标签:
TF-IDF:Term Frequency-Inverse Document Frequency(词频-逆文档频度):主要用来估计一个词在一个文档中的重要程度。
符号说明:
文档集:D={d1,d2,d3,..,dn}
nw,d:词w在文档d中出现的次数
{wd}:文档d中的所有词的集合
nw:包含词w的文档数目
1、词频 TF的计算公式如下:

2、逆文档频率IDF计算公式:

3、综合1和2,得到TF-IDF:

//w关于d的词频越大,包含w的文档数越少,则词w与文档d的TF-IDF值就越大。TF-IDF值越大,说明词w与文档d的相关性越高。
可以将IDF看做是词频TF的权值,当一个词在越多的文档中出现时,词的权重就越小。比如像“的,是,等”等词基本在每个文档都有出现(这时n=nw,)则其值IDF为0。故而达到了减小其权值的目的。
一些扩展:
1、获取一个文档的关键字的方法:
1)首先提取出文档中所有的词;
2)然后将每个词都计算与当前文档的TF-IDF值
3)再将该值从大到小排序;
4)最后取出前k个TF-IDF值最大的词即为关键字。
2、从一组文档中获取与关键字w最相关的文档
计算关键字w与每个文档的TF-IDF值,其值最大的即为最相关的文档。
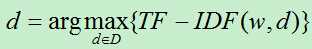
假如有k个词w1,w2,..,wk个词,计算与这K个词最相关的文档
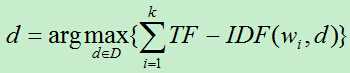
3、计算两个文档之间的相似度
首先将两个文档d1,d2中的词求并集,得到一个新的词集合W,然后将文档d1,d2与词集合W中的每一个词就算相似度,最后将两个文档的相似度计算余弦距离,即得到两个文档的相似度。
具体过程如下:
1)计算文档d1,d2两个文档的词的并集,
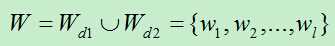
2)分别计算W中每个词与d1,d2之间的相似度。得到V1,V2。
3)使用余弦公式,计算V1,V2之间的余弦距离:
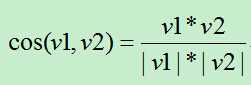
余弦距离越大,则两个文档的相似度越高,反之越低。
参考文献:
[1] http://blog.csdn.net/itplus/article/details/20958185
[2] http://www.cnblogs.com/biyeymyhjob/archive/2012/07/17/2595249.html
标签:
原文地址:http://www.cnblogs.com/liuwu265/p/4684446.html