标签:
桶排序(Bucket sort)是一种基于计数的排序算法,工作的原理是将数据分到有限数量的桶子里,然后每个桶再分别排序(有可能再使用别的排序算法或是以递回方式继续使用桶排序进行排序)。当要被排序的数据内的数值是均匀分配的时候,桶排序时间复杂度为Θ(n)。桶排序不同于快速排序,并不是比较排序,不受到时间复杂度 O(nlogn) 下限的影响。
桶排序按下面4步进行:
桶排序,主要适用于小范围整数数据,且独立均匀分布,可以计算的数据量很大,而且符合线性期望时间。
举例来说,现在有一组数据[7, 36, 65, 56, 33, 60, 110, 42, 42, 94, 59, 22, 83, 84, 63, 77, 67, 101],怎么对其按从小到大顺序排序呢?
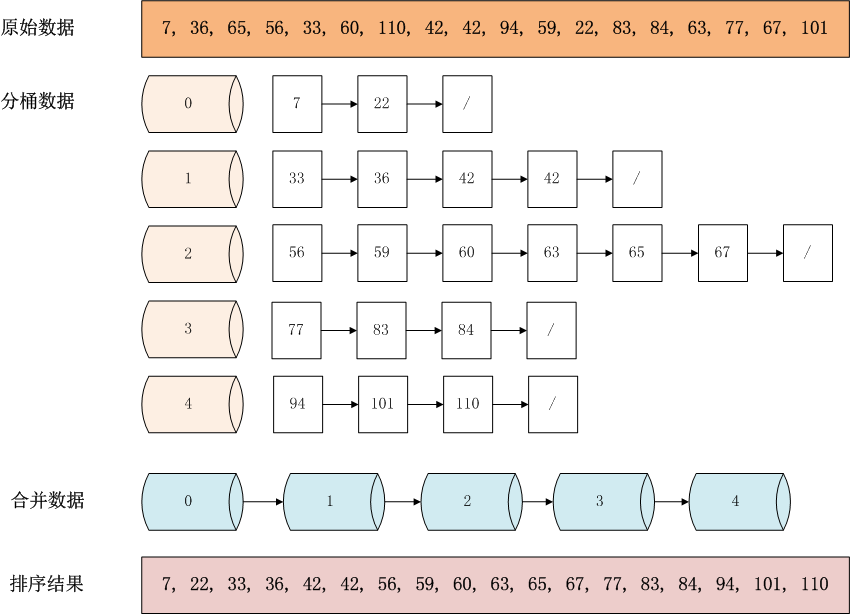
操作步骤说明:
3.桶排序c++代码实现
// 8-4.桶排序.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include "stdlib.h"
void bucketSort(double* a,int n)
{
//链表结点描述
typedef struct Node{
double key;
struct Node * next;
}Node;
//辅助数组元素描述
typedef struct{
Node * next;
}Head;
int i,j;
Head head[10]={NULL};
Node * p;
Node * q;
Node * node;
for(i=1;i<=n;i++){
node=(Node*)malloc(sizeof(Node));
node->key=a[i];
node->next=NULL;
p = q =head[(int)(a[i]*10)].next;
if(p == NULL){
head[(int)(a[i]*10)].next=node;
continue;
}
while(p){
if(node->key < p->key)
break;
q=p;
p=p->next;
}
if(p == NULL){
q->next=node;
}else{
node->next=p;
q->next=node;
}
}
j=1;
for(i=0;i<10;i++){
p=head[i].next;
while(p){
a[j++]=p->key;
p=p->next;
}
}
}
int _tmain(int argc, _TCHAR* argv[])
{
int i;
double a[13]={0,0.13,0.25,0.18,0.29,0.81,0.52,0.52,0.83,0.52,0.69,0.13,0.16};//不考虑a[0]
bucketSort(a,12);
for(i=1;i<=12;i++)
printf("%-6.2f",a[i]);
printf("\n");
return 0;
}
4.桶排序代价分析
桶排序利用函数的映射关系,减少了几乎所有的比较工作。实际上,桶排序的f(k)值的计算,其作用就相当于快排中划分,已经把大量数据分割成了基本有序的数据块(桶)。然后只需要对桶中的少量数据做先进的比较排序即可。
对N个关键字进行桶排序的时间复杂度分为两个部分:
(1) 循环计算每个关键字的桶映射函数,这个时间复杂度是O(N)。
(2) 利用先进的比较排序算法对每个桶内的所有数据进行排序,其时间复杂度为 ∑ O(Ni*logNi) 。其中Ni 为第i个桶的数据量。
很显然,第(2)部分是桶排序性能好坏的决定因素。尽量减少桶内数据的数量是提高效率的唯一办法(因为基于比较排序的最好平均时间复杂度只能达到O(N*logN)了)。因此,我们需要尽量做到下面两点:
(1) 映射函数f(k)能够将N个数据平均的分配到M个桶中,这样每个桶就有[N/M]个数据量。
(2) 尽量的增大桶的数量。极限情况下每个桶只能得到一个数据,这样就完全避开了桶内数据的“比较”排序操作。 当然,做到这一点很不容易,数据量巨大的情况下,f(k)函数会使得桶集合的数量巨大,空间浪费严重。这就是一个时间代价和空间代价的权衡问题了。
对于N个待排数据,M个桶,平均每个桶[N/M]个数据的桶排序平均时间复杂度为:
O(N)+O(M*(N/M)*log(N/M))=O(N+N*(logN-logM))=O(N+N*logN-N*logM)
当N=M时,即极限情况下每个桶只有一个数据时。桶排序的最好效率能够达到O(N)。
总结: 桶排序的平均时间复杂度为线性的O(N+C),其中C=N*(logN-logM)。如果相对于同样的N,桶数量M越大,其效率越高,最好的时间复杂度达到O(N)。 当然桶排序的空间复杂度 为O(N+M),如果输入数据非常庞大,而桶的数量也非常多,则空间代价无疑是昂贵的。此外,桶排序是稳定的。
我个人还有一个感受:在查找算法中,基于比较的查找算法最好的时间复杂度也是O(logN)。比如折半查找、平衡二叉树、红黑树等。但是Hash表却有O(C)线性级别的查找效率(不冲突情况下查找效率达到O(1))。大家好好体会一下:Hash表的思想和桶排序是不是有一曲同工之妙呢?
标签:
原文地址:http://www.cnblogs.com/hdk1993/p/4671806.html