标签:
XML文件解析方法
XML在不同的语言里解析方式都是一样的,只不过实现的语法不同而已。基本的解析方式有两种,一种叫SAX,另一种叫DOM。SAX是基于事件流的解析,DOM是基于XML文档树结构的解析。假设我们XML的内容和结构如下:
<?xml version="1.0" encoding="UTF-8"?>
- <employees>
- <employee>
- <name>ddviplinux</name>
- <sex>m</sex>
- <age>30</age>
- </employee>
- </employees>
本文实现DOM与SAX的XML文档生成与解析。
首先定义一个操作XML文档的接口XmlDocument 它定义了XML文档的建立与解析的接口。
- package com.alisoft.facepay.framework.bean;
-
- /**
- *
- * @author hongliang.dinghl
- * 定义XML文档建立与解析的接口
- */
- public interface XmlDocument {
- /**
- * 建立XML文档
- * @param fileName 文件全路径名称
- */
- public void createXml(String fileName);
-
- /**
- * 解析XML文档
- * @param fileName 文件全路径名称
- */
- public void parserXml(String fileName);
- }
1.DOM生成和解析XML文档
为 XML 文档的已解析版本定义了一组接口。解析器读入整个文档,然后构建一个驻留内存的树结构,然后代码就可以使用 DOM 接口来操作这个树结构。优点:整个文档树在内存中,便于操作;支持删除、修改、重新排列等多种功能;缺点:将整个文档调入内存(包括无用的节点),浪费时间和空间;使用场合:一旦解析了文档还需多次访问这些数据;硬件资源充足(内存、CPU)。
(1)DOM解析XML文档所使用到的jar:dom.jar
(2)DOM解析与创建XML文档示例代码
2.SAX生成和解析XML文档
为解决DOM的问题,出现了SAX。SAX ,事件驱动。当解析器发现元素开始、元素结束、文本、文档的开始或结束等时,发送事件,程序员编写响应这些事件的代码,保存数据。优点:不用事先调入整个文档,占用资源少;SAX解析器代码比DOM解析器代码小,适于Applet,下载。缺点:不是持久的;事件过后,若没保存数据,那么数据就丢了;无状态性;从事件中只能得到文本,但不知该文本属于哪个元素;使用场合:Applet;只需XML文档的少量内容,很少回头访问;机器内存少;
(1)SAX解析XML文档所使用到的jar包:sax.jar
(2)SAX关健类的,类结构图
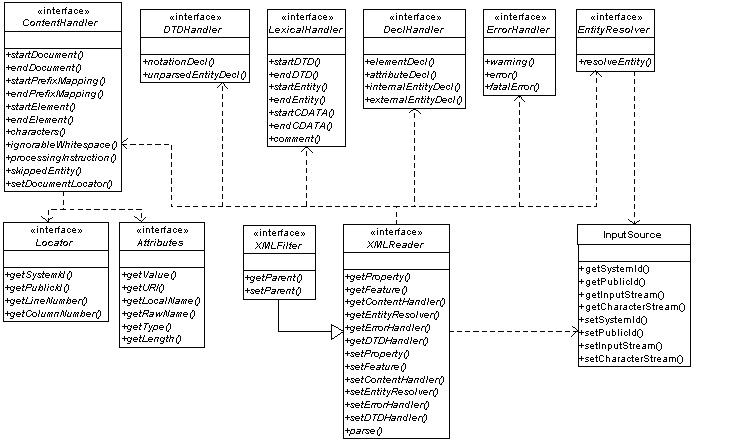
(3)SAX文档解释示例代码
package com.alisoft.facepay.framework.bean;
-
- import java.io.BufferedOutputStream;
- import java.io.File;
- import java.io.FileInputStream;
- import java.io.FileOutputStream;
- import java.io.IOException;
- import java.io.PrintStream;
- import org.xml.sax.Attributes;
- import org.xml.sax.ContentHandler;
- import org.xml.sax.ErrorHandler;
- import org.xml.sax.InputSource;
- import org.xml.sax.Locator;
- import org.xml.sax.SAXException;
- import org.xml.sax.SAXParseException;
- import org.xml.sax.XMLReader;
- import org.xml.sax.helpers.XMLReaderFactory;
-
- public class XMLParser {
- protected PrintStream output = new PrintStream(new BufferedOutputStream(
- new FileOutputStream(java.io.FileDescriptor.out), 128), true);
- // handler error info.
- protected PrintStream error = new PrintStream(new BufferedOutputStream(
- new FileOutputStream(java.io.FileDescriptor.err), 128), true);
-
- public void parserXMLFile(String fileName) throws SAXException, IOException {
- XMLReader reader = XMLReaderFactory.createXMLReader();
- reader.setContentHandler(new MyContentHandler());
- reader.setErrorHandler(new MyErrorHandler());
- InputSource source = new InputSource(new FileInputStream(new File(
- fileName)));
- reader.parse(source);
- }
-
- class MyErrorHandler implements ErrorHandler {
-
- public void error(SAXParseException exception) throws SAXException {
-
- error.println(exception.getMessage());
- }
-
- public void fatalError(SAXParseException exception) throws SAXException {
-
- error.println(exception.getMessage());
- }
-
- public void warning(SAXParseException exception) throws SAXException {
- output.println(exception.getMessage());
-
- }
-
- }
-
- class MyContentHandler implements ContentHandler {
-
- private StringBuffer buffer = new StringBuffer();
- private String key;
-
- public void characters(char[] ch, int start, int length)
- throws SAXException {
- buffer.append(ch, start, length); // 添加标记中间的内容
-
- }
-
- public void endDocument() throws SAXException {
-
- }
-
- public void endElement(String uri, String localName, String name)
- throws SAXException {
- if (key.equals(localName)) {
- output.print(buffer); // 输出标记中间的内容
- }
- output.print("</" + localName + ">");
- }
-
- public void endPrefixMapping(String prefix) throws SAXException {
- }
-
- public void ignorableWhitespace(char[] ch, int start, int length)
- throws SAXException {
- }
-
- public void processingInstruction(String target, String data)
- throws SAXException {
- }
-
- public void setDocumentLocator(Locator locator) {
- }
-
- public void skippedEntity(String name) throws SAXException {
- }
-
- public void startDocument() throws SAXException // XML文档开始读取时调用
- {
- output.println("<xml version=\"1.0\" encoding=\"utf-8\"?>");
- }
-
- public void startElement(String uri, String localName, String name,
- Attributes atts) throws SAXException // 获取标记开始信息
- {
- // uri is identifier of namespace
- // name-->prefix:localName
-
- buffer.delete(0, buffer.length());
- key = localName;
-
- output.print("<" + localName);
- for (int i = 0; i < atts.getLength(); i++) {
- String attrName = atts.getLocalName(i);
- String attrValue = atts.getValue(i);
- output.print(" " + attrName + "=" + attrValue);
- }
- output.print(">" + "\r");
- }
-
- public void startPrefixMapping(String prefix, String uri)
- throws SAXException {
- }
- }
-
- public static void main(String[] args) throws Exception, IOException {
- XMLParser parser = new XMLParser();
- parser.parserXMLFile("D:/testSpace/testPrj/src/xmlPackage/MyXml.xml"); // 解释XML文件
- }
- }
(4)SAX生成XML文档示例代码(生成XML)
package com.alisoft.facepay.framework.bean;
-
- import java.io.FileOutputStream;
- import java.io.StringWriter;
- import javax.xml.transform.OutputKeys;
- import javax.xml.transform.Result;
- import javax.xml.transform.Transformer;
- import javax.xml.transform.TransformerConfigurationException;
- import javax.xml.transform.sax.SAXTransformerFactory;
- import javax.xml.transform.sax.TransformerHandler;
- import javax.xml.transform.stream.StreamResult;
- import org.xml.sax.SAXException;
- import org.xml.sax.helpers.AttributesImpl;
-
- public class XMLHandler {
- public String createXMLFile() {
- String xmlStr = null;
- try {
- Result resultXml = new StreamResult(new FileOutputStream(
- "E://cities.xml"));
- StringWriter writerStr = new StringWriter();
- SAXTransformerFactory sff = (SAXTransformerFactory) SAXTransformerFactory
- .newInstance();
- TransformerHandler th = sff.newTransformerHandler();
- Transformer transformer = th.getTransformer();
- transformer.setOutputProperty(OutputKeys.INDENT, "yes");
- transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
- th.setResult(resultXml);
- th.startDocument();
- String four = "\n ";
- String eight = "\n ";
- AttributesImpl attr = new AttributesImpl();
- th.startElement("", "", "country", attr);
- th.characters(four.toCharArray(), 0, four.length());
-
- th.startElement("", "", "china", attr);
-
- th.characters(eight.toCharArray(), 0, eight.length());
-
- th.startElement("", "", "city", attr);
- String bj = "Beijing";
- th.characters(bj.toCharArray(), 0, bj.length());
- th.endElement("", "", "city");
-
- th.characters(eight.toCharArray(), 0, eight.length());
-
- th.startElement("", "", "city", attr);
- String sh = "Shanghai";
- th.characters(sh.toCharArray(), 0, sh.length());
- th.endElement("", "", "city");
-
- th.characters(four.toCharArray(), 0, four.length());
-
- th.endElement("", "", "china");
- th.endElement("", "", "country");
- th.endDocument();
- xmlStr = writerStr.getBuffer().toString();
- } catch (TransformerConfigurationException e) {
- e.printStackTrace();
- } catch (SAXException e) {
- e.printStackTrace();
- } catch (Exception e) {
- e.printStackTrace();
- }
- return xmlStr;
- }
-
- public static void main(String args[]) {
- XMLHandler xh = new XMLHandler();
- xh.createXMLFile();
- }
- }
生成的XML文档:
<?xml version="1.0" encoding="UTF-8" ?>
- <country>
- <china>
- <city>Beijing</city>
- <city>Shanghai</city>
- </china>
- </country>
3.DOM4J生成和解析XML文档
DOM4J 是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件。如今你可以看到越来越多的 Java 软件都在使用 DOM4J 来读写 XML,特别值得一提的是连 Sun 的JAXM 也在用 DOM4J。
(1)Dom4j解析XML文档所使用到的jar包:dom4j.jar
(2)Dom4j文档解释示例代码
package com.alisoft.facepay.framework.bean;
-
- import java.io.File;
- import java.io.FileWriter;
- import java.io.IOException;
- import java.io.Writer;
- import java.util.Iterator;
-
- import org.dom4j.Document;
- import org.dom4j.DocumentException;
- import org.dom4j.DocumentHelper;
- import org.dom4j.Element;
- import org.dom4j.io.SAXReader;
- import org.dom4j.io.XMLWriter;
-
- /**
- *
- * @author hongliang.dinghl Dom4j 生成XML文档与解析XML文档
- */
- public class Dom4jDemo implements XmlDocument {
-
- // Dom4j创建Xml文档
- public void createXml(String fileName) {
- Document document = DocumentHelper.createDocument(); // 创建一个文档对象
- Element employees = document.addElement("employees"); // 在根节点添加元素
- Element employee = employees.addElement("employee"); // 在employees下添加子节点
- Element name = employee.addElement("name"); // 在employee下添加子节点
- name.setText("ddvip"); // 给name节点添加内容
- Element sex = employee.addElement("sex");
- sex.setText("m");
- Element age = employee.addElement("age");
- age.setText("29");
- try {
- Writer fileWriter = new FileWriter(fileName);
- XMLWriter xmlWriter = new XMLWriter(fileWriter);
- xmlWriter.write(document);
- xmlWriter.close();
- } catch (IOException e) {
-
- System.out.println(e.getMessage());
- }
-
- }
-
- // Dom4j解释Xml文档
- public void parserXml(String fileName) {
- File inputXml = new File(fileName);
- SAXReader saxReader = new SAXReader();
- try {
- Document document = saxReader.read(inputXml);
- Element employees = document.getRootElement();
- for (Iterator i = employees.elementIterator(); i.hasNext();) {
- Element employee = (Element) i.next();
- for (Iterator j = employee.elementIterator(); j.hasNext();) { // 遍例节点
- Element node = (Element) j.next();
- System.out.println(node.getName() + ":" + node.getText());
- }
-
- }
- } catch (DocumentException e) {
- System.out.println(e.getMessage());
- }
- System.out.println("dom4j parserXml");
- }
- }
4.JDOM生成和解析XML
为减少DOM、SAX的编码量,出现了JDOM;优点:20-80原则,极大减少了代码量。使用场合:要实现的功能简单,如解析、创建等,但在底层,JDOM还是使用SAX(最常用)、DOM、Xanan文档。
(1)JDOM解析XML文档所使用到的jar包:jdom.jar
(2)JDOM文档解释示例代码
- package com.alisoft.facepay.framework.bean;
-
- import java.io.FileNotFoundException;
- import java.io.FileOutputStream;
- import java.io.IOException;
- import java.util.List;
-
- import org.jdom.Document;
- import org.jdom.Element;
- import org.jdom.JDOMException;
- import org.jdom.input.SAXBuilder;
- import org.jdom.output.XMLOutputter;
-
- /**
- *
- * @author hongliang.dinghl JDOM 生成与解析XML文档
- *
- */
- public class JDomDemo implements XmlDocument {
-
- public void createXml(String fileName) {
- Document document;
- Element root;
- root = new Element("employees");
- document = new Document(root);
- Element employee = new Element("employee");
- root.addContent(employee);
- Element name = new Element("name");
- name.setText("ddvip");
- employee.addContent(name);
- Element sex = new Element("sex");
- sex.setText("m");
- employee.addContent(sex);
- Element age = new Element("age");
- age.setText("23");
- employee.addContent(age);
- XMLOutputter XMLOut = new XMLOutputter();
- try {
- XMLOut.output(document, new FileOutputStream(fileName));
- } catch (FileNotFoundException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
-
- public void parserXml(String fileName) {
- SAXBuilder builder = new SAXBuilder(false);
- try {
- Document document = builder.build(fileName);
- Element employees = document.getRootElement();
- List employeeList = employees.getChildren();
- // 获取employee节点
- for (int i = 0; i < employeeList.size(); i++) {
- Element employee = (Element) employeeList.get(i);
- List employeeInfo = employee.getChildren();
- // 获取employee节点下面的所有子节点
- for(int j = 0; j < employeeInfo.size(); j++) {
- Element info = (Element)employeeInfo.get(j);
- System.out.println(info.getName() + ":" + info.getValue());
- }
- }
- } catch (JDOMException e) {
- System.out.println(e.getMessage());
- } catch (IOException e) {
- System.out.println(e.getMessage());
- }
- }
- }
比较
1)DOM4J性能最好,连Sun的JAXM也在用DOM4J.目前许多开源项目中大量采用DOM4J,例如大名鼎鼎的Hibernate也用DOM4J来读取XML配置文件。如果不考虑可移植性,那就采用DOM4J.
2)JDOM和DOM在性能测试时表现不佳,在测试10M文档时内存溢出。在小文档情况下还值得考虑使用DOM和JDOM.虽然JDOM的开发者已经说明他们期望在正式发行版前专注性能问题,但是从性能观点来看,它确实没有值得推荐之处。另外,DOM仍是一个非常好的选择。DOM实现广泛应用于多种编程语言。它还是许多其它与XML相关的标准的基础,因为它正式获得W3C推荐(与基于非标准的Java模型相对),所以在某些类型的项目中可能也需要它(如在JavaScript中使用DOM)。
3)SAX表现较好,这要依赖于它特定的解析方式-事件驱动。一个SAX检测即将到来的XML流,但并没有载入到内存(当然当XML流被读入时,会有部分文档暂时隐藏在内存中)。
Java解析XML的四种方法
标签:
原文地址:http://my.oschina.net/u/242764/blog/482685