标签:

在LinkedIn,我们一直在评估最好的开发框架和工具来开发伟大的产品。11年的历史中,我们使用过很多前端web框架-如Grails、Frontier(LinkedIn内部的web框架),最近是:Play!我们喜欢Play,并热情地在公司内部推行起来。于是我们用Play进行了整合和扩展。现在我们正在评估哪个构建系统(build system,下同)更好用。
这篇文章介绍了用在Play中用Gradle来支持开发,及Gradle的目前状态和它的初步特性的演化。我们希望Play社区提供更多反馈以帮助Gradle类软件的开发。能够给Sbt和Gradle开发Play应用将提供更多的自由度和多样性。
在LinkedIn,我们用代码仓库管理公共API和服务,每个这种仓库我们给它取了个名叫 Multiproduct,每个Multiproduct通过独立的Ivy来组织,默认的名称是com.linedin。LinkedIn的部分代码已经开源了,如databus。
用Multiproducts来组织代码的结果是,它们都是多工程的构结构,每个Multiproduct有10个或100个工程,同时每个工程又有多个 构件(artifacts,下同)。
在LinkedIn,我们的Play应用在classpath路径下有超过500个jar包,这意味着全依赖解析的话需要处理至少500个节点。但依赖解析重度依赖于冲突解决的规则(导致效率低)。我们不在构件(如jar)层解析版本,而是在Multiproduct(或Ivy组织)层处理,这样可以保证同一个Multiproduct内全部构件版本是一致的。
例如,工具类util Multiproduct,我们有3个不同的模块,com.linkedin.util:foo, com.linkedin.util:bar, com.linkedin.util:baz。每一个模块可能有一个或多个构件,一般的冲突解决办法 可保证所有模块只有一个版本,但不同模块间的版本(本例中的"com.linkedin.tuil:foo", "com.linkedin.util:bar", and "com.linkedin.util, baz")仍可能不同。我们自定义依赖处理器将确保同一个Multiproduct中的所有构件是同一个版本。
Play默认的构建工具是SBT,Play与SBT在技术上是解耦了,但底层仍有很多未分离。当我们开始开发Play应用时,很快就遇到了SBT扩展性方面的挑战,而且很依赖于Apache Ivy库,某个应用的依赖解析需要5-10分钟,一个框架工程呢,就要花30分钟以上。
过去一年,LinkedIn跟Typesafe合作来提升SBT的扩展性,现在还在继续,然而,同时,我们感觉到评估下其它的构建工具也是值得的。
LinkedIn已经使用Gradle有3.5年了,到处都有gradle的影子,从小项目到单个Multi-product构建了近4000个工程,而且2015年的gradle还带了许多激动人心的新特性。

除了以上,我们相信整合两者对双方都很有价值,跟Gradleware 一起我们开始研究如果让它成为现实。2015年上半年,我们将注重整合的实现和测试,已经完成 3个里程碑 了。
让Gradle与Play的插上电,开发者可以用gradle构建一个具有Play全部特性的应用。
特性包括:
编译Java和Scala源码
编译路由
编译模板
编译资源/配置文件
支持CoffeeScript, LESS/CSS, JavaScript
使用这个构建管道,Play应用可以用 gradle run 或 gradle start 启动,或用 gradle stage 或 gradle dist 来发布。
有了这个能力我们就可以全面的测试Play的构建系统的性能和可扩展性了。
提示:这个里程碑里 持续模式(continuous mode) 和 热加载(hot reload) 不支持。
开发应用时能够热加载将是最令人愉快的Play特性。
自动化之前手工打包处理是一个伟大的主意,我们热切希望能加到gradle里。里程碑2将介绍Gradle的“观察者”模式,这跟SBT的持续模式(continuous mode)相同:gradle --watch run。
Play也可以当浏览器刷新时自动重新构建,这是通过Play的BuildLink接口实现的,这个里程碑将包含这个特性。
如果你熟悉Play可能已经注意到了缺失了一个严重的特性:Scala的交互功能 REPL!别急....这是里程碑3的一部分,将允许你在控制台与类(classes)进行交互。
还有文档,跟Specs2 整合了, 还有Scala的代码也优雅的集成了。为了让这些一起启动起,你需要一个适当的Gradle基础平台,就像你之前用activator一样。
想了解更多?可以参考这里。
该里程碑的特性已经完成了,你可以下载最新版本尝试下。下载包里有二进制文件、源代码文件和例子工程。解压缩后加“bin”路径加到你的环境变量。
Play的例子在 “samples/play” 目录。
基本的
基本例子 build.gradle 文件演示了Play插件声明及仓库需求配置,依赖块展示了如果定义第3方类库,‘play‘ 配置提供了统和运行依赖,‘playTest‘ 提供了测试时的依赖定义。
高级的
高级例子 build.gradle 展示了如果配置成 Play/Scala 版本。
Multiproduct:
这是标准的Gradle multiproject 构建配置,根目录包含了Play主应用,3个子模块在modules目录下,admin和user子模块在在各自文件夹里,utile是一个java 类库。settings.gradle 文件连接了3个子工程,主工程build.gradle 描述了3个子模块各自的依赖。
你可以尝试执行以下任务:
gradle :assemble :构建 jar 和 assets
gradle :runPlayBinary : 构建和运行应用在开发者模式
gradle :check : 执行测试用例
gradle :stage : 构建和发布 image, 与启动脚本一起
我们比较了Gradle和Activator(sbt)两个方式的构建时间。
用来比较的工程
Basic - 一个简单的Play工程, play-scala模板设为activator.
Multiproject - 构建在gradle的multiproject的Play例子工程,a multiproject build based on the gradle’s,例3也是util的子工程.
测试方法
所有依赖库已经下载到本地gradle和ivy缓存里.
测试任务"dist "将生成最终发布tar包,将测试整个构建和发布流程,同时围绕着依赖解析、编译、打包执行。
Gradle是串行执行,在 vanilla sbt 使用时 configure-on-demand 和 daemon 启用 .
Clean-build: 展示了从一个干净状态的完整打包处理流程。
No change: 没作任务改变返回 “dist” .用来测试构建配置和更新有多快。
Incremental:改了一行让根Play工程依赖了java或scale子工程来模拟典型的流程。
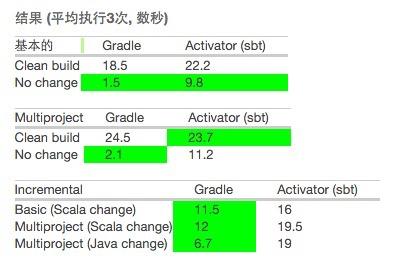
从以上可以看出,Gradle构建除了1个差一些外都胜出了,不管是没有或小修改都很好,这正是我们期望的。http://app.csq.im
基本依赖解析性能评估
我们对依赖解析的性能更加感觉兴趣,所以我们只想比较解析所有依赖要花多久,对 activator/sbt

备注
1.Gradle的“依赖”解析任务不仅仅是解决依赖问题,实际上还打印出了4个子工程的依赖树
2.Gradle的依赖解析处理时间是通过内置的分析工具报告的
从上面的结果可以轻易的得出结论 Gradle的原生依赖解析引擎快过activator/sbt使用的 Ivy引擎 10倍以上。那就是我们为何将java工程构建在Gradle之上的原因。
我们仍努力将之前需要5-10分钟的的activator/sbt项目用Gradle进行重构,我们期望更好的结果!
标签:
原文地址:http://my.oschina.net/u/1263162/blog/483544