标签:
一说到REST,我想大家的第一反应就是“啊,就是那种前后台通信方式。”但是在要求详细讲述它所提出的各个约束,以及如何开始搭建REST服务时,却很少有人能够清晰地说出它到底是什么,需要遵守什么样的准则。
在您将看到的这一篇文章中,我们将对REST,尤其是基于HTTP的REST服务进行详细地介绍。通过这些文章,您不仅可以了解到什么是REST,更能清晰地了解到您在编写REST服务时所需要遵守的各个守则,设计RESTful API时需要考虑的各种因素以及实现过程中可能遇到的问题等内容。
REST示例
我想,很多读者可能并不太清楚REST到底是一个什么概念。那么,首先让我们来看一个简单的基于HTTP的REST服务示例。
假设用户正在访问一个电子商务网站www.egoods.com。该网站对其所销售的各个物品进行了详细分类。当用户登录该网站进行购物时,他首先需要在该网站上选择其所需要寻找物品的分类,进而列出属于该分类的各个物品。
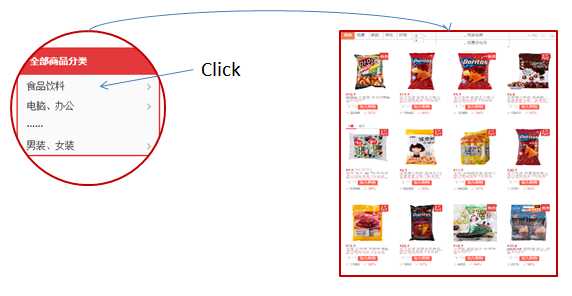
当然,虽然从业务逻辑的角度来说这个流程非常简单,但实际上浏览器向后台发送了多个请求:页面逻辑在页面加载时将首先得到所有的商品分类,并将这些分类显示在了页面中。在用户选择了一个分类的时候,页面逻辑将发送一个请求得到该分类的详细信息,并发送另外一个请求来得到该分类的商品列表:
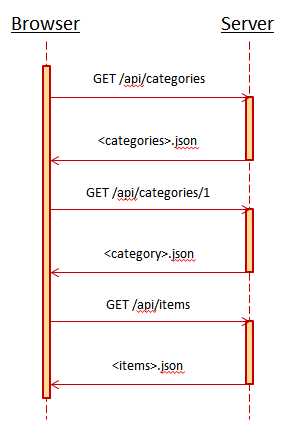
在通过浏览器的调试功能查看这些请求的时候,我们可以看到其首先向www.egoods.com/api/categories发送一个GET请求,以取得所有的商品分类:
1 GET /api/categories 2 Host: www.egoods.com 3 Authorization: Basic xxxxxxxxxxxxxxxxxxx 4 Accept: application/json
而服务端将返回所有的类别:

1 HTTP/1.1 200 OK
2 Content-Type: application/json
3 Content-Length: xxx
4
5 [
6 {
7 "label" : "食品",
8 "url" : "/api/categories/1"
9 }, {
10 "label" : "服装",
11 "url" : "/api/categories/2"
12 }
13 ...
14 {
15 "label" : "电子设备",
16 "url" : "/api/categories/25"
17 }
18 ]
该响应返回了一个用JSON表示的数组。该数组中的每个元素包含了两部分信息:用户能够读懂的表示分类名称的label以及相应分类所对应的URL。其中Label所记录的分类名称将在页面中显示给用户。而在用户根据label所标示的分类名选择了一个分类的时候,页面逻辑会取得该分类所对应的URL并向该URL 发送请求,以得到该分类的详细信息。例如在用户点击了“食品”这个分类的时候,浏览器将会向服务器发送如下的请求:
1 GET /api/categories/1 2 Host: www.egoods.com 3 Authorization: Basic xxxxxxxxxxxxxxxxxxx 4 Accept: application/json
这一次,页面逻辑根据用户对分类的选择“食品”来得到了其所对应的URL,并向该URL发送了一个GET请求。而该请求所得到的响应则为:
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: xxx
{
"url" : "/api/categories/1",
"label" : "Food",
"items_url" : "/api/items?category=1",
"brands" : [
{
"label" : "友臣",
"brand_key" : "32073",
"url" : "/api/brands/32073"
}, {
"label" : "乐事",
"brand_key" : "56632",
"url" : "/api/brands/56632"
}
...
],
"hot_searches" : …
}
该响应略为复杂。首先,响应中的URL标示了“食品”分类所对应的URL。而label属性则和前面一样,用来在页面上显示分类的名称。一个较为特殊的属性则是items_url。其用来标示获取属于食品分类的各个产品的URL。而属性brands则用来列出在“食品”分类中的著名品牌,例如友臣,乐事等。这些品牌被组织为一个对象数组,而数组中的每个对象都拥有label,url等属性。在这些属性的帮助下,页面可以列出这些著名品牌的名称,并允许用户通过点击跳转到这些品牌所对应的页面上。除了这些属性之外,Food分类还包含了其它一系列属性,如表示当前其它用户正在搜索的hot_searches属性等,这里就不再赘述。
该响应有一个问题,那就是符合用户筛选条件的各个产品并没有包含在该响应中。这是因为页面所列出的各个产品是根据用户所设置的筛选条件,即其选择的品牌以及搜索关键字而变化的。因此,页面逻辑会根据属性items_url以及用户所设定的搜索条件组合成为目标URL,再次发送请求到后台,以请求需要在页面中展现的各个物品。
例如用户在只想浏览属于乐事品牌的食品时,其可以钩选乐事这个品牌,那么此时的URL将由食物分类的items_url以及表示按照品牌进行筛选的URL参数共同组成:
1 GET /api/items?category=1&brand_key=56632 2 Host: www.egoods.com 3 Authorization: Basic xxxxxxxxxxxxxxxxxxx 4 Accept: application/json
现在让我们来总结一下上面所展示的基于HTTP的REST系统的整个运行流程。在开始的时候,我们拿到了所有分类的列表。列表中的各个条目不仅仅包含了用户可以看到的分类名称等信息,更拥有一个额外的URL属性。在用户选择该列表中的一项时,页面逻辑将会向对应的URL发送一个请求,以获得该项目的详细信息。在这个详细信息中,一些内容又包含了一些其它的URL,从而使得页面逻辑又能通过该URL属性发送请求。
您也许会说,哎,这不和我们现有系统的运行流程一样的嘛。是的。在上面所举出的例子中,我们也更偏重地描述了REST系统所需要具有的HATEOAS(Hypermedia As The Engine Of Application State)特性。正是由于这个特性已经在大家所创建的系统里面广泛地使用了,因此我更希望从熟悉的地方入手,而不是开始就非常教条地说REST一定要这样,一定要那样,徒增了学习的难度。
反过来说,上面所展示的REST服务并不具有典型性。在充分了解了REST后,您会发现,REST在系统设计上的视角将不再把流程放在了最优先的位置。
而在后面的章节中,我们则会逐渐展开,详细地介绍如何创建一个纯正的基于HTTP的REST服务。
REST的定义
OK,现在让我们来看看REST的定义。Wikipedia是这样描述它的:
Representational State Transfer (REST) is a software architecture style consisting of guidelines and best practices for creating scalable web services. REST is a coordinated set of constraints applied to the design of components in a distributed hypermedia system that can lead to a more performant and maintainable architecture.
从上面的定义中,我们可以发现REST其实是一种组织Web服务的架构,而并不是我们想象的那样是实现Web服务的一种新的技术,更没有要求一定要使用HTTP。其目标是为了创建具有良好扩展性的分布式系统。
反过来,作为一种架构,其提出了一系列架构级约束。这些约束有:
如果一个系统满足了上面所列出的五条约束,那么该系统就被称为是RESTful的。
下面我们再次通过电子商务网站egoods这个示例来帮助我们理解这些约束。首先,egoods是一个电子商务网站。用户需要通过浏览器,手机或者网站所发布的浏览应用来访问该网站的内容。因此其使用的自然是客户/服务器模型。而在浏览过程中,用户需要访问不同类型的数据,如商品描述、购物车等信息。这些信息可能由egoods网站服务中不同的服务器来提供的,因此在用户浏览过程中可能需要与不止一个服务器进行交互。如果在服务端保存了有关客户的任何状态,那么在用户与不同服务器进行交互的时候,客户的状态就需要在这些服务之间进行同步,大大地增加了系统的复杂度。因此,REST要求客户端自行维护状态,并在每次发送请求的时候提供自身所储存的处理该请求所必需的信息。而恰当地使用缓存这一条也非常容易理解。在客户端请求一个自上次请求后没有发生过变化的信息时,如产品分类列表,服务端仅仅需要返回一个304响应即可。
这里您可以看到,前四条约束中除了无状态这条约束较为特别之外,其它三条约束在基于HTTP的Web服务中都很常见,也较容易达成。而无状态约束在其它类型的Web服务中并不十分常见,因此如何避免违反该约束是在实现REST服务时最常讨论的话题。其不仅仅会影响到很多功能的设计,更是REST系统扩展性的关键。因此在后面的章节中,我们会对无状态约束单独进行讲解。
在简单地介绍了前四个约束之后,我们就需要着重讲解统一接口这个约束了。可以说,前面的四个约束实际上都较为容易达成。唯一需要注意的无非是是否某些技术实现违反了这些约束。而第五条约束,统一接口,可以说是REST服务设计的核心所在,也是决定REST服务设计的成败之处。在实现一个基于HTTP的REST服务时,软件开发人员不仅仅需要考虑REST所设置的一系列约束,更需要考虑HTTP各组成的语意,HTTP相关技术如何与REST服务约束结合,如何保持前后向兼容性以及如何进行版本管理等问题,才能给出一个自然的,具有较高易用性和较强生命力的REST系统。
而在介绍统一接口约束之前,我们则需要了解一下和REST密切相关的两个名词:资源和状态。可以说,资源是REST系统的核心概念。所有的设计都会以资源为中心,包括如何对资源进行添加,更新,查找以及修改等。而资源本身则拥有一系列状态。在每次对资源进行添加 ,删除或修改的时候,资源就将从一个状态转移到另外一个状态。
比如说,在egoods中,商品的分类就是一种资源。该资源有很多实例,包括表示食品的分类,其所对应的URL是“/api/categories/1”。同样地,食品的品牌也是一种资源。这些资源的实例都对应着一个当前的状态。在修改了一个资源实例之后,比如修改了食品分类中的热搜关键字,那么其将对应着一个新的状态。这种状态之间的变化被称为是状态的转移。
在大概了解了REST系统中的资源和状态的定义后,我们来看看统一接口这个约束。该约束又包含了四个子约束:
现在,让我们仍然以egoods作为示例来解释一下上面四个子约束。
在前面的章节中,我们已经看到了从egoods所返回的表示食品这个分类的响应:
1 HTTP/1.1 200 OK
2 Content-Type: application/json
3 Content-Length: xxx
4
5 {
6 "url" : "/api/categories/1",
7 "label" : "Food",
8 "items_url" : "/api/items?category=1",
9 "brands" : [
10 {
11 "label" : "友臣",
12 "brand_key" : "32073",
13 "url" : "/api/brands/32073"
14 }, {
15 "label" : "乐事",
16 "brand_key" : "56632",
17 "url" : "/api/brands/56632"
18 }
19 ...
20 ],
21 "hot_searches" : …
22 }
首先我们看到的是,该响应通过Content-Type响应头来标示响应中所包含的信息是按照JSON格式来组织的。在看到了该响应头中所标示的格式之后,消息的接收方就可以按照JSON的格式理解或分析该响应中的负载。这也便是消息的自描述性。
当然,消息的自描述性不仅仅包含如何解析其所携带的负载。在一个基于HTTP的REST系统中,我们可以通过使用大部分HTTP标准所提供的功能来提高消息的自描述性。由于这些功能已经拥有了完备的文档,被广大的软件开发人员所熟知,并得到了众多浏览器厂商以及Web类库的支持,因此根据这些标准实现REST服务具有较高的消息自描述性。举例来说,如果在请求中标明了If-Modified-Since头,那么服务端将可能返回一个304 Not Modified响应。在看到该响应的时候,浏览器或其它浏览工具可以从缓存中取得上一次得到的结果。因此,在一个基于HTTP的REST系统中,如何准确地使用HTTP协议是一项非常重要的内容。
在获知了如何对响应所携带的负载进行解析之后,我们就来看看资源的自描述性。在上面的示例中,服务端响应使用了JSON表示了食品分类。该表示首先通过label属性描述了自己是一个什么分类。接下来,其通过brands属性表示了该分类中的著名品牌,并通过hot_searches标示了在该分类中的热搜关键字。可以看到,该负载中的所有属性都清晰地描述了自身所表达的含义。
那在该资源表示中的url属性是什么意思?实际上这是为子约束“每个资源都拥有一个资源标识”所添加的一个属性。该子约束要求每个资源的资源标识可以用来唯一地标明该资源。对于网络应用来说,资源标识就是URI。而在一个基于HTTP的系统中,最自然的资源标示便是URL。在表示单个资源的时候,这个URL常常会包含着资源在该类资源中的ID。
在本文的其它章节中,我们就将以这种方式来区分URL和ID:URL用来指向资源所在的地址,而ID则表示该资源在该类型资源中的ID。请读者一定要记得这两个术语所对应的不同意义,以防止理解错误。
现在还有一部分食品分类表示中的属性没有被讲解,那就是在该表示中的各个URL。这是为子约束HATEOAS服务的。在用户看到items_url属性时,其就可以通过向该URL发送GET消息得到属于食品分类中的所有商品的列表。而在商品品牌的表示中也拥有一个url属性。也就是说,向该URL发送一个GET请求也能够得到相应品牌的详细信息。
您可能会问:既然在介绍HATEOAS时说REST服务并不需要文档来告诉用户哪里拥有什么样的资源,那用户应该如何知道向/api/categories发送GET请求就能得到所有的分类呢?标准的做法则是向/api直接发送一个GET请求:
1 GET /api 2 Host: www.egoods.com 3 Authorization: Basic xxxxxxxxxxxxxxxxxxx 4 Accept: application/json
而在返回的响应中将标示出REST API的版本以及所有可以访问的资源等信息:
1 HTTP/1.1 200 OK
2 Content-Type: application/json
3 Content-Length: xxx
4
5 {
6 "version": "1.0",
7 "resources": [
8 {
9 "label" : "Categories",
10 "description" : "Product categories",
11 "uri": "/api/categories"
12 }, {
13 "label" : "Items",
14 "description" : "All items on sell",
15 "uri": "/api/items"
16 }
17 ]
18 }
可以看到,在该响应中列出了可以被访问的两种资源:表示商品分类的Categories以及表示商品的Items。在需要访问特定类型的资源时,软件开发人员可以通过直接向这两种资源所对应的URI发送GET请求即可。
OK,相信现在读者已经了解了REST服务所提供的各种约束。那么在后面的章节中,我们将会逐步讲解如何设计一个基于HTTP的REST服务。
资源识别
在一般情况下,对资源的识别通常都是REST服务设计的第一步。在准确地识别出了各资源之后,怎么用HTTP规范中的各组成来表示这些资源便是顺理成章的事情。在本节中,我们将对如何识别REST系统中的资源进行讲解。
在通常的软件开发过程中,我们常常需要分析达成某个目标所需要使用的业务逻辑,并为业务逻辑的执行提供一系列运行接口。在一些Web服务中,这些接口常常表达了某个动作,如将商品放入购物车,提交订单等。这一系列动作组合在一起就可以组成完成目标所需要执行的业务逻辑。在需要调用这些接口的时候,软件开发人员需要向这些接口所在的URL发送一个请求,从而驱使服务执行该动作。
而在REST服务中,我们所提供的各个接口则需要是一系列资源,而业务逻辑需要通过对资源的操作来完成。也就是说,REST服务中的API将不再以执行了什么动作为中心,而是以资源为中心。一些对资源的通用操作有添加,取得,修改,删除,以及对符合特定条件的资源进行列表操作。
仍然让我们以上面所举的“将商品放入购物车”这个操作为例。在一个REST系统中,购物车将被抽象为一个资源,而“将商品放入购物车”这个操作将被解释为对购物车这个资源的更新:更新购物车,以使特定商品包含在购物车内。
可能对于刚刚学习REST的各位读者而言,这种以资源为中心的描述方法有些别扭。这种描述方法的确有别于很多Web服务那样以动作为中心。而与之对应的则是系统设计步骤的改变:我们将不再首先是别完成业务逻辑所需的各动作,而是支持业务逻辑所需要的各资源。那么我们应该如何抽象出这些资源呢?首先,我们对某个操作不要再关注它所执行的动作,而是关心它所操作的宾语。通常情况下,该宾语就会是REST系统中的资源。
在这里,我们就以“提交订单”作为示例来展示如何抽象资源。
首先,在“提交订单”这个动作中,订单是宾语。因此对于该业务逻辑,其将作为一个资源存在。除此之外,在订单中还需要包含一系列信息,例如订单中所包含的商品,订单所属人等。一旦这些都可以被该REST系统中的其它资源使用,那么它们也将成为独立的资源。
但是有时候,一个动作可能并不存在着它所操作的宾语。在这种情况下,我们就需要考虑该动作产生或消除了哪个实体,或者哪个实体的状态发生了变化。这个发生了变化的实体实际上就是一种资源。例如对于登陆这一行为,其实际上在服务端创建了一个会话实例。该会话实例中则包含了登陆IP,登陆时间,以及登陆时所用的凭证等。再比如对于用户更改密码这种行为,其所操作的资源就是用户资料。
在抽象资源的过程中,我们需要按照自顶向下的方式,即首先辨识出系统中的最主要资源,然后再辨识这些主要资源的子资源,并依次进行迭代。
对主资源的抽取主要通过分析业务逻辑来完成。在得到功能需求以后,我们首先要分析这些业务逻辑所操作的宾语。这些宾语可能有两种情况:主资源或者其它资源的子资源。主资源实际上就是能够独立存在的一系列资源。而子资源则需要依附于主资源之上才能表达实际的意义。同时各个子资源也可能拥有自身的子资源。
判断一个资源是否是子资源的一个方法就是看它是否能独立地表示其具体含义。例如对于一个egoods上所销售的商品,其名称,价格,简介等属性可以清晰地描述该商品到底是什么,到底如何销售。因此这些商品实际上是一个主资源。但是每种商品所支持的邮递服务需要是一个子资源:一个商品可以支持多种邮递服务。这些邮递服务根据派送距离等需要不同的价格,也提供了不同的邮递速度。由于这些邮递服务与商家和邮递服务公司所达成的服务价格有关,并且会由于商品重量的变化而变化,因此这些邮递服务并不能为其它商家所提供的邮递服务作为参考,因此其应该作为该商品的一个子资源。
或者也可以说,如果一个资源是主资源,那么其可以被不同的资源实例包含引用而不会产生歧义。而如果一个资源是子资源,那么被不同的资源实例引用可能会产生歧义。
但是需要注意的是,一种资源可能有多种不同的表现形式。例如对于在使用列表展示各个商品的时候,egoods只需要展示商品的名称,一个对该商品的简单描述,商品的价格以及一张商品的照片。而在用户打开了该商品页之后,页面则需要显示更详尽的信息,如商品的重量,商品所在地等等。
除此之外,资源列表也有可能拥有多种不同的表现形式。举例来说,如果egoods上属于某个分类的商品太多,需要分页显示,那么这种分页是否也应该是一种资源?答案是,这些分页并不是一种资源,而其只是资源列表的一种表现方式。在每页所包含商品数量,排序规则等条件发生变化的时候,该资源列表中所包含的各个商品也会发生变化。
那么如何判断我们为REST服务所定义的资源是否合理呢?一般情况下,我都使用下面的一些判断方法:
首先,我们需要考虑对该资源的CRUD是否有意义,从而验证资源的定义是否合理。就以刚刚说到的列表的分页显示为例,我们可以想象一下如何对分页进行添加和删除?一旦删除了该分页,那么属于该分页中的各个商品也应该被删除么?而且删除了分页X的数据后,原本X + 1分页的数据将展示在X分页中。很显然,将商品的分页定义为资源并不合理。
其次,我们需要检查资源是否需要除CRUD之外的动词来操作。该方法用来检查资源中是否还有子资源没有被抽象。如果该资源还需要额外的动词,那么我们就需要考虑这些操作到底引起了什么样的状态变化,进而抽象出该资源的子资源。
除此之外,我们还需要检查这些资源是否是被整体使用,创建和删除。该方法用来探测是否一个子资源应该是一个主资源。如果在删除一个资源的时候,其子资源还可以被其它资源重用,那么该子资源实际上具有较高的重用性,应该是一个主资源。
资源的URL设计
在前面已经提到过,统一接口约束中的第一条子约束就是每个资源都拥有一个资源标识。在正确地辨识出了一个资源之后,我们就需要为这些资源分配其所对应的URI。一个资源所对应的URI可能有多种表示方式,如到底是用单数还是复数表示资源等。因此在一个基于HTTP的REST系统中,如何组织针对各个资源的URL实际上是最重要的一部分。毕竟一个明确的,有意义并且稳定的API接口实际上是对服务对用户的一种承诺。
在HTTP中,一个URL主要由以下几个部分组成:
在为一个资源设计其所对应的URL时,我们需要着重考虑第三部分和第四部分组成。
通过URL来表示资源
在辨识出了REST系统中的各个资源以后,我们就需要开始为这些资源设计各自所对应的URL了。
首先要介绍的是,所有的资源都应该存在于一个相对路径之下。请读者回忆之前我们介绍的通过向/api发送一个GET请求得到所有可以被访问的资源这个示例:
1 GET /api
2 Host: www.egoods.com
3 Authorization: Basic xxxxxxxxxxxxxxxxxxx
4 Accept: application/json
5
6 HTTP/1.1 200 OK
7 Content-Type: application/json
8 Content-Length: xxx
9
10 {
11 "version": "1.0",
12 "resources": [
13 {
14 "label" : "Categories",
15 "description" : "Product categories",
16 "uri": "/api/categories"
17 }, {
18 "label" : "Items",
19 "description" : "All items on sell",
20 "uri": "/api/items"
21 }
22 ]
23 }
因此对于从向该相对路径发送请求才能得到的各个主资源来说,将它们置于相对路径/api之下是非常合理的。
除了这个原因之外,API的版本更迭也是一个考虑。假如软件开发人员需要开发一个新版本的REST API,那么他可能就需要重新抽象并定义系统中的各个资源。但是如果两个版本的API中都拥有一个categories资源,并且系统为了保持后向兼容性同时保留了两个版本的API,那么将只有一个资源可以使用/categories这个相对路径。也正因为如此,将这些资源置于相对路径/api之下,并在第二个版本的API出现之后将新的资源抽象置于/api-v2下是一种较为流行的做法。
在明确了所有的资源都应该置于/api这样一个相对路径下之后,我们就来讲解如何为资源定义对应的URL。一个最简单的情况是:指定主资源所对应的URL。由于主资源是一类独立的资源,因此它应该直接置于/api下。例如egoods网站中的产品分类就是一个主资源,我们会为其分配如下URL:
1 /api/categories
而对于其它主资源,如egoods网站中的产品,我们也会为其赋予一个具有类似结构的URL:
1 /api/items
这样,每类主资源都将拥有一个特定于该类资源的URL。这些URL就对应着相应资源实例的集合。
如果需要表示某个主资源类型中的特定实例,那么我们就需要在该类主资源所对应的URL之后添加该实例的ID。如egoods网站中的食品分类的ID为1,那么其所对应的URL就将是:
1 /api/categories/1
一个较为特殊的情况则是,对于某种类型的主资源,整个系统将有且仅有一个该类型资源的实例。那么该资源将不再需要通过ID来访问。我能想到的一个例子就是对整个系统进行介绍的资源。该资源实例所对应的URL将是:
1 /api/about
而一个资源实例中还可能拥有子资源。这些子资源与资源实例之间的关系主要有两种情况:资源实例包含了一个子资源的集合,以及资源实例仅仅可以包含一个子资源。对于资源实例包含了一个子资源集合的情况,我们需要将该子资源集合的URL置于该资源的相对路径下。例如对于egoods上所销售的ID为23456的商品所提供的邮递服务,我们将使用如下的URL:
1 /api/items/23456/shipments
在该URI中,/api/items/23456对应的就是商品本身,而该商品所提供的邮递服务则是该商品的子资源。与主资源特定实例所具有的URI类似,其中一个ID为87256的邮递服务所对应的URI则为:
1 /api/items/23456/shipments/87256
如果资源实例仅仅可以包含一个子资源,那么对该子资源的访问也将不再需要ID。如当前商品的折扣信息:
1 /api/items/23456/discount
单数 vs. 复数
接下来要考虑的一点是,资源在URL中需要由单数表示还是复数表示?这在stackoverflow等众多论坛上已经成为了一个经久不衰的话题。我们知道,在一个基于HTTP的REST系统中,一个资源所对应的URL实际上也就是对其进行操作的URL。因此适当地使用单数和复数对于该系统的用户而言有一定的指示作用。在stackoverflow上的一个常见观点是:如果一个URL所对应的资源是使用复数表示的,那么该类型的资源可能有多个。对该URL发送Get请求可能返回该资源的一个列表。反之,如果一个URL所对应的资源是使用单数表示的,那么该类型的资源将只有一个,因此对该URL发送Get请求将只返回该资源的一个实例。
以egoods中的商品分类为例。由于一个网站所售卖的商品可能有多种类别,因此其需要在URL中使用复数形式:/api/categories。而对于一个该网站的用户而言,由于其只会有一个个人偏好设置,因此其URL则需要使用单数形式:/api/users/{user_id}/preference。
你可能会问:如果需要得到具有特定ID的某个实例时,我们应该对该资源使用单数还是复数呢?答案是复数。这是因为在通过特定ID访问某个资源的实例实际上就是从该资源的集合中取出特定实例。因此表示该资源集合的URL实际上仍然需要使用复数形式,而其后所使用的ID则标明了其所访问的是资源中的单一实例,因此向这个URL发送Get请求将返回该资源的单一实例。
就以“食品”分类为例。该分类所对应的URL为/api/categories/1。该URL中的前半部分/api/categories表示egoods网站中所有分类的集合,而1则表示在该分类集合中的ID为1的分类。
相对路径 vs. 请求参数
另一个经常导致疑惑的地方就是针对资源的某一种特征,我们到底是将其定义为URL中相对路径的一部分还是作为请求参数。
请考虑下面一个例子。在egoods网站中,我们售卖的手机主要有苹果,三星等品牌。那么在为这些手机设计URL的时候,我们是否需要按照品牌对这些手机进行细分,从而用户只要通过向/api/mobiles/brands/apple发送请求就能列出所有的苹果手机?还是说,直接将手机的品牌置于请求参数中,从而通过/api/mobiles?brand=apple来列出所有的苹果手机?
在判断到底是使用请求参数还是相对路径时,我们一般分为下面几步。
首先,可选参数一般都应置于请求参数中。仍以egoods中的手机为例。在选择手机时,用户可以选择品牌以及颜色。如果将品牌和颜色都定义在相对URL中,那么具有特定品牌和颜色的手机将可以通过两个不同的URL访问:/api/mobiles/brand/{brand}/color/{color}以及/api/mobiles/color/{color}/brand/{brand}。就用户而言,其并无法了解这两个URL所表示的是同一类资源还是不同类型的资源。当然,您可以说,我们只用/api/mobiles/brand/{brand}/color/{color}。但是该URL将无法处理用户仅仅选择了颜色,却没有选择品牌的情况。
其次,不是所有字符都可以在URL中被使用,如汉字,标点。为了处理这种情况,包含这些字符的筛选条件需要置于请求参数中。
最后,如果该特征下包含子资源,那么它自身也就是一个资源,因此需要以相对路径的方式展现它。例如在egoods网站中,每件商品所属于的分类仅仅是它的一个特征。但是一个分类更包含了属于它的各个品牌以及热搜关键字等众多信息。因此它其实是一个资源,需要在URI路径中表示它。
总的来说,既然使用HTTP来构建REST系统,那么我们就需要遵守URL各组成中的含义:URL中的相对路径将用来标示“What I want”,也既对应着资源;而请求参数则用来标示“How I want”,即查看资源的方式。
使用合适的动词
在知道了如何为每种资源定义URI之后,我们来看看如何操作这些资源。
首先,在一个资源的生命周期之内常常会发生一系列通用事件(CRUD)。一开始,一个资源并不存在。只有用户或REST服务创建了该资源以后其才存在,也即是上面所列出的通用事件中的C,Create。在一个资源创建完毕以后,用户可能会从服务端请求该资源的表示,也就是上面所列出的通用事件的R,Retrieve。在特定情况下,用户可能决定要更新该资源,因此会使用上面的通用事件中的U,即Update来更新资源。而在资源不再需要的时候,用户可能需要通过通用事件D,即Delete来删除该资源。同时用户有时也需要列出属于特定类型资源的资源实例,即通过List操作来得到属于特定类型的资源的列表。
在前面的讲解中我们已经提到过,在REST系统中的每个资源都有一个特定的URI与之对应。HTTP协议提供了多种在URI上操作的动词,如GET,PUT,POST以及DELETE等。因此在一个基于HTTP的REST服务中,我们需要使用这些HTTP动词来表示如何对这些资源进行CRUD操作。而在什么情况下到底使用哪个动词则是由这些动词本身在HTTP协议中的意义所决定的。
这其中GET和DELETE两个动词的含义较为清晰:
The GET method means retrieve whatever information (in the form of an entity) is identified by the Request-URI.
The DELETE method requests that the origin server delete the resource identified by the Request-URI.
也就是说,在需要读取某个资源的时候,我们向该资源所对应的URI发送一个GET请求即可。类似的,在需要删除一个资源的时候,我们只需要向该资源所对应的URI发送一个DELETE请求即可。而在希望得到某类型资源的列表的时候,我们可以直接向该类型资源所对应的URI发送一个GET请求。
而动词PUT和POST则是较为容易混淆的两个动词。在HTTP规范中,POST的定义如下所示:
The POST method is used to request that the origin server accept the entity enclosed in the request as a new subordinate of the resource identified by the Request-URI in the Request-Line
也就是说,POST动词会在目标URI之下创建一个新的子资源。例如在向服务端发送下面的请求时,REST系统将创建一个新的分类:
1 POST /api/categories
2 Host: www.egoods.com
3 Authorization: Basic xxxxxxxxxxxxxxxxxxx
4 Accept: application/json
5
6 {
7 "label" : "Electronics",
8 ……
9 }
而PUT的定义则更为晦涩一些:
The PUT method requests that the enclosed entity be stored under the supplied Request-URI. If the Request-URI refers to an already existing resource, the enclosed entity SHOULD be considered as a modified version of the one residing on the origin server. If the Request-URI does not point to an existing resource, and that URI is capable of being defined as a new resource by the requesting user agent, the origin server can create the resource with that URI."
也就是说,PUT则是根据请求创建或修改特定位置的资源。此时向服务端发送的请求的目标URI需要包含所处理资源的ID:
1 POST /api/categories/8fa866a1-735a-4a56-b69c-d7e79896015e
2 Host: www.egoods.com
3 Authorization: Basic xxxxxxxxxxxxxxxxxxx
4 Accept: application/json
5
6 {
7 "label" : "Electronics",
8 ……
9 }
可以看到,两者都有创建的含义,但是意义却不同。在决定到底是使用PUT还是POST来创建资源的时候,软件开发人员需要考虑一系列问题:
首先就是资源的ID是如何生成的。如果希望客户端在创建资源的时候显式地指定该资源的ID,那么就需要使用PUT。而在由服务端为该资源自动赋予ID的时候,我们就需要在创建资源时使用POST。在决定使用PUT创建资源的时候,防止资源URI与其它资源所具有的URI重复的任务需要由客户端来保证。在这种情况下,客户端常常使用GUID/UUID作为将资源的ID。但是到底使用GUID/UUID还是由服务端来生成ID不仅仅和REST有关,更会对数据库性能等多个方面产生影响。因此在决定使用它们之前要仔细地考虑清楚。
同时需要注意的是,因为REST要求客户只可以通过服务端返回结果中所包含的信息来得到下一步操作所需要的信息,因此客户端仅仅可以决定资源的ID,而URI中的其它部分则需要从之前得到的响应中取得。
但是软件开发人员常常会进入另外一个误区很多人认为REST服务中的HATEOAS只能通过Hyperlink完成。实际上在Roy对REST的定义中使用的是Hypermedia,即响应中的所有多媒体信息。就像Roy在其个人网站上所说(http://roy.gbiv.com/untangled/2008/rest-apis-must-be-hypertext-driven):
A REST API must not define fixed resource names or hierarchies (an obvious coupling of client and server). Servers must have the freedom to control their own namespace. Instead, allow servers to instruct clients on how to construct appropriate URIs, such as is done in HTML forms and URI templates, by defining those instructions within media types and link relations.
另外一个需要考虑的因素则是PUT的等幂性是否对REST系统的设计有所帮助。由于在同一个URI上调用两次PUT所得到的结果相同。因此用户在没有接到PUT请求响应时可以放心地重复发送该响应。这在网络丢包较为严重时是一个非常好的功能。反过来,在同一个URI上调用两次POST将可能创建两个独立的子资源。
除此之外,还需要考虑是否将资源的创建和更新归结为一个API可以简化用户对REST服务的使用。用户可以通过PUT动词来同时完成创建和更新一个资源这两种不同的任务。这样的好处在于简化了REST服务所提供的接口,但是反过来也让一个API执行了两种不同的任务,在一定程度上违反了API设计时每个API都需要有明确的意义这一原则。
因此在决定到底使用POST还是PUT来完成资源的创建之前,请考虑上面所列出的三条问题,以确定到底哪个动词更加适合。
除此之外,另外一对类似的动词则是PUT和PATCH。两者之间的不同则在于PUT是对整个资源的更新,而PATCH则是对部分资源的更新。而该动词的局限性则在于对该动词的支持程度。毕竟在某些类库中并没有提供原生的对PATCH动词的支持。
使用标准的状态码
在与REST服务进行交互的时候,用户需要通过服务所返回的信息决定其所发送的请求是否被适当地处理。这部分功能是由REST服务实现时所使用的协议所决定的,与REST架构无关。而在基于HTTP的REST服务中,该功能就由HTTP响应的状态码(Status Code)来完成。因此在设计一个REST服务时,我们需要额外地注意是否返回了正确的状态码。
但是这些预定义的HTTP状态码并不能满足所有的情况。有时候一个REST服务所希望返回的错误信息能够更加精确地描述问题,例如在用户重设密码时,我们需要在用户所输入原密码与系统中所记录的密码不匹配时返回“您所输入的密码有误”这样的消息。在HTTP协议中,我们并没有办法找到一个能够精确地表示该意义的状态码。
因此在通常情况下,REST服务都会在响应中额外地提供一个说明性的负载来告知用户到底产生了什么问题。例如对于上面的重设密码失败的情况,服务端可能会返回如下响应:
1 HTTP/1.1 400 Bad Request
2 Content-Type: application/json
3 Content-Length: xxx
4
5 {
6 "error_id" : "100045",
7 "header" : "Reset password failed",
8 "description" : "The original password is not correct"
9 }
上面的示例响应中主要包含以下的说明性信息:
在该错误中,最关键的当属服务端的响应代码。一个响应代码不仅仅标示了请求是否成功,更有用户该如何操作的含义。例如对于401 Unauthorized响应代码而言,其表示该响应没有提供一个合法的身份凭证,因此需要用户首先执行登陆操作以得到一个合法的身份凭证,然后该资源可能就可以被访问了。而403 Forbidden响应代码则表示当前请求已经提供了一个合法的身份凭证,但是该身份凭证并没有访问该资源的权限,因此使用该身份凭证登陆重新登陆系统等操作并不能解决问题。
因此在返回错误信息之前,软件开发人员首先需要考虑清楚在响应中到底应该使用什么样的响应代码。而正确地选择响应代码则建立在软件开发人员对这些响应代码拥有一个正确的理解的前提下。
当然,要将所有的响应代码完全理解也需要大量的工作,而且REST服务的用户也可能并没有那么多的领域知识来了解所有的响应代码的含义。因此在很多基于HTTP的REST系统中,系统在标示错误时只使用一系列常用的响应代码,如400,401,403,404,405,500,503等。在用户请求被处理时,系统将返回200 OK,表示请求已经被处理。而在处理时发生错误时则尽量使用这些响应代码来表示。如果一个错误较为复杂,那么直接返回400或500,并在响应的负载中提供具体的错误信息。
不得不说的是,这种做法有时显得简单粗暴,尤其是对于一个开放平台而言则更是致命的。当一个第三方厂商为一个开放平台开发一个应用软件,却每次只能得到一个400错误,那么其内部应用逻辑将无法判断到底是哪里出了问题。为了能让用户知道这里产生了错误,该第三方软件只能将开放平台所给出的信息直接显示给用户。但是这些信息实际上是建立在开放平台这个语境下的,因此对于第三方厂商的用户而言,这些信息晦涩难懂,甚至可能一点帮助也没有。
也就是说,到底如何组织这些响应代码需要用户根据所编写的项目决定,尤其是该产品的使用者来决定。在定义一个平台时,尽量使用更多的HTTP响应代码,因为用户极有可能通过该平台编写自己的第三方软件。而在为一个普通的产品定义REST API时,将响应代码定得非常专业可能反而导致易用性的下降。
另外一点需要说明的是,个人不建议使用Wikipedia查找各个状态码的含义,而应该使用RFC所描述的各状态码的定义。 IANA提供了一张各个状态码所对应的RFC协议的列表,从而可以很容易地找到各个状态码所对应的RFC协议以及其所在的章节。该列表的地址为:http://www.iana.org/assignments/http-status-codes/http-status-codes.xhtml
之所以不建议使用Wikipedia的原因主要有两点:
选择适当的表示结构
接下来我们要讲解的就是如何为资源定义一个恰当的表示。
首先需要强调的是,REST并没有规定其服务中需要使用什么格式来表示资源。表示资源时所可以选取的表示形式实际上是由实现REST所使用的协议决定的。而在一个基于HTTP的REST服务中,我们可以使用JSON,也可以使用XML,甚至是自定义的MIME类型来表示资源。这些表现形式常常是等效的。相信读者已经看到,本系列文章会使用JSON来表示这些资源。
一个REST服务常常会同时支持多种客户端。这些客户端可能会使用不同的协议来与服务进行沟通。而且就算是使用相同的协议,不同的客户端所可以接受的负载表示形式也会有所不同。因此客户端需要与REST服务协商在通讯过程中所使用的负载。
客户端和服务端对所使用负载类型的协商通常都按照协议所规定的标准协商过程来完成。例如对于一个基于HTTP的REST服务,我们就需要使用Accept头来标示客户端所可以接受的负载类型:
1 GET /api/categories 2 Host: www.egoods.com 3 Authorization: Basic xxxxxxxxxxxxxxxxxxx 4 Accept: application/json
而在服务端支持的情况下,返回的响应就将使用该MIME类型组织其负载:
1 HTTP/1.1 200 OK 2 Content-Type: application/json 3 Content-Length: xxx
在这里我们再重复一次:REST是一种组织Web服务的架构,其只在架构方面提出了一系列约束。可以说,所有对REST的讲解都已经在前两个章节,即“REST的定义”以及“资源识别”中完成了。而有关客户端和服务端如何进行沟通,为资源定义什么样的URI,使用什么格式的数据进行沟通等讨论都是在阐述如何将REST架构所提出的各种约束和基于HTTP协议的Web服务结合在一起。毕竟在通常情况下,实现一个单纯的技术不难,但是如何将多种技术规范自然地混合在一起,构成一个自然的,成熟稳定的解决方案才是项目开发中的难点。HTTP协议并不是为REST架构所定义的,因此如何用HTTP协议来恰当地描述一个REST服务才是本文所着重介绍的。
负载的自描述性
在前面对REST提出的几个约束的讲解中我们已经提到过,REST系统中所传递的各个消息的负载需要提供足够的用于操作该资源的信息,如如何对资源进行添加,删除以及修改等操作,并可以根据负载中所包含的对其它各资源的引用来访问各个资源。这也对负载的自描述性提出了更高的要求。
首先让我们回头看看egoods电子商务网站对食品分类的描述:
1 {
2 "uri" : "/api/categories/1",
3 "label" : "Food",
4 "items_url" : "/api/items?category=1",
5 "brands" : [
6 {
7 "label" : "友臣",
8 "brand_key" : "32073",
9 "url" : "/api/brands/32073"
10 }, {
11 "label" : "乐事",
12 "brand_key" : "56632",
13 "url" : "/api/brands/56632"
14 }
15 ...
16 ],
17 "hot_searches" : …
18 }
我想读者在看到该响应之后可能就已经明白了很多域的含义。但还是让我们依次对这些域进行讲解。
第一个要讲解的是url域。该域用来标示该资源所对应的URL。可能您会问:既然我们就是从这个URL返回的该资源,那么为什么我们还需要在该资源中保存一个它所对应的URL呢?首先这是因为在统一接口约束中要求每个资源都拥有一个资源标识。在这里我们使用URL作为标识。而另一些基于HTTP的REST系统中,用来作为资源标识的常常是该资源的ID。个人更倾向于使用URL的原因则是:在某些情况下,如对某个资源定时刷新以进行监控的时候,URL可以直接被使用。
接下来是label域。其用来记录用于展示给用户的分类名。
items_url域则用来表示取得属于该分类物品列表的URL。注意这里我使用了后缀_url以明确标明其是一个URL,需要通过跳转来取得实际的数据。
下一个域brands则用来表示属于该分类的著名商品品牌。这里我们使用了一个数组,而数组中的每个元素都表示了一个品牌。每个品牌的表示都包含了一个展示给用户的label,在搜索时所使用的键,以及该品牌所对应的url。您可能会怀疑为什么我们仅仅提供了这么少的域。这是因为他们仅仅是对这个品牌的引用,而并非是把该资源的详细信息都包含进来了的缘故。在用户希望查看该品牌的详细信息的时候,他需要向该品牌引用中所标明的品牌的URL发送一个GET请求。
而由于hot_searches域的组成及使用基本上与brands域类似,因此这里不再赘述。
在大致地了解了食品分类的JSON表示中各个域的含义后,我们就将开始讲解如何自行定义资源的JSON表示。对于一个简单的,不包含任何子资源以及对其它资源的引用的资源,我们只需要通过一个包含简单属性的JSON来表示它。例如对于一个品牌,我们可能仅仅提供了一系列描述性信息:品牌的名称,以及对品牌的简单描述。那么它所对应的JSON表示可以表示为:
1 {
2 "uri" : "/api/brands/32059",
3 "label" : "Dole",
4 "description" : "An American-based agricultural multinational corporation."
5 }
而在另一个资源中,可能包含了对其它资源的引用。在这种情况下,我们就需要在表示对其它资源进行引用的域中通过URL来标明被引用资源的位置。例如一件Dole果汁中,可能就需要包含对品牌Dole的引用:
1 {
2 "uri" : "/api/items/1438299",
3 "label" : "Dole Grape Juice",
4 "price" : "$3.99",
5 "brand" : {
6 "label" : "Dole"
7 "uri" : "/api/brands/32059"
8 }
9 ……
10 }
在上面的Dole果汁的表示中,我们可以看到它的brand域就是对品牌的引用。该引用中包含了该品牌的品牌名称以及一个指向该品牌的URL。
在一个基于HTTP的REST系统中,我们常常在资源的引用中包含一定量的描述信息。这主要因为两点:
当然,如果需要在展示Dole果汁的页面中需要Dole这个品牌的完整信息,我们也可以将它直接嵌到Dole果汁的表示中:
1 {
2 "uri" : "/api/items/1438299",
3 "label" : "Dole Grape Juice",
4 "price" : "$3.99",
5 "brand" : {
6 "uri" : "/api/brands/32059",
7 "label" : "Dole",
8 "description" : "An American-based agricultural multinational corporation."
9 }
10 ……
11 }
当然,如果一个资源的表示太过复杂,而且有些属性实际上是相互关联的,那么我们也可以通过一个属性将它们归结在一起:
1 {
2 "uri" : "/api/items/1438299",
3 "label" : "Dole Grape Juice",
4 "price" : "$3.99",
5 "brand" : {
6 "uri" : "/api/brands/32059",
7 "label" : "Dole",
8 "description" : "An American-based agricultural multinational corporation."
9 }
10 "nutrient component" : {
11 "sugar" : "14.5",
12 "protein" : "0.3",
13 "fat" : "0.1"
14 }
15 ……
16 }
在上面的Dole果汁的表示中,我们使用域nutrient component来表示所有的营养成分,而该域内部的各个子域则用来表示一系列相关的营养成分所占比例。
另外,在不同的情况下,我们还可能对同一个资源提供不同的表现形式。例如在一个资源极为复杂,其JSON表示甚至可以达到几百K的时候,我们可以为该资源提供一个简化版本,以在非必要的情况下减少传输的数据量。
例如在egoods中,我们会将某些物美价廉的商品置于它的首页上,以吸引用户购买。在用户将鼠标移动到某个商品上并停留一段时间时,我们会为用户展示一个Tooltip,并在该Tooltip中展示该商品的一部分信息。在这种情况下,向服务端请求该商品的所有信息以展示Tooltip便显得有些效率低下了。
有时候,一个资源可能并不支持特定用户执行某个操作。例如一个管理员所创建的资源可能对普通用户只读。在这种情况下,我们需要禁止普通用户对该资源的修改和删除。为了能明确地告知用户他所具有的权限,我们需要一个能显式地标示用户可以在一个资源上所执行操作的组成。在REST响应中,这种组成被称为Hypermedia Controls。例如对于一个普通用户,其从egoods中所返回的分类列表将如下所示:
1 HTTP/1.1 200 OK
2 Content-Type: application/json
3 Content-Length: xxx
4
5 [
6 {
7 "label" : "Food",
8 "uri" : "/api/categories/1",
9 "actions" : ["GET"]
10 }, {
11 "label" : "Clothes",
12 "uri" : "/api/categories/2",
13 "actions" : ["GET"]
14 }
15 ...
16 {
17 "label" : "Electronics",
18 "uri" : "/api/categories/25",
19 "actions" : ["GET"]
20 }
21 ]
可以看到,在上面的分类列表中,我们通过actions域显式地标示了用户可以在各个类别上所能执行的操作。而对于管理员,其还可以执行修改,删除等操作:
1 HTTP/1.1 200 OK
2 Content-Type: application/json
3 Content-Length: xxx
4
5 [
6 {
7 "label" : "Food",
8 "uri" : "/api/categories/1",
9 "actions" : ["GET", "PUT", "DELETE"]
10 }, {
11 "label" : "Clothes",
12 "uri" : "/api/categories/2",
13 "actions" : ["GET", "PUT", "DELETE"]
14 }
15 ...
16 {
17 "label" : "Electronics",
18 "uri" : "/api/categories/25",
19 "actions" : ["GET", "PUT", "DELETE"]
20 }
21 ]
而在一系列较为著名的REST系统中,如Sun Cloud API,其更是通过Hypermedia Controls定义了除CRUD之外的动词。如对于一个虚拟机,其在运行状态下可以执行停止命令,而在停止状态下可以执行启动命令:
1 {
2 "vms" : [
3 {
4 "id" : "1",
5 ......
6 "status" : "stopped",
7 "links" : [
8 {
9 "rel" : "start",
10 "method" : "post",
11 "uri" : "vms/1?op=start"
12 }
13 ]
14 }, {
15 "id" : "2",
16 ......
17 "status" : "started",
18 "links" : [
19 {
20 "rel" : "stop",
21 "method" : "post",
22 "uri" : "vms/2?op=stop"
23 }
24 ]
25 }
26 ]
27 }
但是一个常见的观点是:如果一个资源需要除CRUD之外的额外的动词,那么这种需求常常表示我们对于某个资源的定义并不是十分合理。因此在遇到这种情况时,软件开发人员首先需要考虑为资源添加额外的动词是否合适。
无状态约束
在Roy Fielding的论文中,其为REST添加了一个无状态约束:
We next add a constraint to the client-server interaction: communication must be stateless in nature … such that each request from client to server must contain all of the information necessary to understand the request, and cannot take advantage of any stored context on the server. Session state is therefore kept entirely on the client.
从上面的陈述中可以看到,在一个REST系统中,用户的状态会随着请求在客户端和服务端之间来回传递。这也便是REST这个缩写中ST(State Transfer)的来历。
为REST系统添加这个约束有什么好处呢?主要还是基于集群扩展性的考虑。如果REST服务中记录了用户相关的状态,那么在集群中,这些用户相关的状态就需要及时地在集群中的各个服务器之间同步。对用户状态的同步将会是一个非常棘手的问题:当一个用户的相关状态在一个服务器上发生了更改,那么在什么时候,什么情况下对这些状态进行同步?如果该状态同步是同步进行的,那么同时刷新多个服务器上的用户状态将导致对用户请求的处理变得异常缓慢。如果该同步是异步的,那么用户在发送下一个请求时,其它服务器将可能由于用户状态不同步的原因无法正确地处理用户的请求。除此之外,如果集群进行了不停机的横向扩展,那么用户状态的同步需要如何完成?这些实际上都是非常难以处理的问题。
但是现有的很多较为流行的技术及规范实际上都没有限制用户的请求是无状态的。相信您知道,一个技术或规范实际上都拥有一个生态圈。在该生态圈之内的各技术之间可以较好地契合在一起。尤其是,有些技术实际上就会以该生态圈中的核心技术或规范所建立的假设之上来实现自己的功能。如果希望禁止该假设,那么让某些技术工作起来就是非常困难的事情了。
就以搭建基于HTTP的REST服务为例。在HTTP中,一个重要的功能就是Cookie和Session的使用(RFC6265)。该功能会在服务器里保留一个状态。因此在一个基于HTTP的REST系统中,我们常常需要避免使用这些在服务器里面保留状态的技术。但是某些技术,如用户的登陆,实际上常常需要在服务器中添加一个状态。
所以在stackoverflow中,我们常常会看到有人问:我现在使用了这样一种解决方案。这样实现是不是RESTful?此时一些人就会说,这不是RESTful。但是pure RESTful和almost RESTful之间的区别主要还是在于一个是理论,一个是工程。在工程中,轻微地违反了一个准则并不一定代表这个解决方案一无是处。而是要看遵守该准则和轻微地违反了该准则之后工作量的大小以及后期的维护成本:之所以提出一系列准则,那是因为遵守该准则拥有一定的好处。如果对该准则的轻微违反可以减少大量的工作量,而且遵守准则的好处并没有消失,或者是通过另一样技术可以快速地重新获得该好处,那么对准则的轻微违反是值得的。
Authentication
其实在上一节中,我们已经提出了无状态约束给REST实现带来的麻烦:用户的状态是需要全部保存在客户端的。当用户需要执行某个操作的时候,其需要将所有的执行该请求所需要的信息添加到请求中。该请求将可能被REST服务集群中的任意服务器处理,而不需要担心该服务器中是否存有用户相关的状态。
但是在现有的各种基于HTTP的Web服务中,我们常常使用会话来管理用户状态,至少是用户的登陆状态。因此,REST系统的无状态约束实际上并不是一个对传统用户登录功能友好的约束:在传统登陆过程中,其本身就是通过用户所提供的用户名和密码等在服务端创建一个用户的登陆状态,而REST的无状态约束为了横向扩展性却不想要这种状态。而这也就是为基于HTTP的REST服务添加身份验证功能的困难之处。
为了解决该问题,最为经典也最符合REST规范的实现是在每次发送请求的时候都将用户的用户名和密码都发送给服务器。而服务器将根据请求中的用户名和密码调用登陆服务,以从该服务中得到用户所对应的Identity和其所具有的权限。接下来,在REST服务中根据用户的权限来访问资源。
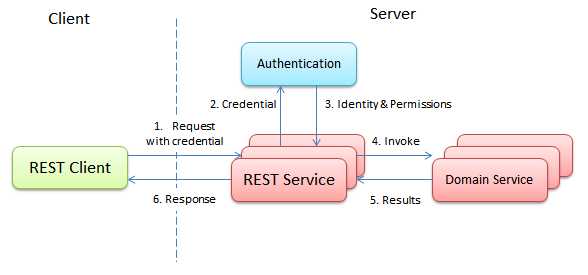
这里有一个问题就是登陆的性能。随着系统当前的加密算法越来越复杂,登陆已经不再是一个轻量级的操作。因此用户所发送的每次请求都要求一次登陆对于整个系统而言就是一个巨大的瓶颈。
在当前,解决该问题的方法主要是一个独立的缓存系统,如整个集群唯一的登陆服务器。但是缓存系统本身所存储的仍然是用户的登陆状态。因此该解决方案将仍然轻微地违反了REST的无状态约束。
还有一个类似的方法是通过添加一个代理来完成的。该代理会完成用户的登陆并获得该用户所拥有的权限。接下来,该代理会将与状态有关的信息从请求中删除,并添加用户的权限信息。在经过了这种处理之后,这些请求就可以转发到其后的各个服务器上了。转发目的地所在的服务器则会假设所有传入的请求都是合法的并直接对这些请求进行处理。
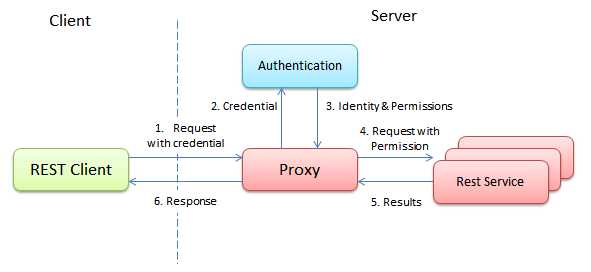
可以看到,无论是一个独立的登陆服务器还是为整个集群添加一个代理,系统中都将有一个地方保留了用户的登陆状态。这实际上和在集群中对会话集中进行管理并没有什么不同。也就是说,我们所尝试的通过禁止使用会话来达成完全的无状态并不现实。因此在一个基于HTTP的REST服务中,为登陆功能使用集中管理的会话是合理的。
既然我们放松了对REST系统的无状态约束,那么一个REST系统所可以使用的登陆机制将主要分为以下两种:
1. 基于HTTPS的Basic Access Authentication
其好处是其易于实现,而且主流的浏览器都提供了对该功能的支持。但是由于登陆窗口都是由浏览器所提供的,因此其与产品外观有很大不同。除此之外,浏览器都没有提供登出的功能,也没有提供找回密码等功能。
2. 基于Cookie及Session的管理
在使用Cookie来管理用户的注册状态的时候,其实际上就是将服务端所返回的Cookie在每次发送请求的时候添加到请求中。虽然说这个Cookie并非存储了用户应用的状态,但是其实际存储了用户的登陆状态。因此客户端的角度来讲,由服务端管理的Session并不符合REST所倡导的无状态的要求。
可以说,上面的两种方法各有优劣。可能第二种方法从客户端的角度看来并不是RESTful的,但是其优势则在于很多类库都直接提供了对该功能的支持,从而简化了会话管理服务器的实现。
在这里顺便提一句,如果项目足够大,将一些SSO产品集成到服务中也是不错的选择。
版本管理
在前面已经提到过,一个REST系统为资源所抽象出的URI实际上是对用户的一种承诺。但反过来说,软件开发人员也很难预知一个资源的各方面特征如何在未来发生变化,从而提供一个永远不变的URI。
在一个REST系统逐渐发展的过程中,新的属性,新的资源将逐渐被添加到该系统中。在这些更改过程中,资源的URI,访问资源的动词,响应中的Status Code将不能发生变化。此时软件开发人员所做的工作就是在现有系统上维护REST API的后向兼容性。
当资源发生了过多的变化,原有的URI设计已经很难兼容现有资源应有的定义时,软件开发人员就需要考虑是否应该提供一个新版本的REST API。那么我们该如何对资源的版本进行管理呢?
首先要考虑的就是,新API的版本信息是否应当包含在资源的URI中。这在各著名论坛中仍然是一个争议较大的话题。一种观点认为在不同版本的API中,一个资源拥有不同的地址在一定程度上违反了HATEOAS:URI只是用来指定一个资源所在的位置,而不是该资源如何被抽象。如果一个资源由不同的URI标示其不同的表现形式,那么用户将无法通过一个响应中所标示的URI得到其它URI所指向的表示形式。而且在URI中添加了有关版本的信息也就标示着其可能会随着时间的推移发生变化。
一种使用独立URI的方法是基于Accept头。在一个请求中,我们常常标明了Accept头,以标示客户端希望得到的表现形式。在该头中,用户可以添加所请求的资源的版本信息:
1 GET /api/categories/1 2 Host: www.egoods.com 3 Authorization: Basic xxxxxxxxxxxxxxxxxxx 4 Accept: application/vnd.ambergarden.egoods-v3+json
而在接收到该请求之后,服务端将返回该资源的第三个版本:
1 HTTP/1.1 200 OK
2 Content-Type: application/vnd.ambergarden.egoods-v3+json
3 Content-Length: xxx
4
5 {
6 "uri" : "/api/categories/1",
7 "label" : "Food",
8 ……
9 }
可以看到,该方法是非常严格地遵守REST系统所提出的约束的。但其也并不是没有缺点:添加一个自定义MIME类型(Custom MIME Type)也是一个很麻烦的流程,而且在很多现有技术中都没有很好地支持它,如HTML5中的Form。因此这种方案的缺点是对REST API用户并不那么友好。
除此之外,另一种基于重定向的解决方案也被提出。该方案允许一个REST系统提供多个版本的API,并在URI中标明版本号:
1 /api/v2/categories 2 /api/v1/categories
这样用户可以选择使用特定版本的REST API来实现客户端功能。由于其使用固定版本的API,因此并不存在着一个资源有多种表示,进而违反了HATEOAS约束的问题。
在REST系统的API随时间逐渐发展出众多版本的时候,系统对API的维护也将成为一个较大的问题。此时就需要逐渐退役一些年代久远的API 版本。对这些版本的退役主要分为两步:首先将其标为过期的,但是还在一段时间内支持。在这种情况下,对这些已经过期的API的访问将得到3XX响应,如301 Moved Permanently,以通知用户该URI所标示的资源需要使用新版本的URI进行访问。而再经过一段时间后,则将过期的REST API标记为废弃的。此时用户在访问这些URI时将返回4XX响应,如410 Gone。
接下来,该REST系统还可以提供一个通用的REST API接口,并与最新版本的API保持一致:
1 /api/categories
这样用户还可以选择一直使用最新版本的API,只是同时也需要一直对其进行维护,以保持与最新版本API的兼容性。在REST系统的API随着时间的推移逐渐发生变化的时候,该客户端也需要逐渐更新自身的功能。
但是该方法有一个问题:由通用URI所辨识出的各个资源需要是稳定的,不能在一定时间之后被废弃,否则会给用户带来非常大的维护性的麻烦。举例来说,假设客户端逻辑添加了一系列操作分类的功能。当REST系统决定不再采用分类作为商品归类的标准,那么客户端逻辑中与分类相关的各个功能都需要进行大幅度地修改。过于频繁的这种改动很容易导致用户对该系统所提供的API失去维护的信心。因此在抽象资源时一定要努力地将各个资源的边界辨识清楚。虽然说这听起来很吓人,但是在经过仔细考虑后这种情况还是较为容易避免的。
但是反过来说,理论常常与实际有些脱钩,更何况REST是在2000年左右提出的,无法做到能够预见到十余年后所使用的各项技术。因此在尽量符合REST所提出的各约束上提供一个最直观的,具有最高易用性的API才是王道。无限制地提供后向兼容性是一个非常困难,成本非常高的事情。因此在版本管理这一方面上来说,我们也需要尽量兼顾项目需求和完全遵从理论这两者之间的平衡。
而在同一个版本之中,我们则需要保证API的后向兼容性。也就是说,在添加新的资源以及为资源添加新的属性的时候,原有的对资源进行操作的API也应该是工作的。
对于一个基于HTTP的REST服务而言,软件开发人员需要遵守如下的守则以保持API的后向兼容性:
而前向兼容性则显得没有那么重要了。REST服务的前向兼容性要求现有的服务兼容未来版本服务的客户端。但是由于服务提供商所提供的服务常常是最新版本,因此对前向兼容性有要求的情况很少出现。另外一点是,为一个服务提供前向兼容性其实并不那么容易。因为这要求软件开发人员对产品的未来方向进行非常多的假设,而且这些假设不能有错误。反过来,这种对服务的前向兼容性的要求主要由客户端自身通过保持后向兼容性来完成。
性能
接下来我们就来简单地说说基于HTTP的REST服务中的性能问题。在基于HTTP的REST服务中,性能提升主要分为两个方面:REST架构本身在提高性能方面做出的努力,以及基于HTTP协议的优化。
首先要讨论的就是对登陆性能的优化。在前面我们已经介绍过,在一个基于HTTP的REST服务中,每次都将用户的用户名和密码发送到服务端并由服务端验证这些信息是否合法是一个非常消耗资源的流程。因此我们常常需要在登陆服务中使用一个缓存,或者是使用第三方单点登陆(SSO)类库。
除此之外,软件开发人员还可以通过为同一个资源提供不同的表现形式来减少在网络上传输的数据量,从而提高REST服务的性能。
而在集群内部服务之间,我们则可以不再使用JSON,XML等这种用户可以读懂的负载格式,而是使用二进制格式。这样可以大大地减少内部网络所需要传输的数据量。这在内部网络交换数据频繁并且所传输的数据量巨大时较为有效。
接下来就是REST系统的横向扩展。在REST的无状态约束的支持下,我们可以很容易地向REST系统中添加一个新的服务器。
除了这些和REST架构本身相关的性能提升之外,我们还可以在如何更高效地使用HTTP协议上努力。一个最常见的方法就是使用条件请求(Conditional Request)。简单地说,我们可以使用如下的HTTP头来有条件地存取资源:
当然,这里所提到的一系列性能优化方案实际上仅仅是比较常见的,与基于HTTP的REST服务关联较大的方案。只是顾虑到过多地陈述和REST关联不大的话题一方面显得比较没有效率,另一方面也是因为通过写另一个系列博客可以将问题陈述得更加清楚,因此在这里我们将不再继续讨论性能相关的话题。
相关资源
AtomPub:http://atomenabled.org/。其是最为广泛讨论的并借鉴的RESTful服务。其由众多HTTP和REST专家所编写,甚至包括Roy Fielding本人也参与于其中
Roy Fielding的REST论文:http://www.ics.uci.edu/~fielding/pubs/dissertation/top.htm
Roy Fielding的个人网站:http://roy.gbiv.com/untangled/。
RFC列表:http://www.ietf.org/rfc/
转载请注明原文地址并标明转载:http://www.cnblogs.com/loveis715/p/4669091.html
商业转载请事先与我联系:silverfox715@sina.com
标签:
原文地址:http://www.cnblogs.com/Leo_wl/p/4672012.html