标签:
SQL Server表分区只支持range分区这一种类型,往往会被大家吐槽
人家MySQL支持四种类型:RANGE分区、LIST分区、HASH分区、KEY分区
共同点是MySQL跟SQL Server也有分区对齐的问题,都是水平切分,大家都允许分区列存在NULL值
这次我们测试SQL Server表分区的分区列的NULL值,究竟NULL值是被存放在哪个区间,以前一直没有注意
测试脚本

--1.创建文件组 ALTER DATABASE [sss] ADD FILEGROUP [FG_TinyBlog_Id_01] ALTER DATABASE [sss] ADD FILEGROUP [FG_TinyBlog_Id_02] ALTER DATABASE [sss] ADD FILEGROUP [FG_TinyBlog_Id_03] ALTER DATABASE [sss] ADD FILEGROUP [FG_TinyBlog_Id_04] ALTER DATABASE [sss] ADD FILEGROUP [FG_TinyBlog_Id_05] --2.创建文件 ALTER DATABASE [sss] ADD FILE (NAME = N‘FG_TinyBlog_Id_01_data‘,FILENAME = N‘E:\DataBase\sss\FG_TinyBlog_Id_01_data.ndf‘,SIZE = 96MB, FILEGROWTH = 24MB ) TO FILEGROUP [FG_TinyBlog_Id_01]; ALTER DATABASE [sss] ADD FILE (NAME = N‘FG_TinyBlog_Id_02_data‘,FILENAME = N‘E:\DataBase\sss\FG_TinyBlog_Id_02_data.ndf‘,SIZE = 96MB, FILEGROWTH = 24MB ) TO FILEGROUP [FG_TinyBlog_Id_02]; ALTER DATABASE [sss] ADD FILE (NAME = N‘FG_TinyBlog_Id_03_data‘,FILENAME = N‘E:\DataBase\sss\FG_TinyBlog_Id_03_data.ndf‘,SIZE = 96MB, FILEGROWTH = 24MB ) TO FILEGROUP [FG_TinyBlog_Id_03]; ALTER DATABASE [sss] ADD FILE (NAME = N‘FG_TinyBlog_Id_04_data‘,FILENAME = N‘E:\DataBase\sss\FG_TinyBlog_Id_04_data.ndf‘,SIZE = 96MB, FILEGROWTH = 24MB ) TO FILEGROUP [FG_TinyBlog_Id_04]; ALTER DATABASE [sss] ADD FILE (NAME = N‘FG_TinyBlog_Id_05_data‘,FILENAME = N‘E:\DataBase\sss\FG_TinyBlog_Id_05_data.ndf‘,SIZE = 96MB, FILEGROWTH = 24MB ) TO FILEGROUP [FG_TinyBlog_Id_05]; --3.创建分区函数 CREATE PARTITION FUNCTION Fun_TinyBlog_Id(INT) AS RANGE LEFT FOR VALUES(-10,0,1,6) --4.创建分区方案 CREATE PARTITION SCHEME [Sch_TinyBlog_Id] AS PARTITION [Fun_TinyBlog_Id] TO([FG_TinyBlog_Id_01],[FG_TinyBlog_Id_02],[FG_TinyBlog_Id_03],[FG_TinyBlog_Id_04],[FG_TinyBlog_Id_05])
插入测试数据
USE [sss] CREATE TABLE TinyBlog(id INT NULL,NAME VARCHAR(100)) ON [Sch_TinyBlog_Id](id) SELECT * FROM TinyBlog ORDER BY id INSERT INTO [dbo].[TinyBlog] ( [id], [NAME] ) VALUES ( NULL, -- id - int ‘3232‘ -- NAME - varchar(100) ) INSERT INTO [dbo].[TinyBlog] ( [id], [NAME] ) VALUES ( -2, -- id - int ‘-2‘ -- NAME - varchar(100) ) INSERT INTO [dbo].[TinyBlog] ( [id], [NAME] ) VALUES ( 66, -- id - int ‘66‘ -- NAME - varchar(100) ) INSERT INTO [dbo].[TinyBlog] ( [id], [NAME] ) VALUES ( 0, -- id - int ‘0‘ -- NAME - varchar(100) ) INSERT INTO [dbo].[TinyBlog] ( [id], [NAME] ) VALUES ( -30, -- id - int ‘-30‘ -- NAME - varchar(100) )
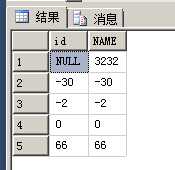
表数据如下
SELECT * FROM TinyBlog ORDER BY id
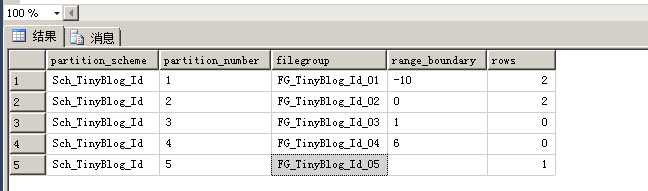
分区分布
--查看分区架构文件组分布 SELECT CONVERT(VARCHAR(MAX), ps.name) AS partition_scheme , p.partition_number , CONVERT(VARCHAR(MAX), ds2.name) AS filegroup , CONVERT(VARCHAR(MAX), ISNULL(v.value, ‘‘), 120) AS range_boundary , STR(p.rows, 9) AS rows FROM sys.indexes i JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id JOIN sys.destination_data_spaces dds ON ps.data_space_id = dds.partition_scheme_id JOIN sys.data_spaces ds2 ON dds.data_space_id = ds2.data_space_id JOIN sys.partitions p ON dds.destination_id = p.partition_number AND p.object_id = i.object_id AND p.index_id = i.index_id JOIN sys.partition_functions pf ON ps.function_id = pf.function_id LEFT JOIN sys.Partition_Range_values v ON pf.function_id = v.function_id AND v.boundary_id = p.partition_number - pf.boundary_value_on_right WHERE i.object_id = OBJECT_ID(‘TinyBlog‘) AND i.index_id IN ( 0, 1 ) ORDER BY p.partition_number --分区区间 --SELECT * FROM sys.partition_range_values
分区情况
--分区情况 SELECT c.* , b.[groupname] AS ‘分区方案对应的文件组名称‘ , d.name ‘当前分区函数对应的分区方案‘ FROM sys.destination_data_spaces AS a INNER JOIN sysfilegroups AS b ON a.[data_space_id] = b.[groupid] INNER JOIN ( SELECT $PARTITION.Fun_TinyBlog_Id(id) AS 分区编号 , MIN(id) AS Min_value , MAX(id) AS Max_value , COUNT(id) AS 记录数 FROM [dbo].[TinyBlog] GROUP BY $PARTITION.Fun_TinyBlog_Id(id) ) AS c ON c.[分区编号] = a.[destination_id] INNER JOIN sys.partition_schemes AS d ON a.[partition_scheme_id] = d.data_space_id ORDER BY c.[分区编号]
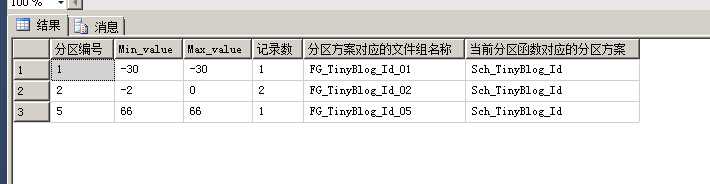
第二个视图直接把NULL值忽略了
根据第一个视图,我们画出一个总结图
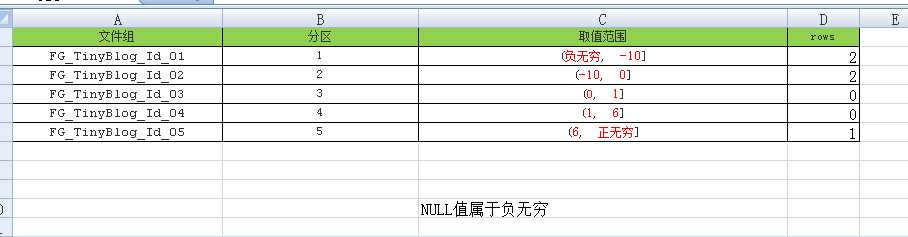
分析一下

总结
结论其实很清晰,分区列不要允许NULL,如果允许列,那么我们交换分区归档数据的时候就会有麻烦了,因为无法判断分区列是NULL值的那些数据行是老数据还是新数据
相关文章:
http://www.cnblogs.com/gaizai/archive/2010/11/05/1870071.html
https://msdn.microsoft.com/zh-cn/library/ms187802.aspx
如有不对的地方,欢迎大家拍砖o(∩_∩)o
标签:
原文地址:http://www.cnblogs.com/lyhabc/p/4660846.html
