标签:
在很多的时候,我们会在数据库的表中设置一个字段:ID,这个ID是一个IDENTITY,也就是说这是一个自增ID。当并发量很大并且这个字段不是主键的时候,就有可能会让这个值重复;或者在某些情况(例如插入数据的时候出错,或者是用户使用了Delete删除了记录)下会让ID值不是连续的,比如1,2,3,5,6,7,10,那么在中间就断了几个数据,那么我们希望能在数据中找出这些相关的记录,我希望找出的记录是3,5,7,10,通过这些记录可以查看这些记录的规律来分析或者统计;又或者我需要知道那些ID值是没有的:4,8,9。
解决办法的核心思想是: 获取到当前记录的下一条记录的ID值,再判断这两个ID值是否差值为1,如果不为1那就表示数据不连续了
执行下面的语句生成测试表和测试记录
1 --生成测试数据 2 if exists (select * from sysobjects where id = OBJECT_ID(‘[t_IDNotContinuous]‘) and OBJECTPROPERTY(id, ‘IsUserTable‘) = 1) 3 DROP TABLE [t_IDNotContinuous] 4 5 CREATE TABLE [t_IDNotContinuous] ( 6 [ID] [int] IDENTITY (1, 1) NOT NULL, 7 [ValuesString] [nchar] (10) NULL) 8 9 SET IDENTITY_INSERT [t_IDNotContinuous] ON 10 11 INSERT [t_IDNotContinuous] ([ID],[ValuesString]) VALUES ( 1,‘test‘) 12 INSERT [t_IDNotContinuous] ([ID],[ValuesString]) VALUES ( 2,‘test‘) 13 INSERT [t_IDNotContinuous] ([ID],[ValuesString]) VALUES ( 3,‘test‘) 14 INSERT [t_IDNotContinuous] ([ID],[ValuesString]) VALUES ( 5,‘test‘) 15 INSERT [t_IDNotContinuous] ([ID],[ValuesString]) VALUES ( 6,‘test‘) 16 INSERT [t_IDNotContinuous] ([ID],[ValuesString]) VALUES ( 7,‘test‘) 17 INSERT [t_IDNotContinuous] ([ID],[ValuesString]) VALUES ( 10,‘test‘) 18 19 SET IDENTITY_INSERT [t_IDNotContinuous] OFF 20 21 select * from [t_IDNotContinuous]
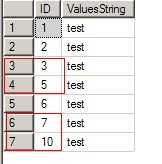
(图1:测试表)
1 --拿到当前记录的下一个记录进行连接 2 select ID,new_ID 3 into [t_IDNotContinuous_temp] 4 from ( 5 select ID,new_ID = ( 6 select top 1 ID from [t_IDNotContinuous] 7 where ID=(select min(ID) from [t_IDNotContinuous] where ID>a.ID) 8 ) 9 from [t_IDNotContinuous] as a 10 ) as b 11 12 select * from [t_IDNotContinuous_temp]
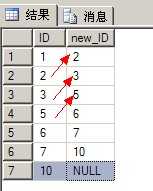
(图2:错位记录)
1 --不连续的前前后后记录 2 select * 3 from [t_IDNotContinuous_temp] 4 where ID <> new_ID - 1 5 6 7 --查询原始记录 8 select a.* from [t_IDNotContinuous] as a 9 inner join (select * 10 from [t_IDNotContinuous_temp] 11 where ID <> new_ID - 1) as b 12 on a.ID >= b.ID and a.ID <=b.new_ID 13 order by a.ID
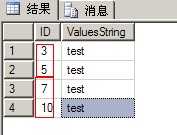
(图3:效果)
补充1:如果这个ID字段不是主键,那么就会有ID值重复的情况(有可能是一些误操作,之前就有遇到过)那么就需要top 1来处理。但是当前这种情况下可以使用下面的简化语句
1 select a.id as oid, nid = 2 (select min(id) from t_IDNotContinuous b where b.id > a.id) 3 from t_IDNotContinuous a
补充2:缺失ID值列表,
1--方法一:找出上一条记录+1,再比较大小 2 select (select max(id)+1 3 from [t_IDNotContinuous] 4 where id<a.id) as beginId, 5 (id-1) as endId 6 from [t_IDNotContinuous] a 7 where 8 a.id>(select max(id)+1 from [t_IDNotContinuous] where id<a.id)
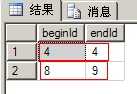
(图4:效果)
1 --方法二:全部+1,再判断在原来记录中找不到 2 select beginId, 3 (select min(id)-1 from [t_IDNotContinuous] where id > beginId) as endId 4 from ( 5 select id+1 as beginId from [t_IDNotContinuous] 6 where id+1 not in 7 (select id from [t_IDNotContinuous]) 8 and id < (select max(id) from [t_IDNotContinuous]) 9 ) as t
标签:
原文地址:http://www.cnblogs.com/liuxiaoji/p/4664117.html