标签:
1、zookeeper集群:
Java大型的项目中,环境变量的配置很重要,如果没有很好的配置环境变量的话,甚至项目连启动都是难事。
export ZOOKEEPER_HOME=/home/zookeeper-3.3.3
export PATH=$PATH:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf
(1)ZooKeeper的单机模式部署
ZooKeeper的单机模式通常是用来快速测试客户端应用程序的,在实际过程中不可能是单机模式。单机模式的配置也比较简单。
l 编写配置文件zoo.cfg
zookeeper-3.3.3/conf文件夹下面就是要编写配置文件的位置了。在文件夹下面新建一个文件zoo.cfg。ZooKeeper的运行默认是读取zoo.cfg文件里面的内容的。以下是一个最简单的配置文件的样例:
tickTime=2000
dataDir=/var/zookeeper
clientPort=2181
在这个文件中,我们需要指定 dataDir 的值,它指向了一个目录,这个目录在开始的时候需要为空。下面是每个参数的含义:
tickTime :基本事件单元,以毫秒为单位。这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
dataDir :存储内存中数据库快照的位置,顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
clientPort :这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
使用单机模式时用户需要注意:这种配置方式下没有 ZooKeeper 副本,所以如果 ZooKeeper 服务器出现故障, ZooKeeper 服务将会停止。
l 执行运行脚本
在zookeeper-3.3.3/bin文件夹下面运行zkServer.sh即可,运行完毕之后则ZooKeeper服务变启动起来。
./zkServer.sh start
脚本默认调用zoo.cfg里面的配置,因此程序正常启动。
(2)ZooKeeper的集群模式部署
ZooKeeper的集群模式下,多个Zookeeper服务器在工作前会选举出一个Leader,在接下来的工作中这个被选举出来的Leader死了,而剩下的Zookeeper服务器会知道这个Leader死掉了,在活着的Zookeeper集群中会继续选出一个Leader,选举出Leader的目的是为了可以在分布式的环境中保证数据的一致性。
确认集群服务器的数量
由于ZooKeeper集群中,会有一个Leader负责管理和协调其他集群服务器,因此服务器的数量通常都是单数,例如3,5,7...等,这样2n+1的数量的服务器就可以允许最多n台服务器的失效。
l编写配置文件
配置文件需要在每台服务器中都要编写,以下是一个配置文件的样本:
# Filename zoo.cfg
tickTime=2000
dataDir=/var/zookeeper/
clientPort=2181
initLimit=5
syncLimit=2
server.1=202.115.36.251:2888:3888
server.2=202.115.36.241:2888:3888
server.3=202.115.36.242:2888:3888
initLimit:这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 10 个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒。
syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2*2000=4 秒
server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
创建myid文件
除了修改 zoo.cfg 配置文件,集群模式下还要配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面就只有一个数据就是 A 的值,Zookeeper 启动时会读取这个文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是那个 server。
执行运行脚本
和单机模式下的运行方式基本相同,值得注意的地方就是要分别在不同服务器上执行一次,例如分别在251,241,242上运行:
./zkServer.sh start
这样才能使得整个集群启动起来。
2、Jenkins:
持续集成是个简单重复劳动,人来操作费时费力,使用自动化构建工具完成是最好不过的了。
为了实现这个要求,我选择了Jenkins。
从 http://mirrors.jenkins-ci.org/windows/latest下载windows下的最新安装版jenkins。(如果不 能安装,从http://mirrors.jenkins-ci.org/war/latest/jenkins.war下载war包,手动配置,配置说 明参见https://wiki.jenkins-ci.org/display/JENKINS/Use+Jenkins)。
1.安装
这里直接使用安装包,解压tomcat到某个目录,如/usr/local,进入tomcat下的/bin目录,启动tomcat
将jenkins.war文件放入tomcat下的webapps目录下,启动jenkins时,会自动在webapps目录下建立jenkins目录
Jenkins,默认使用的端口是8080,如果需要修改,打开安装目录下的jenkins.xml文件,修改 <arguments>-Xrs -Xmx256m -Dhudson.lifecycle=hudson.lifecycle.WindowsServiceLifecycle -jar "%BASE%\jenkins.war" --httpPort=8081</arguments>后保存,启动jenkins服务。
打开http://192.168.0.10:8081/,看到类似下面的界面(我这里已经创建了一个任务):
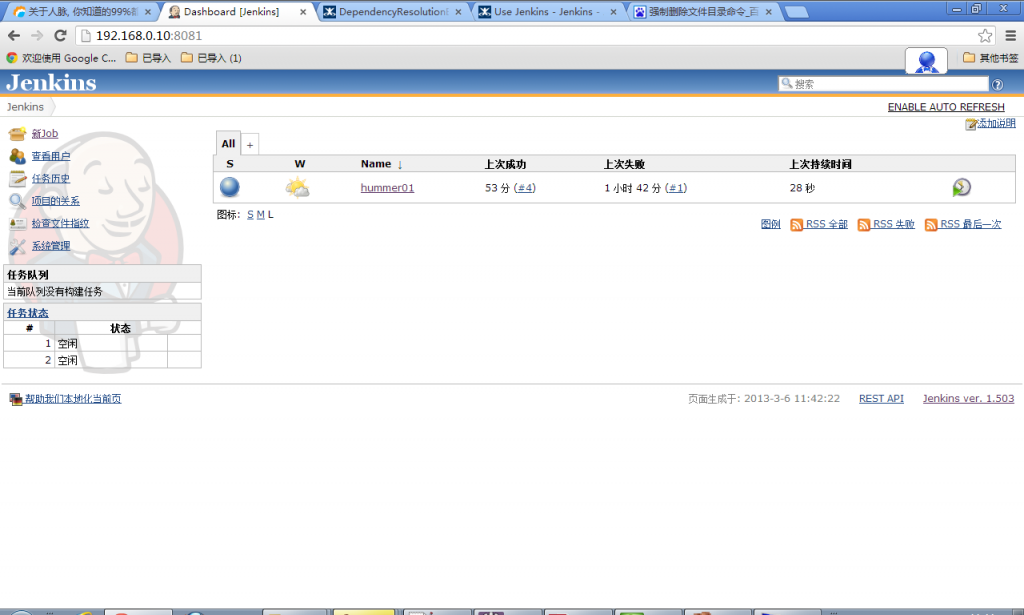
说明jenkins已经安装成功。
2. 创建任务
2.1 点“新Job”,界面如下:

输入任务名称,任意名称都可以,但最好是有意义的名称,这里输入的名称和项目名称相同为hummer
2.2 选择项目类型,因我的项目是maven项目,这里选择“构建一个maven2/3项目”点击”OK“进入下一个界面。
2.3 界面如下:

源代码管理根据自己的需要进行选择,我的源代码是使用svn管理的,这里选择“Subversion Modules”,在"Repository URL"录入你的svn仓库地址;第一次录入时还需要录入svn仓库的用户名和口令。
刚才的那个界面比较大,向下滚动,中间部分的界面如下:
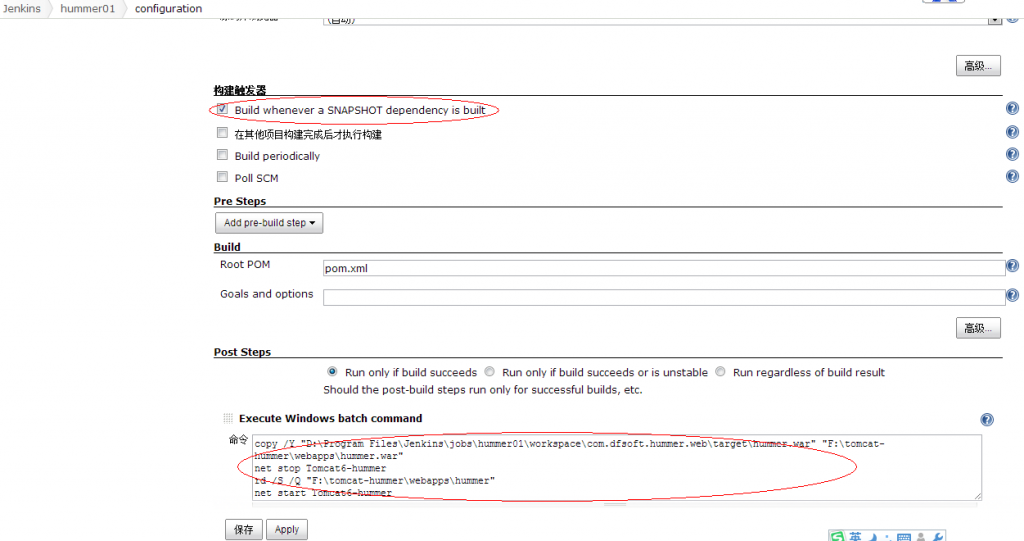
构建触发器,我选择“Build whenever a SNAPSHOT dependency is built”,意思是依赖于快照的构建,应该是当svn有修改时就构建项目。
2.4 build设置不用修改,就使用pom.xml,目标选项也不用修改。
2.5 设置构建后的步骤,(Post Steps,可选设置 ),我这里要求构建成功后把war文件复制到指定的目录,然后停运tomcat,删除项目web目录,启动tomcat。
2.6 设置邮件通知
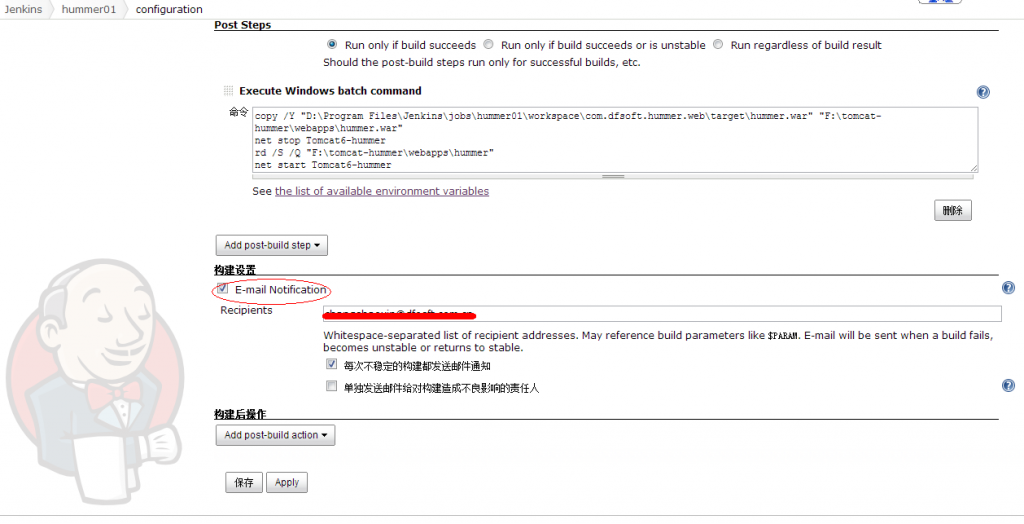
勾选“E-mail Notification”,在recipients中录入要接收邮件的邮箱。
点“保存”,完成设置
3. 在工作区域的左边菜单上点“立即构建”,开始构建项目,
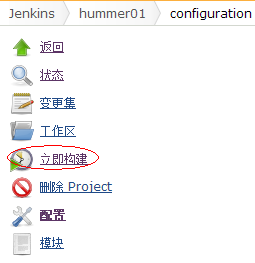
如果构建成功,则项目状态的S为蓝色,如果失败则为红色。

构建完成,左边菜单会显示有“控制台输出”,点击可以查看控制台详细输出。构建错误时也可以根据相应的错误信息进行修改。
【Linux 初学】zookeeper集群、win下Jenkins安装(三)
标签:
原文地址:http://my.oschina.net/xiaohai945/blog/482669