3]};
$http.post(url, data).success(function(result) {
...
});
最终发送的请求是:
POST http://www.example.com HTTP/1.1
Content-Type: application/json;charset=utf-8
{"title":"test","sub":[1,2,3]}
这种方案,可以方便的提交复杂的结构化数据,特别适合 RESTful 的接口。各大抓包工具如 Chrome 自带的开发者工具、Firebug、Fiddler,都会以树形结构展示 JSON 数据,非常友好。但也有些服务端语言还没有支持这种方式,例如 php 就无法通过 $_POST 对象从上面的请求中获得内容。这时候,需要自己动手处理下:在请求头中 Content-Type 为 application/json 时,从 php://input 里获得原始输入流,再 json_decode 成对象。一些 php 框架已经开始这么做了。
当然 AngularJS 也可以配置为使用 x-www-form-urlencoded 方式提交数据。如有需要,可以参考这篇文章。
text/xml
我的博客之前提到过 XML-RPC(XML Remote Procedure Call)。它是一种使用 HTTP 作为传输协议,XML 作为编码方式的远程调用规范。典型的 XML-RPC 请求是这样的:
POST http://www.example.com HTTP/1.1
Content-Type: text/xml
<!--?xml version="1.0"?-->
<methodcall>
<methodname>examples.getStateName</methodname>
<params>
<param>
<value><i4>41</i4></value>
</params>
</methodcall>
XML-RPC 协议简单、功能够用,各种语言的实现都有。它的使用也很广泛,如 WordPress 的 XML-RPC Api,搜索引擎的 ping 服务等等。JavaScript 中,也有现成的库支持以这种方式进行数据交互,能很好的支持已有的 XML-RPC 服务。不过,我个人觉得 XML 结构还是过于臃肿,一般场景用 JSON 会更灵活方便。
标签:
原文地址:http://www.cnblogs.com/TikyZheng/p/4656239.html